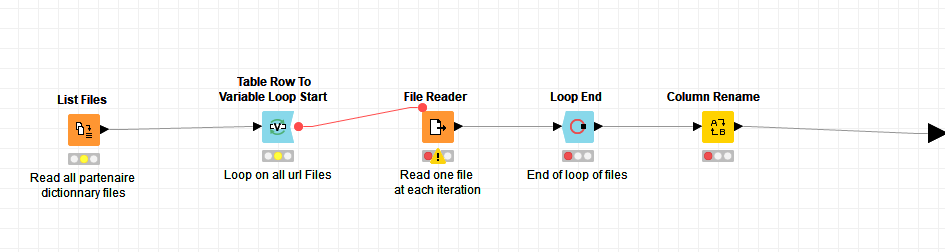
We are using Knime Server Version 4.9.1 and having a strange comportment on a part of our workflow - a metanode which do a list file and then loop on the list to read all files:
Our workflow fails with the error on this metanode :
Execute failed: Must specify non-null table spec and file reader settings for file table.
(and sometime it fails with read time out)
But when I connect to the server from Knime Analytic platform, reset the metanode and restart it, all works well.
The metanode as a workflow apart, however, works well without any error.
I do some test and come up with a “conclusion” like this : I have File Reader that takes a little bit long time to execute, in the mean time, the metanode is executed and it can not do the job. I joint here the example workflow that demonstrate the error. Test_List_File.knwf (18.8 KB)
Can someone please tell me that how can I resolve this problem please ?
@tttpham if the workflow works correct on the stand alone (offline) environment, I think that the problem then has to do with the server. How do you pass on the server environment the directory of the files you want to read?
This kind of path must also work on the server. I haven’t got the problem up till now with this kind of path.
On the server, if I isolate the loop to read files on this aDirectory, everything works well. But it is one part of the workflow, and it makes my WF planted as described in the first post, cf. the attached WF in the same post…
The only thing you can check then, is what is the file that causes the loop to stop and the question that I asked initially: are all the files in the list of the same format?
as the first debugging step, could you please share a reproducible example? The workflow that you shared before does not contain the relevant data and therefore one can not try to run in.
For example, I have tried to reproduce your problem with dummy data. see this directory on the hub:
In particular, 12473_read files is a copy of your looping metanode and it reads CSV files containing dummy data from the local data directory. The dummy data are generated using 12473_create_files. This works fine both locally in an AP client and on my Server. Could you try to change it to make your problem reproducible? Alternatively, if your data is small and public, you can share the original data used by the workflow that you shared in the original question.
could you provide us the KNIME Server and KNIME Executor logs? You can easily download these via the Administration page of KNIME WebPortal under Status Info.
Also, do you know how many files you’re reading in and how big files are?
I’ve also nodice that you’re uploading a file at the same time using the CSV Writer. Do you, by any chance, know how much MB the resulting file has?
As I read the reply of @lisovyi, I realized that maybe my first post is not that clear @@
The problem is not with the loop on reading file alone. It just occured when I have in the same time another File Reader on a big file.
The workflow that reproduce the problem, I repost here :Test_List_File.knwf (18.8 KB)
The workflow is principally combined of a File Reader (that reads a big CSV file, about 950 Mb), in the mean time, the metanode with the loop on reading a list of ~211 text file (same format) is executed and died at the first round.
I need to wait for the File Reader (of the 950 Mb file) executed and reset the metanode, execute it and it will be fined.
I can not, however, provide the files, because they are not public data. Sorry for this …
@lisovyi, @moritz.heine and @nicks, please tell me if this time, I make my problem clear and whether you can reproduce the problem.
thank you very much for clarification!
I can reproduce the problem and I’ll investigate further. I already have some suspicion that the preparation for the large file download might be at cause. A workaround for that would be, to connect the Flow Variable port (right click on node -> Show Flow Variable Ports) of the File Reader, reading the large file, to your Metanode downloading the smaller files. As a result the download of the smaller nodes will be triggered, after the large file has been downloaded. If this takes too long, you could try to wait for a few seconds before starting downloading the small files, see Wait Node https://kni.me/n/yfGdadHsy0HhlKV8
quick update for you:
I’ve investigated the problem and found the solution. The problem is, that File Reader not (and potentially others also) have a specified connection timeout, i.e. they will fail if the connection to the server doesn’t get established within the given time. For the File Reader the default value is 1s. With your example this time out was too low. In the CSV Reader node, you are able to set the connection timeout in the dialog. For the File Reader there is a hidden flow variable called ConnectTimeoutInSeconds. By setting this flow variable e.g. to 10s it works on my local machine and this should be a cleaner solution compared to the one with the wait nodes.
This, however, wont fix the logged error on the server (concerning the broken pipe). We’re still looking into this one, but the File Reader should work nevertheless.
I had the same issue with reading urls. I had to increase the time to 180 seconds! It did solve the problem for most of the links but after 1000 links, I realized that it needs more time.
Suggestion to developers, could the file reader include a dynamic time that never stops until it takes response from the IP to download or read the file?