Hi @Data_consumer , that’s looking good. If you are able to upload the workflow, I can take a look. My suggestion though would be that after the duplicate row filter , you establish the list of possible “top level” parents. You can do this by joining output from Duplicate Row filter (to itself), and joining on Investor = Investee, then keeping only the Left Unmatched entries. These are Investors that are not Investees and are therefore the set of “top level”.
yes… That should give you a table containing:
| Investor |
|---|
| ID 1 |
| ID2 |
| ID3 |
and then you can do something with that such as join back your final results table and keep only where ParentID = Investor. Then a Cell Splitter to turn the Concatenate into columns, and you arrive at the solution I think (although might need some adjustments to the recursive loop… ).
I used that idea in my own workflow, as I was quite interested in how @tobias.koetter’s network node and component suggestion worked in his reply.
[btw I still don’t know how they work, but then again, I don’t really know how my computer works either, but I can live with it. lol]
So here is what I have
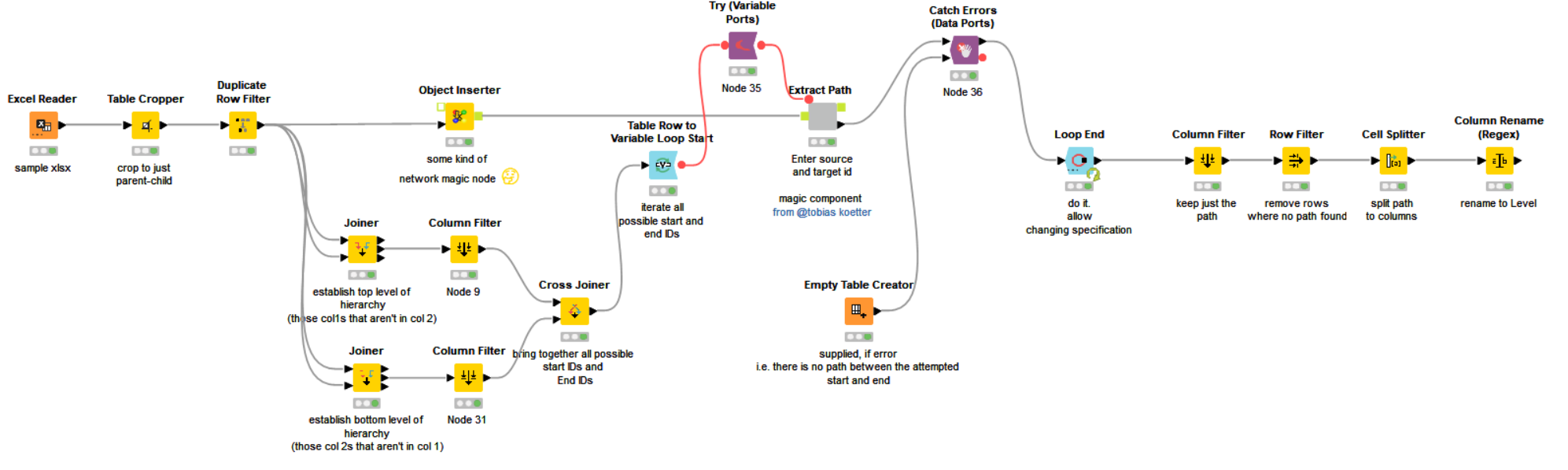
which I think works except the columns start at Level 0 instead of Level 1 [so total failure in meeting the specification!
hierarchy builder.knwf (64.7 KB)
Anyway, please upload your flow if you want me to take a look. Two solutions are better than one!!