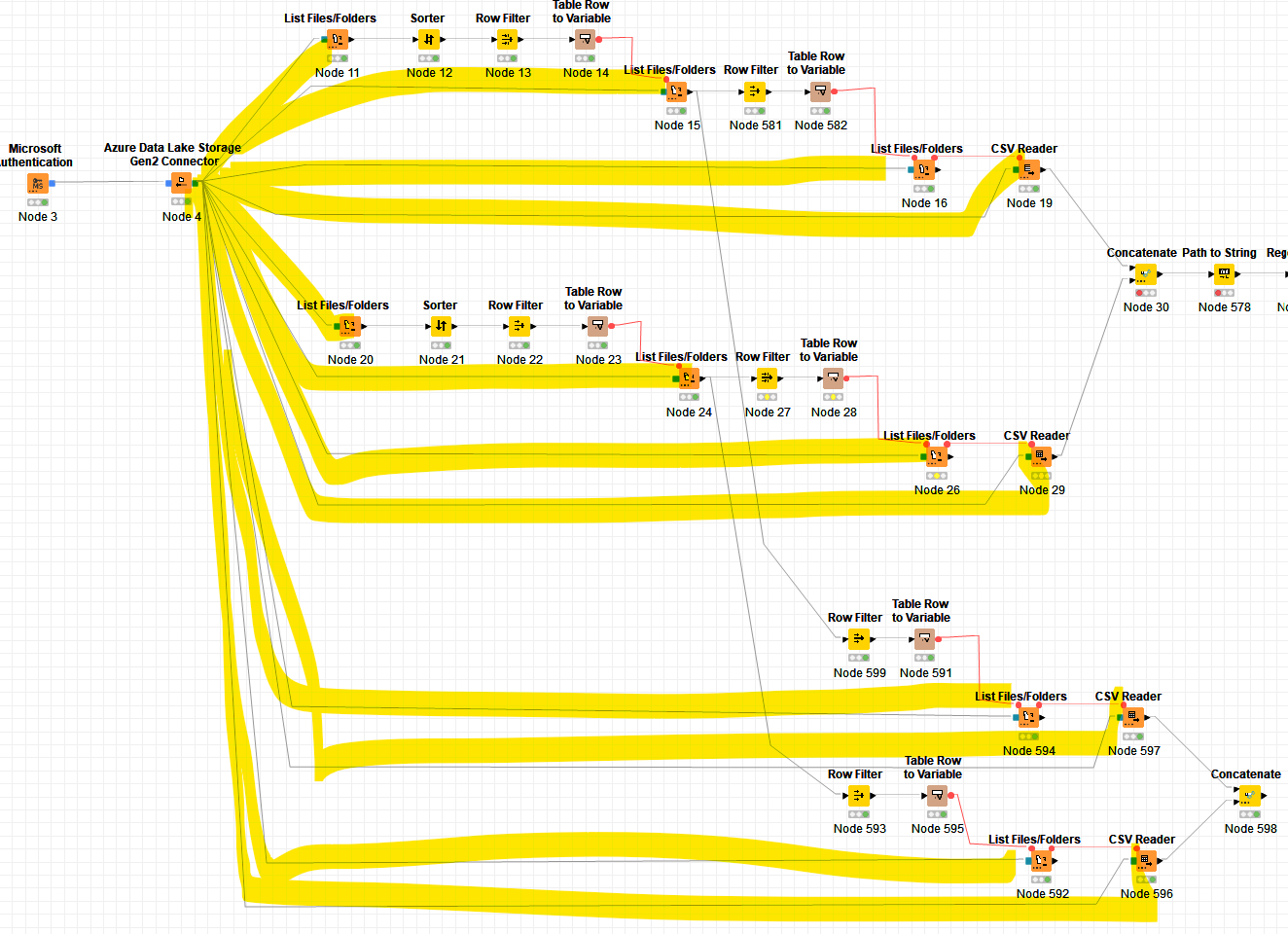
I don’t really have a problem but just a question about using this connector.
In fact, the way I use it, I have a lot of connections to make to each nodes system connection port,
and I’m wondering if there isn’t a better way of doing this? (like variable that we can transport from node to node…)
File system connection is a sensitive port with respect to security concerns. I do not think you can convert it to flow variable for this dedicated type of connection.
However, with what I noticed from the screen shot is that you are surfing the desired file first then calling on the CSV reader. You can use only one List Files/Folders nodes and view all files (including the subdirectories). That way you will trim down whole lot of nodes. Then you can use seperate row filters with different wild card expressions to point at dedicated sub directory.
As far as CSV reader is concerned, you will still need the file system configuration port? However, once you have identified the desired files from List Files/Folders, do you still need this node? I believe a direct connection from Azure Data Lake Storage Connector to CSV reader will suffice.
Hi,
Thank you for your answer.
Ok so there is no other way doing it.
I use 2 successives List Files/Folders because I’m targeting the last directory with most recent date in the name of directory (like yyyy-mm-dd), so I sort by date Z to A, I take the first occurrence to limit the list of files to 1 subdirectory and then I read the CSV taht is in this directory.