So … I had a chat with a friend… it went like this:
If have a table of data consisting of UnitID and DeviceID
e.g.
Unit ID Device ID
267.001.2 S1005215
267.001.2 S1005216
267.002.2 S1005215
267.002.2 S1005216what algorithm could I use to return the largest number of rows that does not contain a repeated Unit ID or Device ID
and my friend (ok, it was chatGPT) replied:
“To find the largest number of rows that do not contain a repeated Unit ID or Device ID, you can use a graph-based approach. You can represent the relationships between Unit IDs and Device IDs as a graph and then find the largest set of rows that do not share common nodes (Unit ID or Device ID).”
It then presented me with some python, which I decided not to use because I wanted to find some non-python way, at least for now…
but what it did also say was this:
This code creates a directed graph where each row in your data is represented as an edge between Unit ID and Device ID. It then finds the largest acyclic subgraph using the connected components of the undirected graph. Finally, it extracts the rows corresponding to the largest acyclic subgraph, which represents the largest number of rows that do not contain a repeated Unit ID or Device ID.
That seemed interesting, so I went searching for KNIME “acyclic subgraph”, which led me back to the “network” / “subgraph” nodes used here:
and here
and that ultimately led me build a workflow that it would be good to try out with your data, because I have no idea if (or how!!) it works ![]() I suspect @tobias.koetter might be able to tell us!
I suspect @tobias.koetter might be able to tell us! ![]()
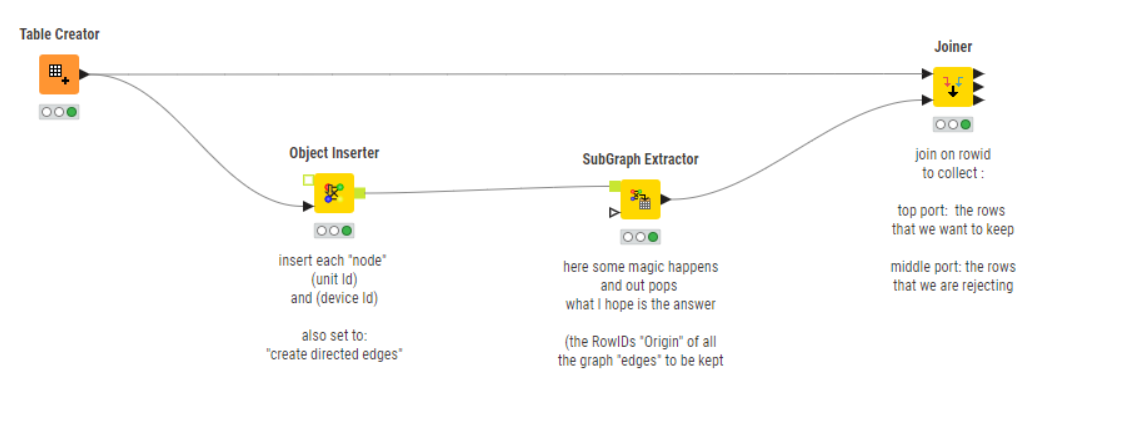
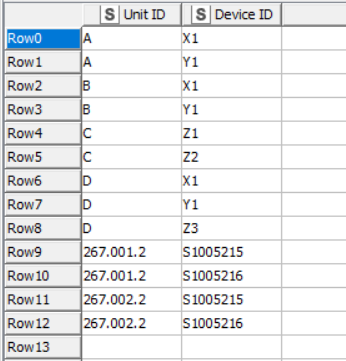
What I can tell you is that given this input:
it returns the following output (rows to keep)
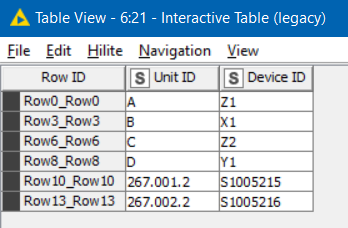
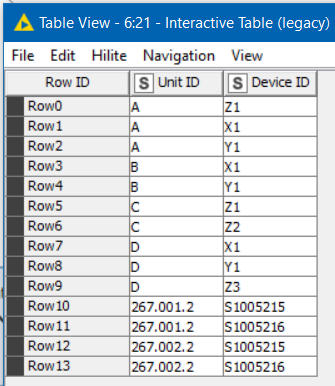
and given this input:
it produces this output:
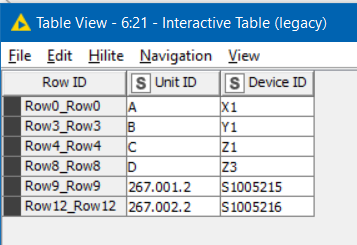
That appears right to me!
remove duplication in two columns.knwf (82.7 KB)
Will be good to know what happens with the “real” data.
btw Anybody interested in the python code that chatGPT generated for this can find the chat here