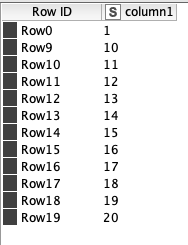
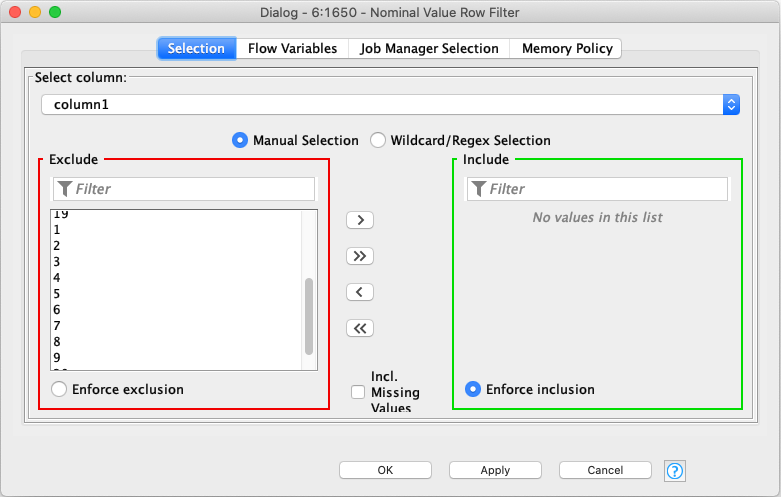
When I use the Nominal Value Row Filter node after a Row Filter node, the values in the Nominal Value Row Filter show the full list instead of the filtered data.
In my original workflow, I have many nodes in between the first and second as well as the second and third nodes, and the data consists of actual text, not numbers. This example workflow is a simplification of my original workflow.
After reading through it, though I understand that there might be a legitimate reason for doing so, I would agree with docminus2 that it is counter-intuitive. Understanding that domain recalculation may be expensive and not relevant in all scenarios, could I suggest to provide a button to recalculate in the Nominal Value Row Filter/Splitter nodes itself (for the purpose of node configuration, so as to not affect downstream nodes), as it is specific to this scenario?
In this scenario for the two nodes, I can’t think at hand a reason why a user would want to select an option that does not exist in the data. By giving the user an option to perform the domain recalculation (for the purpose of node configuration, so as to not affect downstream nodes), I think it would bring about a better and more intuitive experience. For your consideration, thank you.