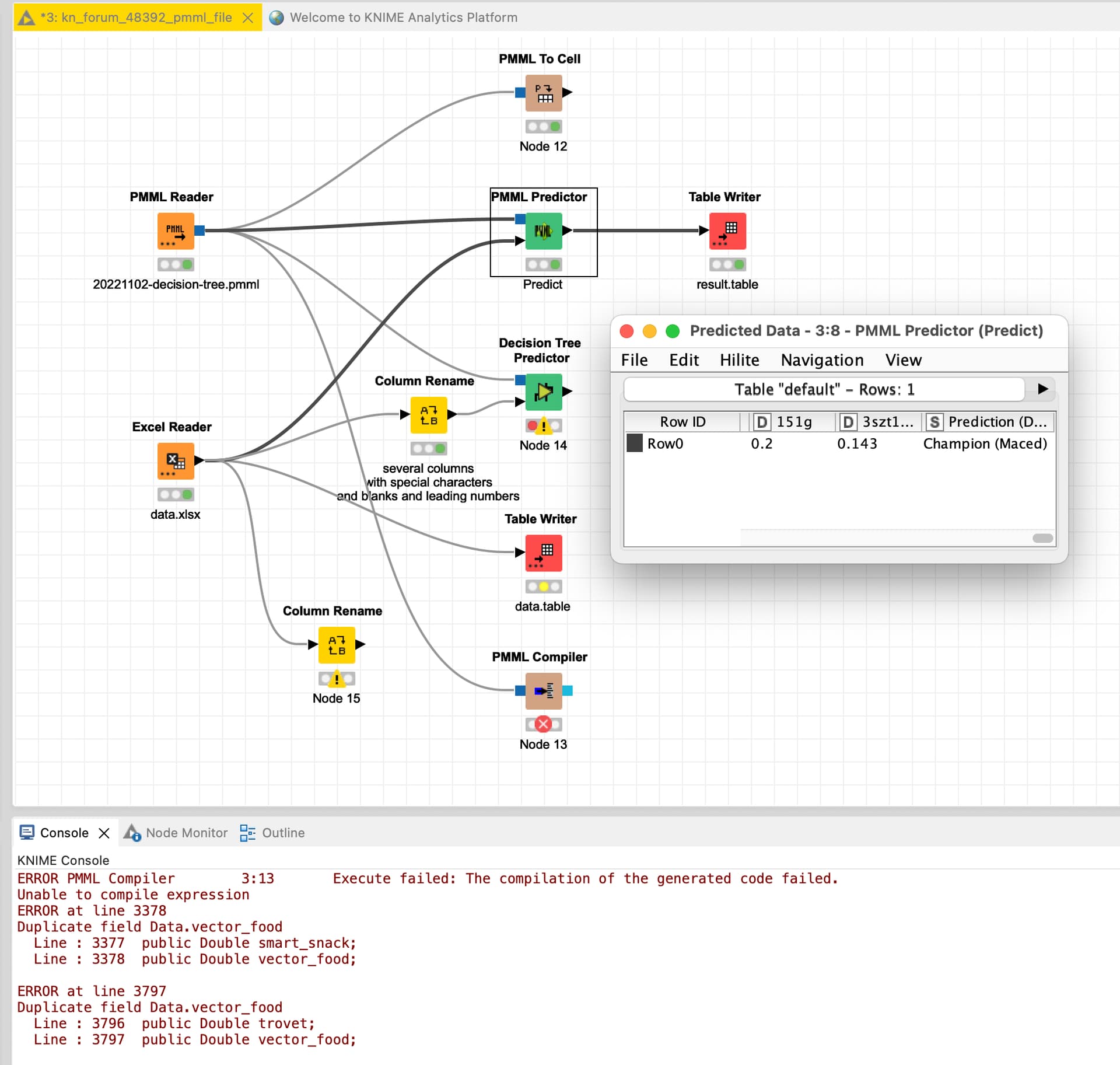
Hi there, I built Decision Tree model (±500 features), pmml file is around 500MB. I am unable to run it on predictor (DecisionTree nor PMML), because there’s serialization issue when loading the model:
ERROR KNIME-Worker-10-PMML Predictor 3:151 Node Execute failed: Could not create PMML value.
java.lang.RuntimeException: Could not create PMML value.
at org.knime.core.node.port.pmml.PMMLPortObject.getPMMLValue(PMMLPortObject.java:888)
at org.knime.ensembles.pmmlpredict3.PMMLPredictorNodeModel3.execute(PMMLPredictorNodeModel3.java:134)
at org.knime.core.node.NodeModel.executeModel(NodeModel.java:549)
at org.knime.core.node.Node.invokeFullyNodeModelExecute(Node.java:1267)
at org.knime.core.node.Node.execute(Node.java:1041)
at org.knime.core.node.workflow.NativeNodeContainer.performExecuteNode(NativeNodeContainer.java:595)
at org.knime.core.node.exec.LocalNodeExecutionJob.mainExecute(LocalNodeExecutionJob.java:95)
at org.knime.core.node.workflow.NodeExecutionJob.internalRun(NodeExecutionJob.java:201)
at org.knime.core.node.workflow.NodeExecutionJob.run(NodeExecutionJob.java:117)
at org.knime.core.util.ThreadUtils$RunnableWithContextImpl.runWithContext(ThreadUtils.java:367)
at org.knime.core.util.ThreadUtils$RunnableWithContext.run(ThreadUtils.java:221)
at java.base/java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source)
at java.base/java.util.concurrent.FutureTask.run(Unknown Source)
at org.knime.core.util.ThreadPool$MyFuture.run(ThreadPool.java:123)
at org.knime.core.util.ThreadPool$Worker.run(ThreadPool.java:246)
Caused by: java.lang.NegativeArraySizeException: -445500886
at java.base/java.lang.String.<init>(Unknown Source)
at java.base/java.lang.String.<init>(Unknown Source)
at java.base/java.io.ByteArrayOutputStream.toString(Unknown Source)
at org.knime.core.data.xml.XMLCellContent.serialize(XMLCellContent.java:257)
at org.knime.core.data.xml.XMLCellContent.<init>(XMLCellContent.java:169)
at org.knime.core.data.xml.XMLCellFactory.create(XMLCellFactory.java:162)
at org.knime.core.data.xml.io.XMLDOMCellReader.readXML(XMLDOMCellReader.java:174)
at org.knime.core.data.xml.XMLCellContent.parse(XMLCellContent.java:267)
at org.knime.core.data.xml.XMLCellContent.<init>(XMLCellContent.java:137)
at org.knime.core.data.xml.PMMLCellContent.<init>(PMMLCellContent.java:98)
at org.knime.core.data.xml.PMMLCellContent.<init>(PMMLCellContent.java:82)
at org.knime.core.data.xml.PMMLCellFactory.create(PMMLCellFactory.java:136)
at org.knime.core.node.port.pmml.PMMLPortObject.getPMMLValue(PMMLPortObject.java:886)
... 14 more
I’d like to file a bug report.
Thanks for the amazing software and keep up the great work!
EDIT: I reduced my model to 200MB and it barely fit into 20GB of RAM when deserializing.
Thanks for the bug report and log. So far I have been unable to reproduce this error - if you have an example workflow (maybe with fake data) that demonstrates the problem, that would be helpful.
@pl_profetes can you also try to use the model on just a few lines of data. Also you might want to tell us about your system setup, how much memory you have and how much do you have assigned to KNIME.
Is this a combined PMML file with model and transactions or ‘just’ a prediction model or is it a transformation. You mention (de-)serialisation.
There might be other performance tweaks to consider.
Old model of 500M fails, old model of 190M fails, old model of 56M fails. Models were generated before 4.7 (end of October). The error message is the same as reported above.
Model of 56M attached.
However, after exporting new model in 4.7 I was able to import it successfully:
Which may suggest, that PMML Writer/Reader may have had a bug, but it’s fixed now?
@pl_profetes I set up a workflow with one sample row that would predict the result with the PMML Predictor. One thing you could check is the names of the variables. You have leading numbers which usually might cause problems and also NON-US-ASCII characters and blanks in the variable names. If possible I would advise to not use these.
If I try to compile the PMML file (which might save space and speed up things) I get an error message. In general you might want to ioniser if several thousand columns are the right approach or you might want to throw in some feature engineering.
You can also extract rules and SQL code from a decision tree. In your case there seem to be too many columns and rules to use them in a meaningful way.
Then: it seems you are trying to classify types of (?) dogs. So this might be a (large) multi class task. I am not sure a decision tree is an always a good approach - of course it might be that special dogs have so well defined ‘features’ that there can be definite rules. But I am speculating.
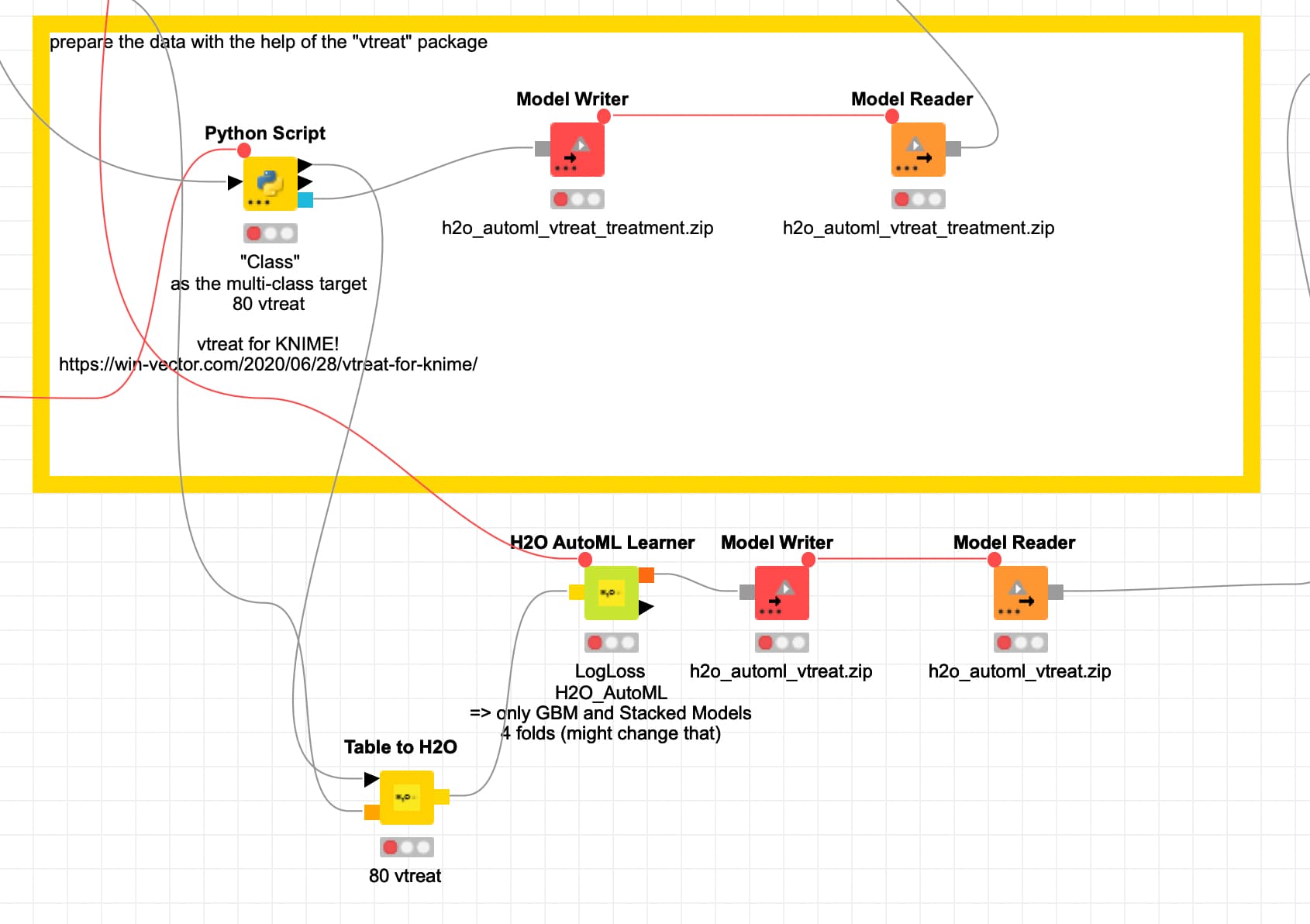
As it happens I have recently updated a larger multi-class workflow including a data preparation with the vtreat package. The methods used would also have the benefit of producing compressed models that might be better suited to be deployed. Also with H2O.ai MOJO files you could use them in KNIME, R and Python at the same time.
Wow, thank you for the deep analysis of my case! I just wanted to report a bug…
You are right, I’m trying to figure out the brand name (266 possibilities in that case) based on short offer names (train set of 60K+ items) from certain ecommerce platform. I chose Desision Tree, because I needed quick and dirty POC of this working. And by simply taking 90% of all words and processing them a little I got 90% accuracy immediately.
Thank you for pointing to vtreats. Would that handle my case, where I can have up to 1000 classes?