I’ve been assigned a project to create a PowerBI dashboard with automated back-end data to minimize manual input and sourcing, make it adaptable for changes (like adding columns), and ensure it’s fast—I’m using KNIME for this. Our raw data is in Excel files.
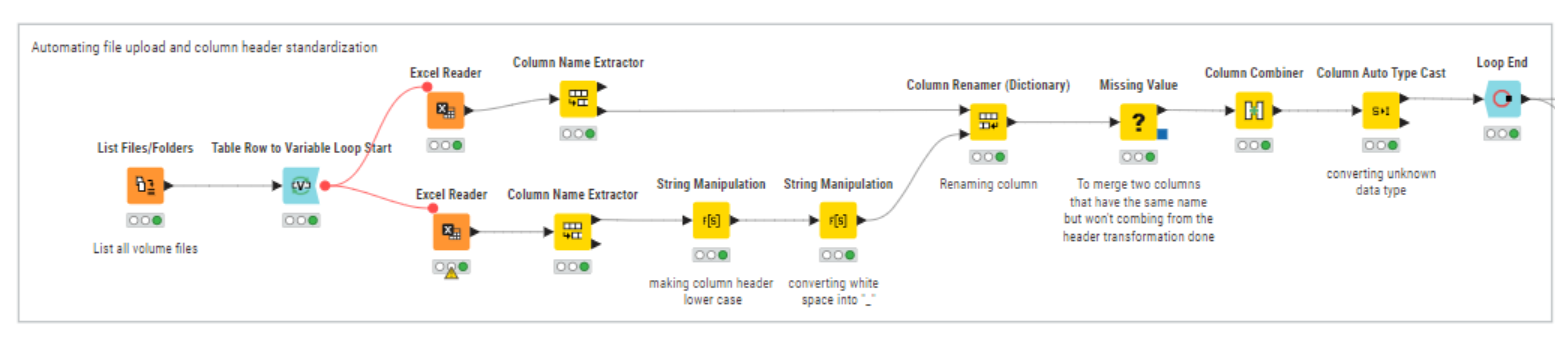
Currently, I’m using list files and loop to automate data uploads (of our fact table) and standardize column headers so data merges automatically. However, it takes 5 seconds to execute the loop and uses a lot of memory.
Any tips on:
Automating file upload and data transformation
Improving model speed
Automating KNIME data refresh to keep PowerBI updated regularly and share my workflow to my teammate so they can maintain or update it regularly while still keeping it connected to PowerBI
I might be leaving soon, so I need to ensure my teammates can maintain the KNIME workflow for the PowerBI dashboard.
This is my current work flow for automating file upload and column rename
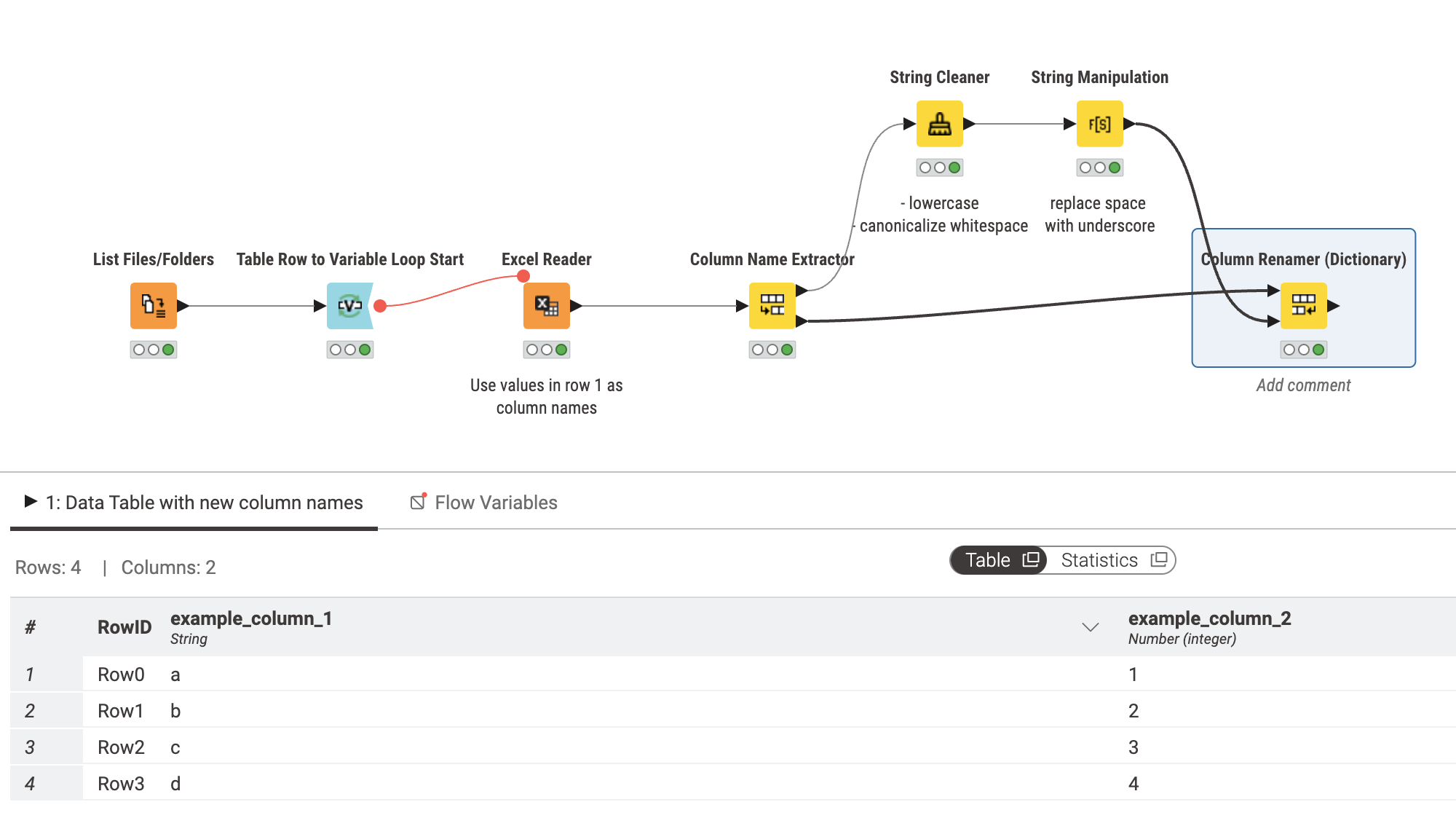
I don’t have experience with PowerBI, but maybe removing the loop or reducing the number of iterations by “batching” similar files is an option to speed things up. The Excel Reader can read multiple files (“Files in folder”) if the names can be matched by a wildcard or regex pattern, or if you can move them into a dedicated folder beforehand that also works. If the columns are always the same for each “batch” of files it should be possible. Under “Advanced” there is an option to “Append file path column”, so you can associate the source Excel file with a particular row afterwards (to group data again or filter).
Hi thank you! Unfortunately, columns are called differently i.e. product code, value, etc. sometimes they are also in different cases so excel reader cannot recognize them. That’s why I used loop to get the files and standardize headers
Is there a reason you use two branches of “Excel Reader->Column Name Extractor” and use only the upper and lower port exclusively in each branch? Could you show how the Excel Readers are configured (without any sensitve preview content of course)? Maybe you can eliminate one instance of the Excel Reader to reduce execution time.
This is what I meant. Though I am also not sure what purpose exactly “Missing Value” serves or how Missing Value, Column Combiner, and Column Auto Type Cast are configured exactly.