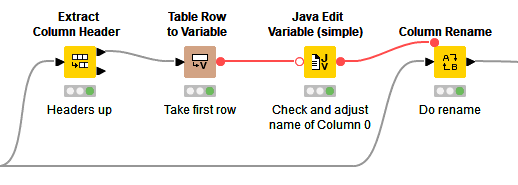
I am dealing with this for several years already. So when trying to read utf-8 CSV file with Complex File Reader, it looks all normal, but actually first column name has invisible space prepended. This leads to hard-to-debug consequences, like [visually] duplicate column names in same table, suddenly failing aggregations when switching data input, etc.
Any hopes to get this handled?
Result of concatenate of same file (3 columns, ccy, rate, dte), read with Complex reader and CSV reader:
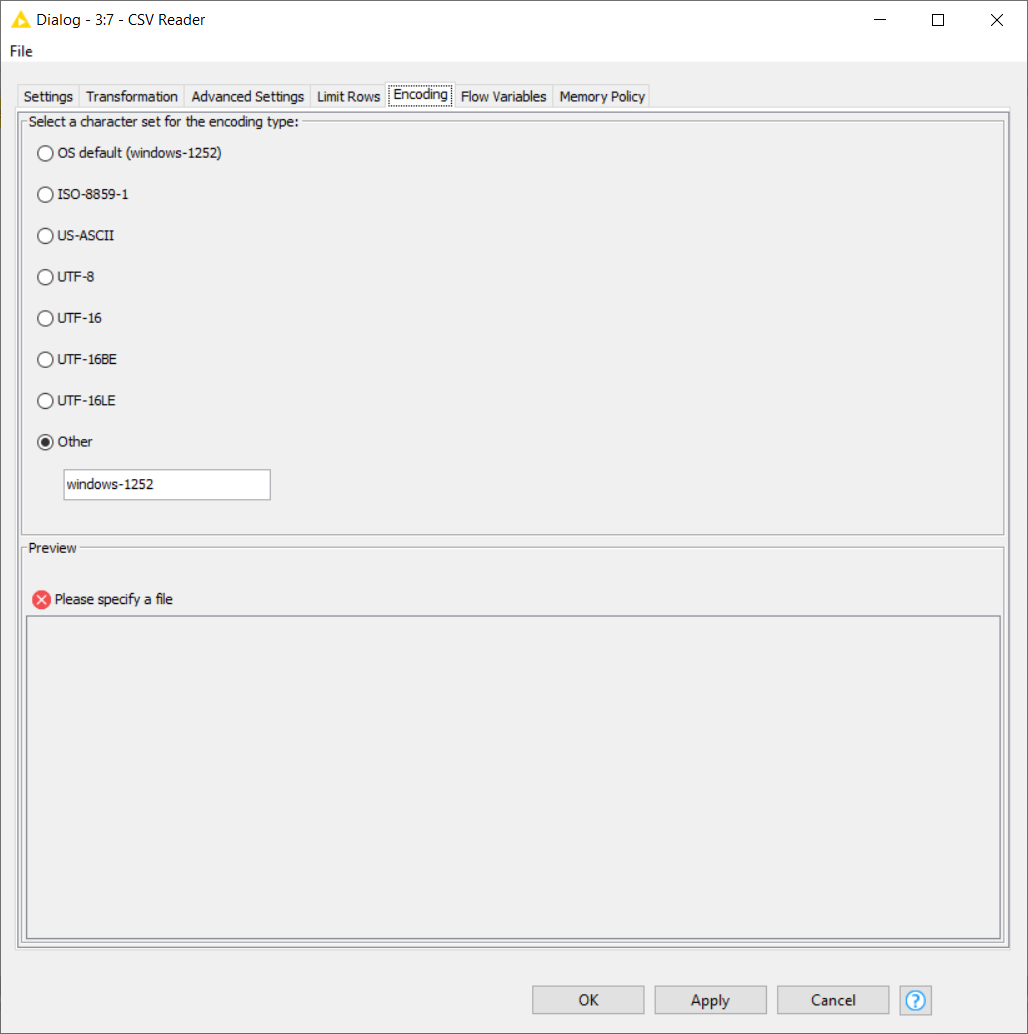
It occours because of encode tuype from file and from the text content… UTF8 need to be the same for both cases… If the file is other type or the content (ISO, Windows/mac…) this caracter wi’ll be present… try to convert you file and contento for the same encode type first.
For CSV file, you can choose the encoder as default: