Hi KNIME team,
unfortunately, I experience a bug in KNIME 4.0.1:
I call a workflow that identifies the newest version of other workflows in my workspace based on my naming scheme (by identifier & date in the worfklow name, e.g. “FI 20190919”). I call this workflow via 10 other workflows - therefore, some workflows have to wait for a while as the identification of the newest workflow lasts around 10 seconds (the workspace is scanned for file names).
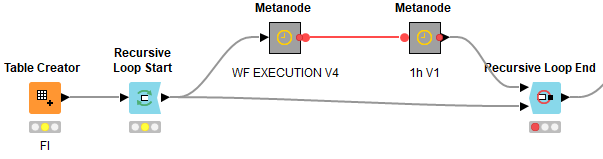
If the workflow call fails, a retry should be initiated one hour later as to be seen in the workflow 01:
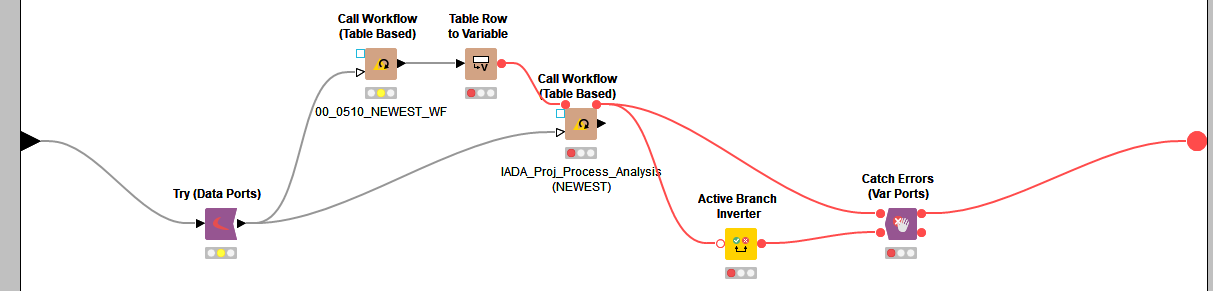
The fail of the workflow call should be identified by a try - catch node combination as to be seen in screenshot 02 (shows interior of the metanode “WF EXECUTION V4”):
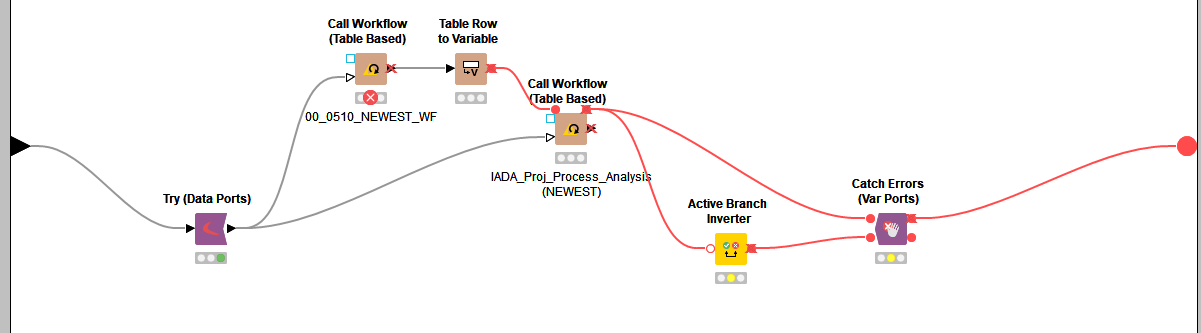
However, if the workflow call fails, the whole workflow fails as the other nodes change to idle, instead:
It may be restarted manually - the error catcher will present this error message:
java.lang.Exception: Failure, workflow was not executed, current state is IDLE.
ROOT : EXECUTING (start)
ROOT (end)
- at org.knime.productivity.callworkflow.table.CallWorkflowTableNodeModel.executeInternal(CallWorkflowTableNodeModel.java:132)*
- at org.knime.productivity.callworkflow.table.CallWorkflowTableNodeModel.access$0(CallWorkflowTableNodeModel.java:112)*
- at org.knime.productivity.callworkflow.table.CallWorkflowTableNodeModel$1.call(CallWorkflowTableNodeModel.java:99)*
- at org.knime.productivity.callworkflow.table.CallWorkflowTableNodeModel$1.call(CallWorkflowTableNodeModel.java:1)*
- at org.knime.core.util.ThreadPool.runInvisible(ThreadPool.java:615)*
- at org.knime.productivity.callworkflow.table.CallWorkflowTableNodeModel.execute(CallWorkflowTableNodeModel.java:96)*
- at org.knime.core.node.NodeModel.executeModel(NodeModel.java:567)*
- at org.knime.core.node.Node.invokeFullyNodeModelExecute(Node.java:1192)*
- at org.knime.core.node.Node.execute(Node.java:979)*
- at org.knime.core.node.workflow.NativeNodeContainer.performExecuteNode(NativeNodeContainer.java:559)*
- at org.knime.core.node.exec.LocalNodeExecutionJob.mainExecute(LocalNodeExecutionJob.java:95)*
- at org.knime.core.node.workflow.NodeExecutionJob.internalRun(NodeExecutionJob.java:179)*
- at org.knime.core.node.workflow.NodeExecutionJob.run(NodeExecutionJob.java:110)*
- at org.knime.core.util.ThreadUtils$RunnableWithContextImpl.runWithContext(ThreadUtils.java:328)*
- at org.knime.core.util.ThreadUtils$RunnableWithContext.run(ThreadUtils.java:204)*
- at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)*
- at java.util.concurrent.FutureTask.run(FutureTask.java:266)*
- at org.knime.core.util.ThreadPool$MyFuture.run(ThreadPool.java:123)*
- at org.knime.core.util.ThreadPool$Worker.run(ThreadPool.java:246)*
- Suppressed: java.lang.NullPointerException*
-
at org.knime.core.node.workflow.WorkflowManager.disableNodeForExecution(WorkflowManager.java:2100)* -
at org.knime.core.node.workflow.WorkflowManager.disableNodeForExecution(WorkflowManager.java:2038)* -
at org.knime.core.node.workflow.WorkflowManager.cancelExecution(WorkflowManager.java:5051)* -
at org.knime.explorer.nodes.callworkflow.local.LocalWorkflowBackend.close(LocalWorkflowBackend.java:398)* -
at org.knime.productivity.callworkflow.table.CallWorkflowTableNodeModel.executeInternal(CallWorkflowTableNodeModel.java:140)* -
... 18 more*
Do you have any idea on how to prevent the following nodes go to idle on an error? Is it a bug in KNIME 4.0.1?
Thank you for your help in advance!