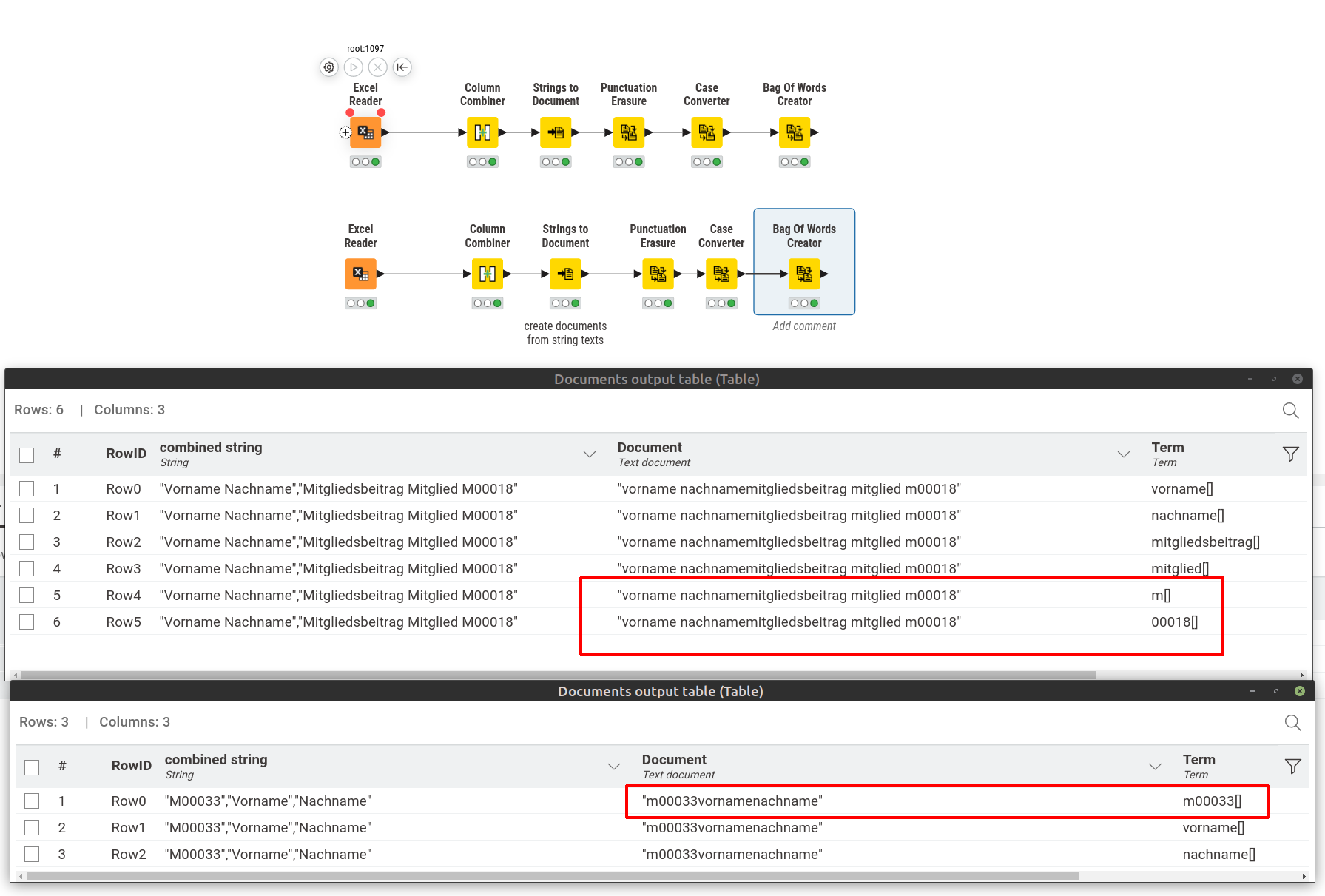
Bag of word is splitting text differently for no obvious reason. See marked region in attached image.
Background:
I am trying to match bank account data with a member list. Therefore i take some columns from both datsets and try to find similarities.
As part of this process I preprocess the data by combining the columns, convert to document, erase punctuation, and convert the case before I try to create the bag of words.
This is basically identical processing to both datasets.
Expected Behaviour
The document is splitted into terms basically at word-boundary on both documents.
Actual Behaviour
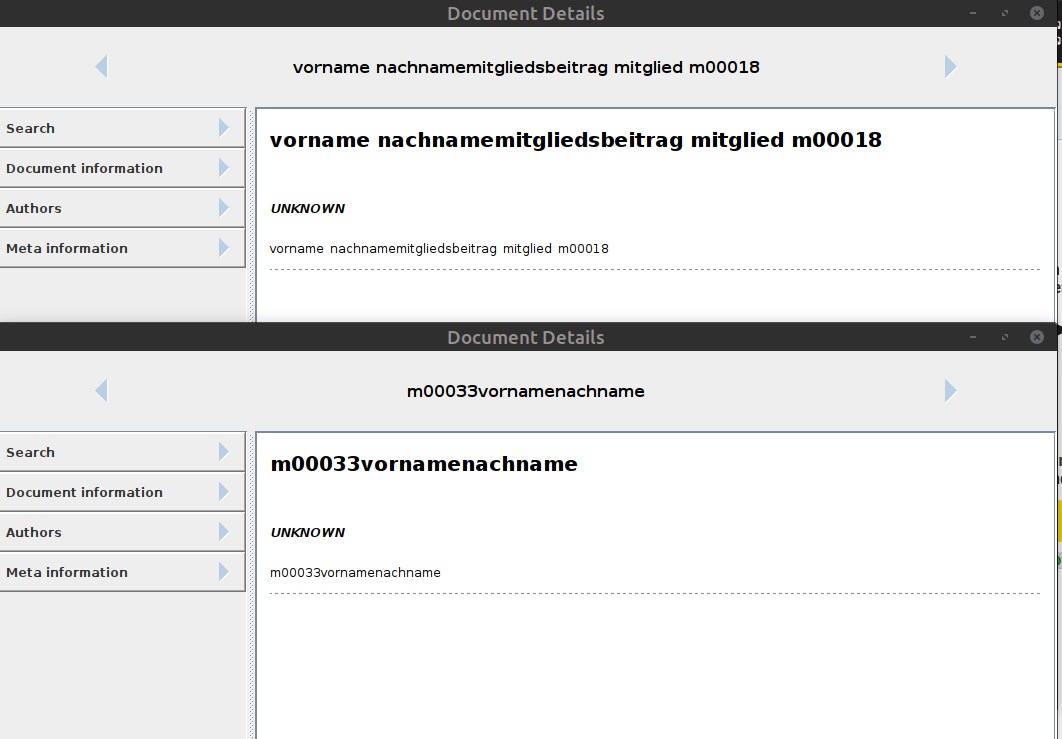
One does split it a word boundaries - where it originated from own field, and was at the first position (single word in the field).
It does split the word into two terms - where it was part of a longer text and at the end position.
I finally found the solution:
It’s been the “String to Document” node which caused the differencies in output.
The working part used the “OpenNLP English WordTokenizer”
while the non working part had the “OpenNLP SimpleTokenizer” set.