Hi There,
I am trying to built splited decision tree model for each segment (the segment value located in feature)
for example - if in the feature there is 10 groups now, the model will create 10 different models. if after some work the number of the segment reduce to 7 segment - the model will create now only 7 different models.
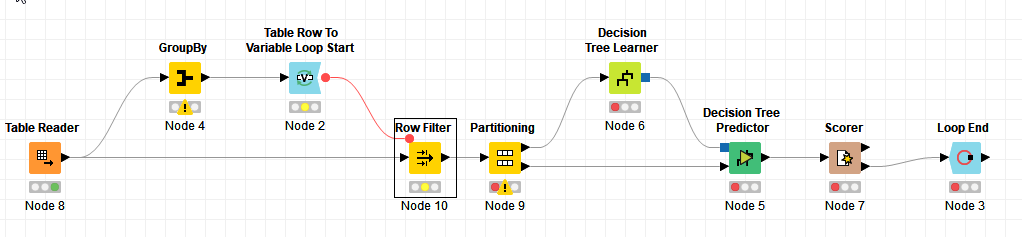
In this workflow you use the GroupBy node on the feature of interest, and then loop over each of the identified segments, filtering on each individual segment. For each subset of the data, a decision tree is made and scored. The key is the use of the Table Row to Variable Loop Start node.
So now, I build specific tree for each segment. the next step is to rank each segment testing set with his model. I saved with a row key each iteration and now I need to create PMML files that will use for each segment.
can help?
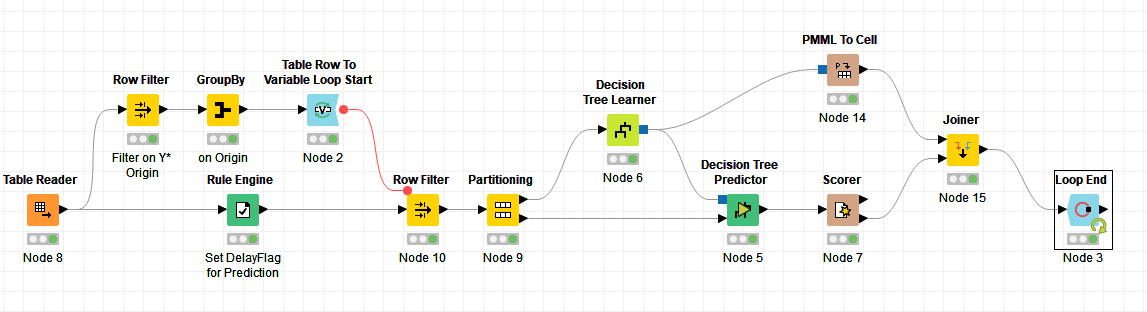
@Einavtam Sure. All you need to do is add a PMML to Cell node to store the model for each segment, and join that with the results of the Scorer node inside the loop.
If you wanted to take things further, you could use a combination of the Sorter and Row Filter nodes (not shown) to select a subset of the best models.
EDIT: It occurs to me I left something out. If you need the PMML files explicitly, you’ll want to use a Cell to PMML node after selecting the model you want, and also a PMML Writer node to write to a file.
First, instead of the groupby, the table row to variable loop start and the row filter, you can also use the group loop start node, does the same thing, but it is faster.
second, if you want to keep the model to later use it in real deployment for unseen data, you train the decision tree learner on the full data set again, after you did the partitoning.
An example for the later you can find on the example server knime://EXAMPLES/_Example_Workflows_from_Installation/Customer%20Intelligence/Credit%20Scoring/Building%20a%20Credit%20Scoring%20Model
when you are in the phase of evaluating your model you split into training and test. So you have labeled test data to see how well your model performs. Still this data was not used for training.
If you want to deploy your model to predict really new data, you retrain it on the complete data set. Each data point you leave out could decrease your modelling.
Would it be possible for you to provide the sample dataset used in this workflow? I have tried running this workflow on my dataset but it does not work, so I am just trying to see where I went wrong.