I just got a handle on the new binary classification inspector node and its been working great thus far! I understand that you can “select” an optimal model using the apply button in the interactive view but is there a way to then use that model to predict upon new data? In other words, is there some sort of universal predictor node I can feed new data into using the existing approved model. The reason I want this is because right now the classifier is set up to predict upon my control data (80/20 cross validation) and I would like to use the best model to then predict upon my treated conditions if that makes sense. There may be a way to do already with the node I am not sure. Any help or guidance would be appreciated.
Hi @ReidF,
I am happy you are liking our new node and its view.
The node is meant to give an interactive solution to find the best threshold and select a single model from its view. However it also compute a number a number of things regardless its view acting as some kind of a new “Scorer node” only for binary classification. In fact it outputs the settings for you to store and re-apply with other nodes (like for example a Rule Engine node) to a deployment model.
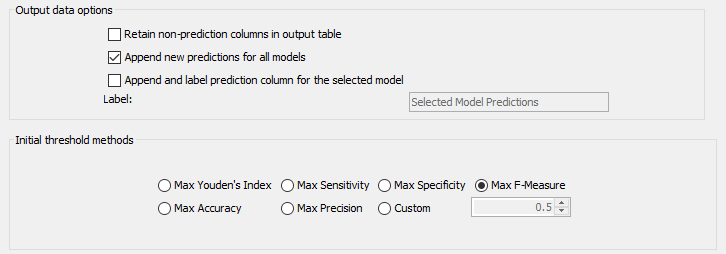
First of all by default you can set the node to optimize the threshold for all input probabilities (that is for all different models). At the output of the node you should see the optimal threshold and the associated performance metrics as well as the classifications given those threshold (check the box “Append new predictions for all models”). This is computed without any in-view user interaction if you change the threshold from default (0.5) to the optimization of a performance metric, for example F-score (see picture).
As you can see the node is creating new classification columns storing the new predicted classes given the new threshold. However this does not mean the node is able to score new data for which probabilities are not available. You need to use a predictor node for that. The best and most generic predictor node that you can use for all PMML models is the following (recently updated in 4.1 to output probabilities): https://kni.me/n/jya1a6bRZlBmer8S
However no model is selected (“Selected Model Prediction” column) and no flow variable with the selected model threshold is applied. You will need to automatically select the best model (highest F-Measure for example).
This tiny workflow (https://kni.me/w/1b6mEyoQIMW3qvoK) is supposed to show you how you can score new data (no ground truth (Target column) is available) and apply the best threshold found using the training set.
Step 1 use the predictor node.
Step 2 apply the threshold found by the Binary Classification Inspector node with a Rule Engine node