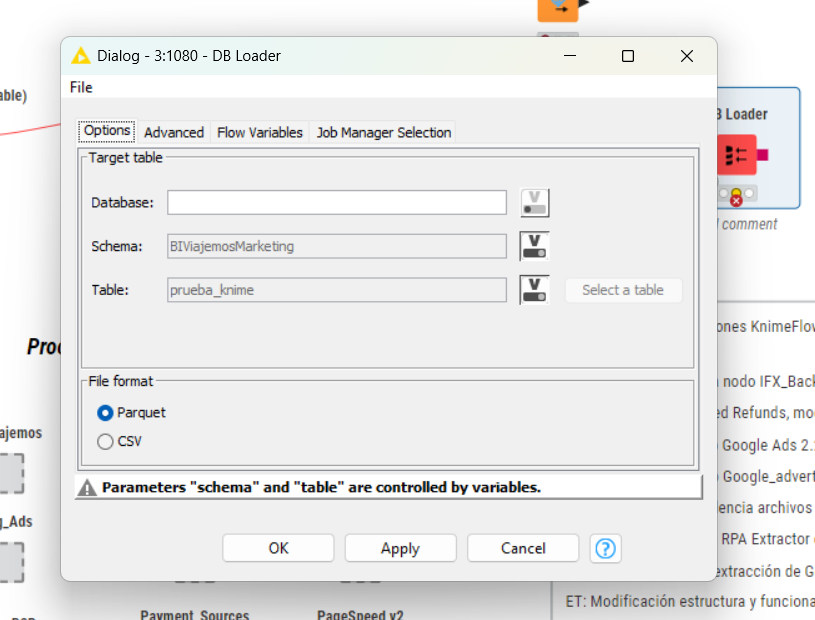
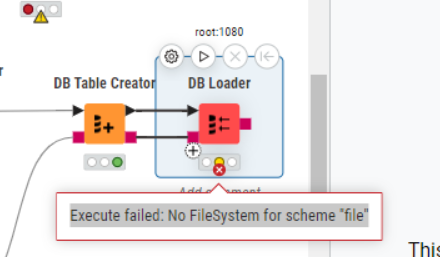
I’m encountering an issue with the DB Loader node when uploading data to a Google BigQuery table using Parquet format. This problem started occurring only after upgrading to version 5.4.4. In earlier versions (e.g., 5.4.3 and prior), the exact same workflow and configuration worked perfectly.
The error message I’m receiving is:
Execute failed: No FileSystem for scheme “file”
This seems to indicate a problem related to how file systems are handled internally in this version when writing Parquet files prior to the BigQuery upload.
Repro steps:
Use the DB Loader node.
Target: Google BigQuery table.
Data format: Parquet.
Run in KNIME 5.4.4 (or newer).
Execution fails with the above error.
Note: When I run the same workflow in version 5.4.3 or earlier, it works without issues. This suggests a regression or dependency change introduced in 5.4.4.
I’d appreciate it if the dev team could review this behavior. Let me know if more logs or a sample workflow are needed to help reproduce it.
After further investigation, I found the root cause of the issue. The full error trace shows the following exception during execution of the DB Loader node:
Execute failed: No FileSystem for scheme “file”
org.apache.hadoop.fs.UnsupportedFileSystemException: No FileSystem for scheme “file”
at org.apache.hadoop.fs.FileSystem.getFileSystemClass(FileSystem.java:3581)
…
at org.knime.bigdata.fileformats.parquet.writer.ParquetKNIMEWriter.(ParquetKNIMEWriter.java:144)
This suggests that the file:// scheme is no longer registered in the Hadoop FileSystem registry used by KNIME when attempting to write Parquet files. Specifically, the error originates from:
HadoopOutputFile.fromPath()
This strongly indicates that LocalFileSystem (typically org.apache.hadoop.fs.LocalFileSystem) is missing or not properly registered in the Hadoop configuration shipped with KNIME since version 5.4.4. This would explain why Parquet export works fine in earlier versions (5.4.3 and prior), but fails in 5.4.4 and even 5.5.0.
If I were configuring Hadoop directly, I’d resolve this by setting the property:
However, since this behavior is encapsulated within KNIME’s BigQuery integration, this may need to be patched or explicitly configured by the KNIME development team.
Let me know if you’d like me to share a minimal workflow or further logs to help replicate the issue.
thanks for reporting the problem and sorry for the inconveniences. This has already been reported here and will be fixed with version 5.5.1 and 5.4.5 of the KNIME Analytics Platform.
Thanks! This is really helpful. My main data architecture relies on writing Parquet files. Using CSV has been problematic due to JSON structures and other formats that tend to change their properties when uploaded. I’ll stay tuned for any updates. You’re the best!
Internal ticket ID: AP-24482 Summary: DB Loader fails when connected to Google BigQuey with No FileSystem for scheme “file” Fix version(s): 5.4.5, 5.5.1 Other related topic(s):