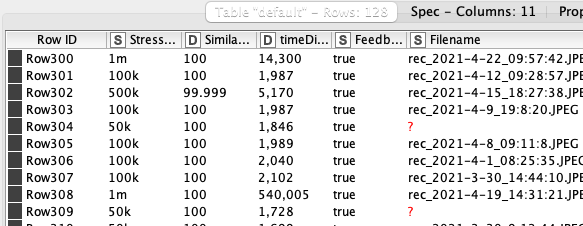
I have been using DynamoDB Scan node for a few months and always work fine. Recent I connect to a new table and only return the rows on and after 200, so the first row is 200, then 201, 202… and so on. It has the same setting with my other projects and this is the first time happening, what are the possible reason?
I also check on AWS side, this table is also same as others (this table has only 3xx rows vs others like 3xx,xxx rows).
we found a bug in the code of the node and created a ticket for it.
Thank you for reporting this issue, I will get back to you as soon as there is an update from our side.
(Ticket AP-16825 - for internal reference)
I have discovered the same problem! When load the data from one table in DynamoDB with the connector, I get 13035 records. Using a Python script based on boto3, I get 15085 records.
Unfortunately, this has led to some errors in our calculations…
Is the fix going to be released in the release 4.4? Just to know if we need to modify all our worklfows with the Python node or if we can expect a fix in the next days…
Regards,
Could you also take this opportunity to fix the filters? At least on my side, I need to try multiple times to have them persisting in the config tab. And the documentation could be clearly improved.
I wanted to let you know that the fix AP-16825 corrects the problems of losing rows when reading a DynamoDB table. Thanks for the prompt reaction to the Knime Team!