Hey guys, I’m new to Knime. I am playing around with a dummy data just to get the hang around the software. I’m trying to learn sentiment analysis (lexicon approach), but now Im still in the process of testing the upstream nodes.
At the moment I am at the stopword stage. I have tried to search the forum to see if anyone has posted this issue I’m encountering but I cant find an exactly similar issue with what I’m facing.
My first issue with stopword is, after I added the node to my workflow, and start configuring the node, I wasnt allowed to choose (i.e. to tick the box) between built-in and custom list. The default is always built-in, and not that I mind using the built-in as it helps cut my time from creating my own custom list of stop words, but what if I need to use my own custom list in the future?
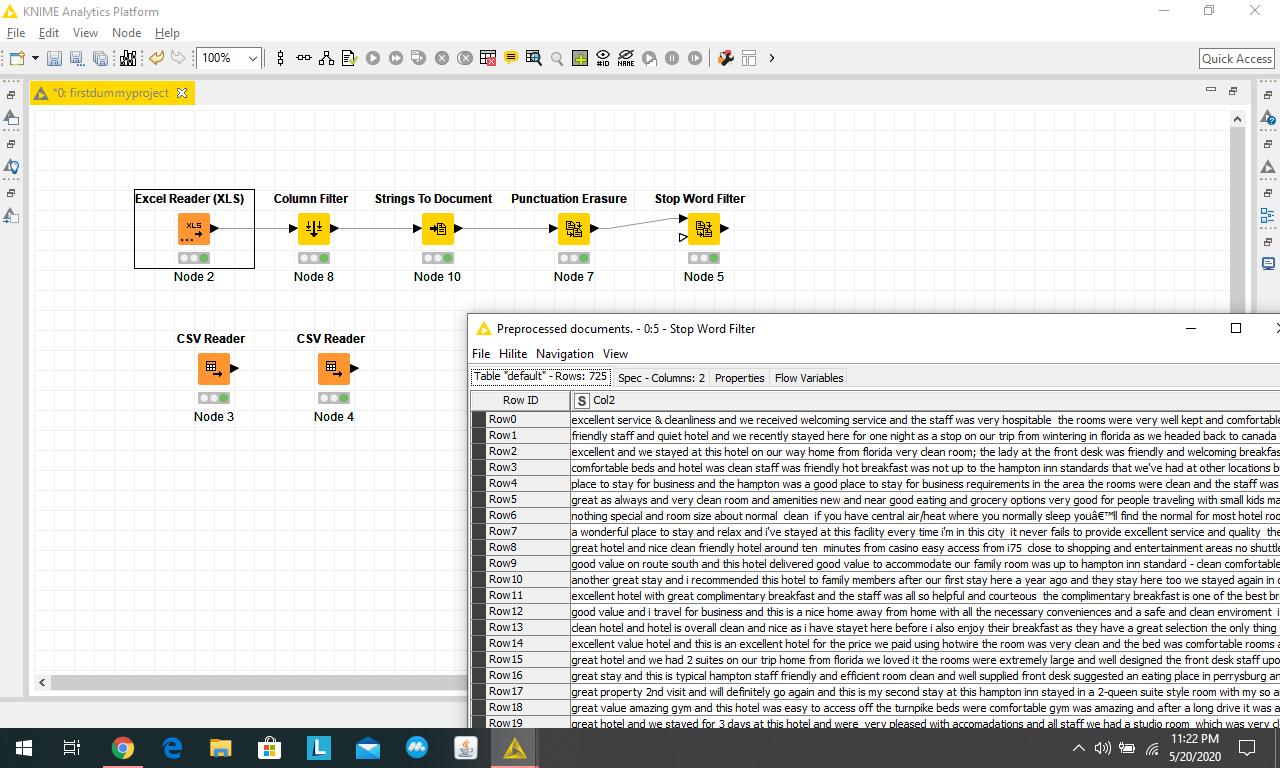
Secondly, with the default built-in stopword configuration (with the built-in list setting), the outcome of the table after execution seemed to show the same input data which is not filtered. Hereby I’m attaching the screenshot of it:
Welcome to the forum, and to the KNIME Textprocessing extension. To answer your question about the Stop Word Filter node - if you want to use your own list, you can. You just need to load your list into the node using the second optional input port. If you do this, the option to choose your own list will no longer be greyed out.
The reason that it doesn’t look like the Stop Word Filter is doing anything is because you’re looking at your original string column (Col2). But text preprocessing nodes in KNIME always operate on a Document column, which is created by the Strings to Document node. To see what filtering (or tagging, or other operations) are being applied, you need to use either the Document Viewer or Tagged Document Viewer nodes.
I’m sure you will have more questions as you keep going so feel free to ask here. You may also benefit from one of our Text Processing courses (our next one is coming up in August, but you can see the agenda for the current course here) or the book From Words To Wisdom available at KNIME Press.
The summary so far, I tried to use one column out of 3 to apply the stopword node onto. From the document views, I can see that the stopword node has functioned properly using the built-in setting. I notice that the word “good” is filtered out, and this might affect my sentiment scoring going forward (where I will use the Bing Liu lexicon which contains the word ‘good’ listed in its positive wordlist).
I wonder if there’s a way that I can view the full built-in list of stopwords, and then filter out some words like ‘good’ from the built-in stopword list?
I hope my question is understandable. Thanks in advance!
I have looked at the link. Now that I’ve found the txt file, I can make a modified copy of it to suit my project. Then I’ll move on to lemmatizing stage.
Another way to handle this problem in a sentiment classification context - apart from editing the stop word list - would be to apply your sentiment tags early on with the Dictionary Tagger using the “Set named entities unmodifiable” checkbox. Then, if you use a Stop Word Filter node downstream, your tagged words won’t be filtered out.
You can use a Stop Word Filter at the end of this workflow to see and verify what I mean:
@ScottF That makes perfect sense, thank you! Will keep that in mind. As of now, I have found that I can just use the Stanford POS tag to remove certain classes of words rather than using a Stopword node. Some journal articles do it this way (although they might use alternative POS tag system than Stanford’s, but that is another topic).
Anyway I have just finished creating my first BoW. I have looked at many workflow examples from various sources to convert the Sentiment tag column into scores, I have tried a few but couldn’t figure out how to work around it. Will try the Pivot method tomorrow when I’m refreshed.
 To answer your question about the Stop Word Filter node - if you want to use your own list, you can. You just need to load your list into the node using the second optional input port. If you do this, the option to choose your own list will no longer be greyed out.
To answer your question about the Stop Word Filter node - if you want to use your own list, you can. You just need to load your list into the node using the second optional input port. If you do this, the option to choose your own list will no longer be greyed out.