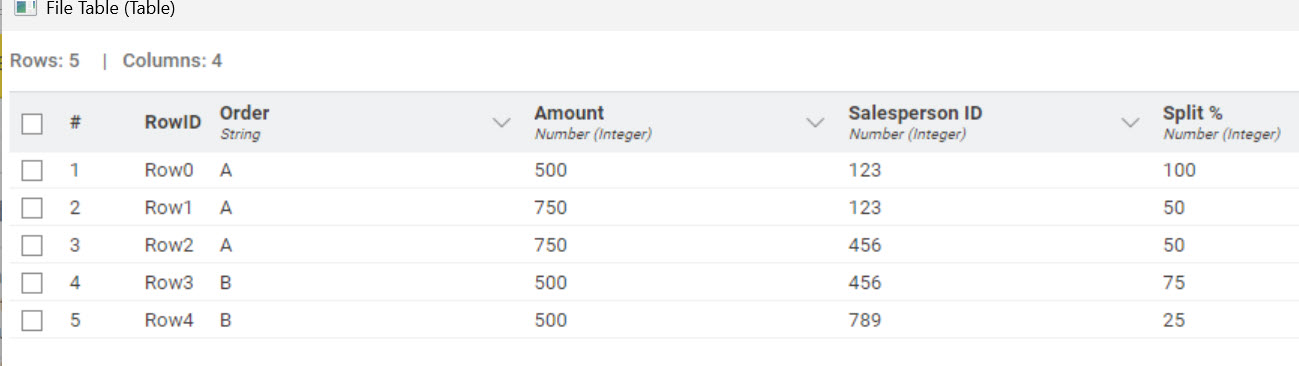
I have a dataset that contains order details and salesperson assignments, along with a split %. I need to assign each transaction a unique ID. I used to accomplish this in Alteryx with the ‘Tile’ tool. Essentially I need to check for all columns besides the salesperson ID / split %, and if all the other columns match another row, both (or multiple) rows get the same ID number. Any ideas?
there are many ways for it. the question is, does the ID you generate need to be unique across multiple datasets (e.g. months, years), can the ID change during executions or do 2 runs of the execution (e.g. first run containing the first half of a year and a second run containing the full year) produce the same IDs for the records / groups?
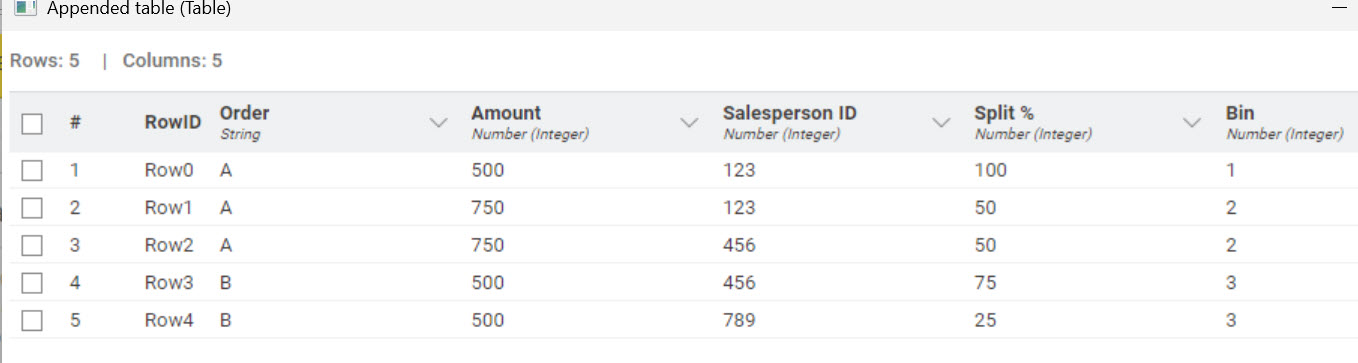
the easiest method, only applicable for the specific dataset, is adding the RowID as additional column (via RowID node) and then running a Group by, excluding your Salesperson, split and RowID but concatenating (or unique concatenating in case you also have duplicates you need to filter out) the RowIDs