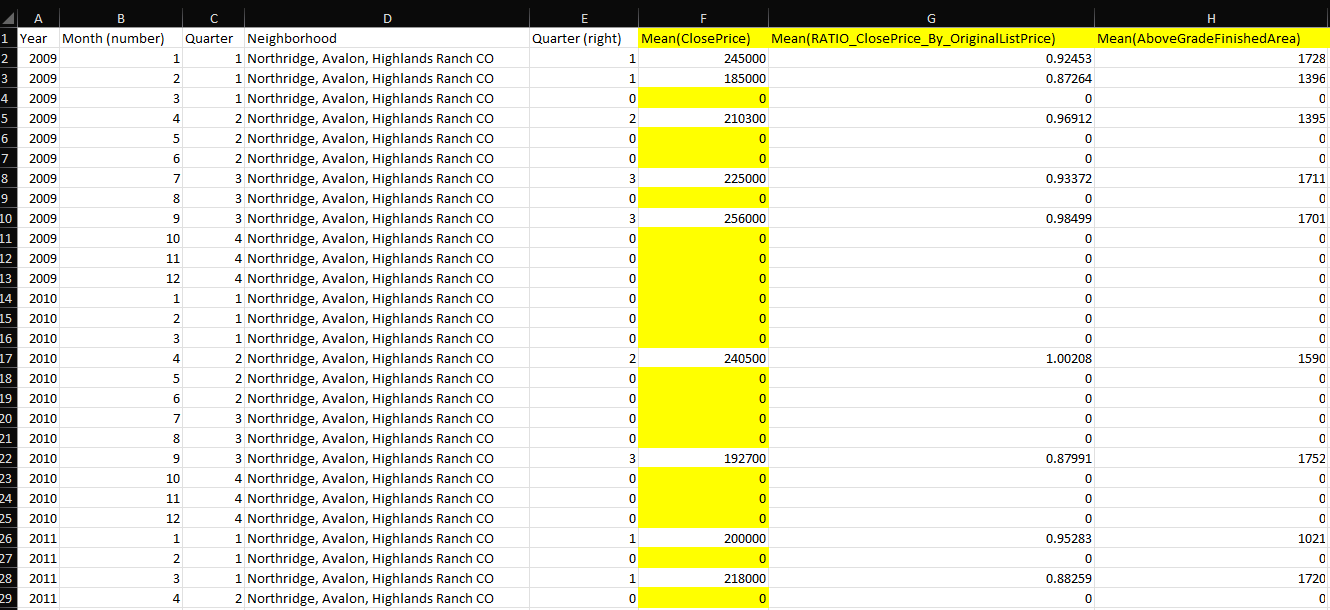
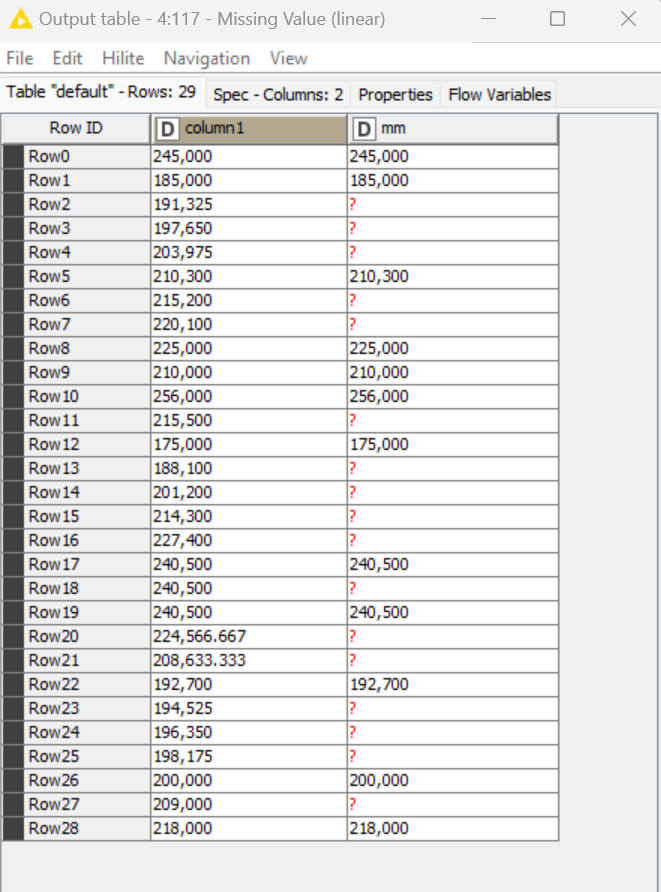
As you can see, the range of months of missing data varies greatly (zeros are there simply because I used the Missing Value node, which can just as easily be converted back to “?”).
I can’t use the pre-formatted functions in the Missing Value node, such as Mean, Median, or Moving Average, as the range of years’ data and sporadic zeros would create huge errors. Next Value or Previous Value won’t work due to the unevenly placed zeros.
I’m thinking that perhaps the Rule Engine or Math Formula nodes might be able to help me “average” the previous non-zero value with the next available non-zero value, but have not come up with a way to automatically seek the non-zero value in each direction since there may be 1-6 or more zeros clustered in the column.
Hi,
What you can also do is impute missing values using a regression tree or linear regression. You split your data into those rows with missing and those without missing mean ClosePrice. Then you train your model on the table where the values exist to predict the ClosePrice. In the other table, you remove the Mean(ClosePrice) column using a Column Filter (its only missing values anyways) and then let the predictor node (for regression tree or linear regression) recreate it with predicted values. This might work better, especially since your averaging might be out of whack when you have a missing value where the previous or next non-missing value is in a different neighborhood.
To make sure the model you train is any good, you could perform a simple cross validation (https://www.youtube.com/watch?v=kQXxf_VX1ww) and check how much the values are off before you actually employ the model for imputation.
Kind regards,
Alexander
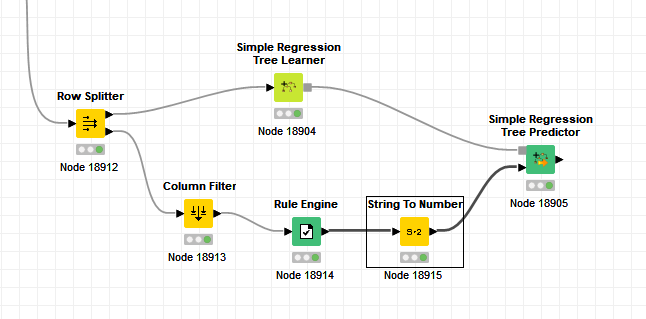
Using the Row Splitter, I sent the populated “mean close price” data to the Simple Regression Tree Learner and the dates missing MCP data to the Column Filter and then the Simple Regression Tree Predictor. I included the “Year”, “Month”, and “Quarter” columns and removed the “Mean Close Price” and all other columns. These are however, the columns I did send to the Learner with the populated data.
However, I get a Console message from the Predictor node “Required data column “Mean(ClosePrice)” does not exist in table” when there is no MCP column. The Predictor node will not execute.
So, I reset the Column Filter to allow the MCP column, used the Rule Engine to set the MCP column to “blank” for each of the prior months with missing data, converted the Rule Engine output column from string to integer using the String to Number node, and was then able to run the Regression Tree Predictor for output.
Does this all seem fairly appropriate relative to what you were thinking, or did I go off-course?
I will start checking the quality of the output a bit later.
BTW, I ran just one neighborhood. So I will have to figure out how to loop the full series of 86 neighborhoods to each run independently and accumulate the results.
Hi,
Did you select the Mean(ClosePrice) column as target column in the Simple Regression Learner? And it should be excluded automatically, but can you make sure it is also not in the list of feature variables in the same node? Then the predictor should definitely not need the Mean(ClosePrice) to be included in the table.
For doing this for multiple neighborhoods, you can use the Group Loop Start node with a Loop End and your imputation flow in-between.
Kind regards,
Alexander
Hi @Daniel_Weikert,
When there are multiple missing values in a row, linear interpolation will assign different values to each like so:
1, ?, ?, 4 → 1, 2, 3, 4
But the data does not seem to be sorted in a fashion where this makes sense. It is not a time series after all.
Kind regards,
Alexander
@AlexanderFillbrunn, yes you are correct, I must have done something wrong the first time, so recreated the regression series nodes and bypassed the two steps I had added earlier.
I am moving on to testing the quality, then the loops.
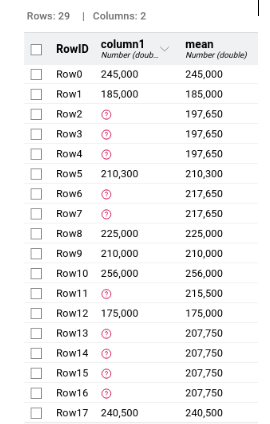
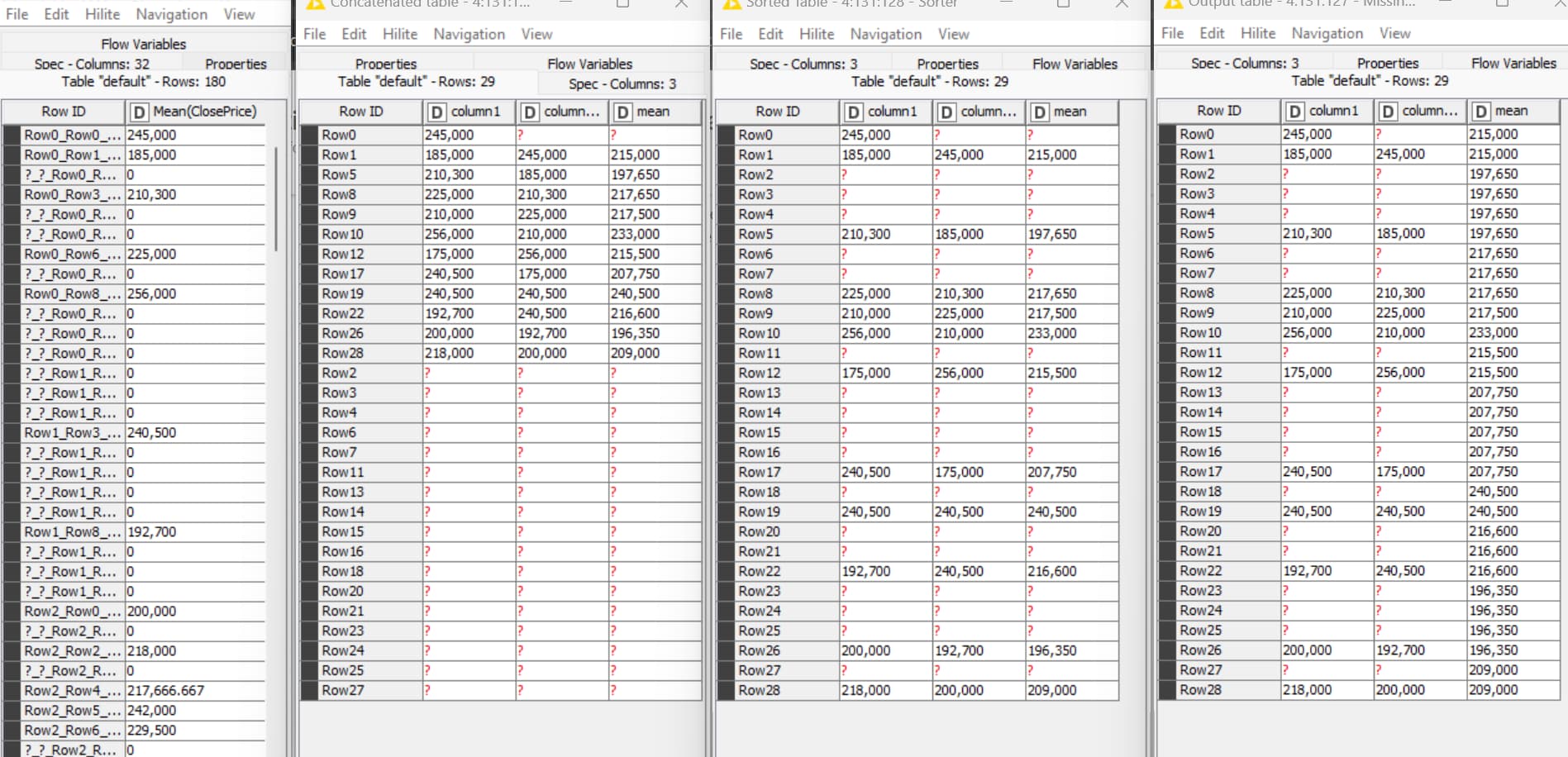
@AlexanderFillbrunn, I don’t want to burn too much of your time, but just a quick visual of the known Mean Close Price and the Predicted Mean Close Price seem a bit weird. Should the prediction essentially repeat the same values it’s using for the prediction?
Please see the known data on the left and the predicted data on the right. Thanks
Hi,
This does not seem so bad. What I would do: separate the dataset where you do know the MCP into a training (70%) and test (30%) set. Then you train your model on the 70% and apply it with the predictor on the 30%. Then you can compare the actual numbers and see how much you are off.
Kind regards,
Alexander
just my approach which is may not be the best solution, and unsure if it meets your expectations.
the attached workflow calculates the mean within cluster zero/missing values. KNIME_mean-MM.knwf (119.2 KB)
rgds linux knime 5.1.x
@marzukim, WOW. I tracked your progression of each step allowing for incremental adjustments and a final outcome presenting a gradual trend where there was a great deal of missing data and substantial jumps in the values available, both up and down from previous and following known data.
@mlauber71@AlexanderFillbrunn@Daniel_Weikert I wish to thank you and each other contributor here for your ideas. If I ever get half as smart as you guys, I may just accomplish this project which is far above my abilities
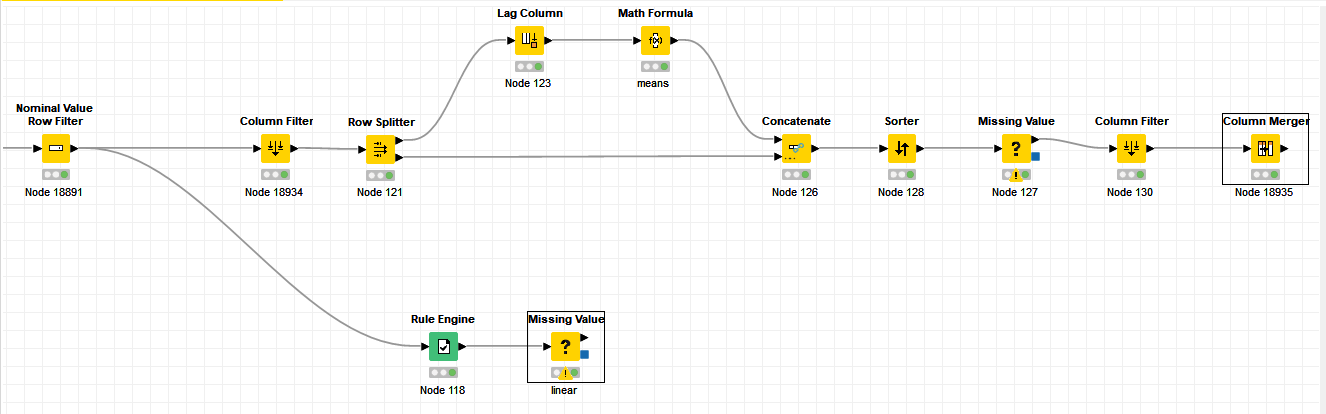
@marzukim, I’m simply confirming your solutions. The process ending with the Column Merger node is a second option and the process ending with the Missing Value node is the first option. I don’t see where you ever combined the results, so I believe you offered two separate solutions.
yes, my approach employs the workflow route that ended in column merger nodes. the second approach, i’m using recommended approach by Daniel, utilizes the linear interpolation option. additionally, Markus and Alexander have also proposed the solutions. it is up to your preference to choose the method that best suits your requirements.