Hello,
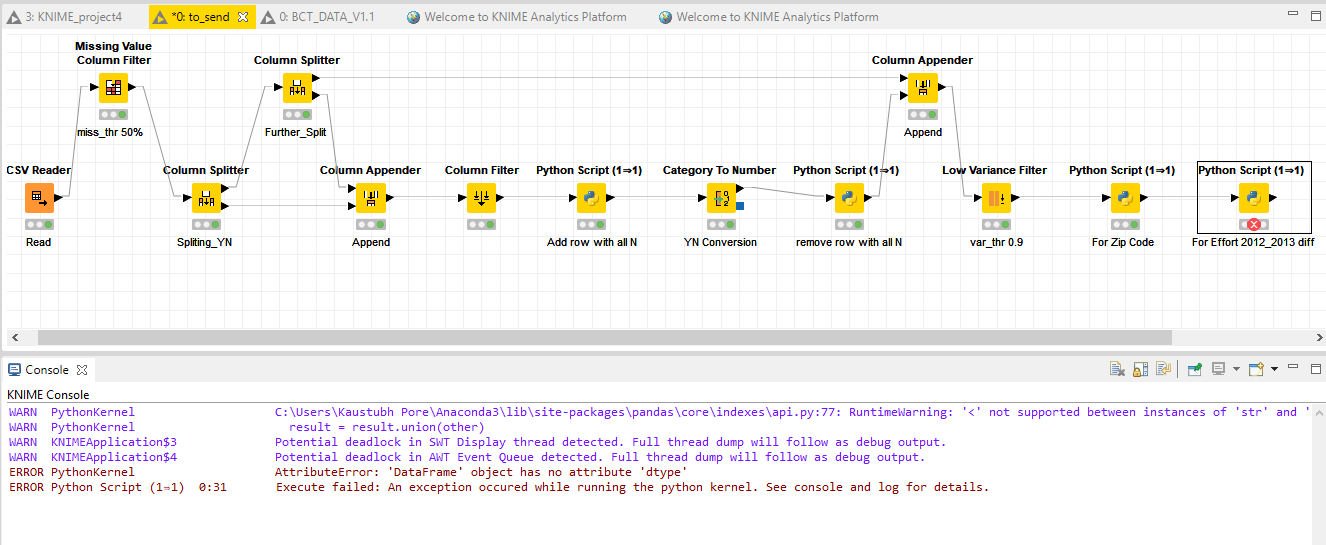
I am not able to run the script in the python(1=>1) node. The same script is working in IDE like spyder.
Below is my code and attached is screenshot of the workflow and the error:
import re
import pandas as pd
output_table = input_table.copy()
head = list(output_table)
reg_2013 = re.compile("(Effort_2013).")
reg_2012 = re.compile("(Effort_2012).")
effort_2013 = list(filter(reg_2013.match, head))
effort_2012 = list(filter(reg_2012.match, head))
colname =
data =
for element in effort_2012:
temp = ‘’
temp = element.replace(‘2012’,’\d+’)
for value in effort_2013:
if re.match(temp, value):
colname.insert(len(colname), ‘diff_2012_2013_’ + element.replace(‘2012_’,’’))
data.insert(len(data), list(output_table[element] - output_table[value]))
df = pd.DataFrame(data)
df = df.transpose()
df.columns = colname
output_table = pd.concat([output_table, df], axis=1)
No. Already tried. Didn’t work for me.
@christian.dietz Request you to please suggest changes.
Hi saurabhpore444,
can you please upload your knime.log file and/or the workflow that produces the error? That would help reproducing the error.
Marcel
Please find attached workflow.
to_send_1.knwf (51.8 KB)
Thanks! Is there also some input data you could share? “Consolidated_BCP_file.csv” is missing, unfortunately.
Hello,
Uploaded .xlsx file.
2017_Forbes.xlsx (2.9 MB)
It looks like output_table is a nested data frame, i.e. contains at least one column which itself is a DataFrame (for the file you uploaded it’s column “diff_2012_2013_Effort_Trave”). This is not supported because KNIME is largely restricted to flat tables.
Hello,
Actually, I am doing the same thing. I want to merge two data frames and assign it to a output_table.
I tried doing
df_new = pd.concat([output_table, df], axis=1)
output_table = df_new
still the same issue. Kindly suggest the workaround.