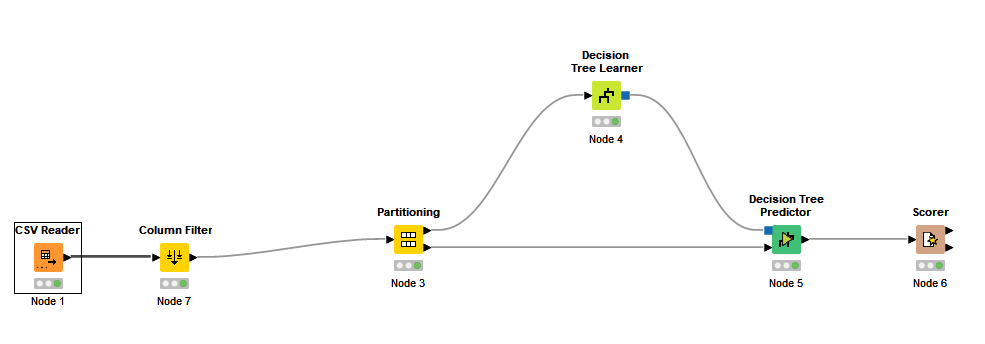
This column is the class column I would like to insert in my prediction model. The variable is a boolean variable and it refers to the dificulty of intubation during surgery. “0” means that the patient is easy to be intubated and “1” that the patient is difficult to be intubated. To evaluate this, I’ve used the Tree Decision Algorithm for classification.
Hi @helfortuny & welcome to the Knime forum community
It should not make a difference to have this column either as string or boolean given that you are using a Decision Tree. Any model based on trees should be the same.
Eventually, if you want to convert it to integer, you can use the -String Manipulation- node with the following instruction:
toInt( $yourStringColumn$)
If you really need to convert it to boolean, you could use a -Rule Engine- node with the following instructions:
$yourStringColumn$ = “1” => TRUE
FALSE => FALSE
Hope it helps.
Best
Ael
Ps: I’m suggesting these solutions by heart since I’m replying from my mobile phone.
Thank you Ael!!!
And what about using this data with other models like Random Forest, Artificial Neural Network or Logistic Regression? Does it make no difference if I have this column as string?
PD: I’m asking these concerns by heart since I’m replying from the office.
My pleasure. Random forest are ensembles of Decision Trees so no need for conversion.
However In most implementations of ANN (Feed Forward Neural Networks), you will need to convert any non-numerical variable to a numerical format. The same for Logistic Regression.
In general, any Machine Learning Method that internally calculates a distance based on descriptors (variables) needs in principle to have variables in numerical format.
I am working with medical data also at the University of California, at Irvine, predicting the presence of precancerous colon polyps from clinical (EMR) data. I have found that the decision tree ensembles work best (Random Forest, Tree Ensemble, Gradient Boosted Trees, or XGBoosted Trees). I use a fused ensemble of Random Forest, Gradient Boosted Trees, and XGBoosted Trees to make the final predictions. If your target classes are highly imbalanced, you might want to use the SMOTE node to oversample the minority classes. For moderately imbalanced data, Random Forest works ok. If you want to use Logistic Regression, consider that it is a Parametric Statistical algorithm that makes a number of major assumptions (normal data distributions, variable independence, and homoskedasticity, all of which are violated bigtime in most scientific and medical data sets. Also Logistic Regression requires you to standardize the data values to remove effects of greatly different scales among the variables. I found also that neural networks (even deep learning NNs) don’t work as well as decision tree ensembles on medical data with a symbolic target variable (which you must change to a number with the String to Number node to work with the NN).
The biggest boost to your models, however, have nothing to do with the algorithms you choose. Data engineering techniques can be used to derive many variables from values in your present predictor variables. I have found that many of the top predictors in my models during he last 25 years are those that I derived myself.