Hi
We have a very big table that have 306237 rows and 85006 columns. We have a workflow that run 100 iterations of random forest. The workflow is very slow. we are not able to reach results yet.
What is the best way to handle a such big table?
No idea of the structure of your table or the variable types so its difficult to make suggestions. Do you really need 85k columns? Could you do some manual dimension reduction or employ PCA or some other dimension reduction algorithm?
1 Like
Hi @malik ,
You have a huge table, but as @rfeigel said, dou you need all of it? Can you “group by” some of it or just load what you need to work? With less data in memory, you will process better… Other tip is set the node with mode complex process to write data into disk space, not process in memory one.
Example from any node:
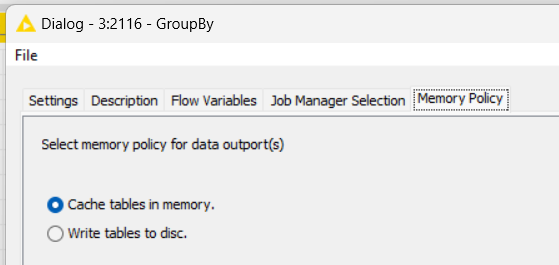
Maybe, for you case, if you have space in your HD, you can use it to save memory and be a little quick too.
I hope that helped you.
Regards,
Denis
I would echo what @rfeigel said. 300k rows is not so big; 85k rows is quite a lot, and very likely the cause of your performance problems. You would almost certainly benefit from exploring some dimensionality reduction strategies prior to modeling. Maybe this post from the KNIME blog can help:
2 Likes
I am curious. What kind of data are you dealing with? What are you going to predict?
br
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.