Your problem is the same as the one solved in this other thread:
Your data can be considered as a table of edges of a relational graph. A relational graph is made of nodes and edges. Your letters from “a” to “g” are the nodes. Your Table rows are the edges between nodes: for instance first row says “a is connected to b”. What you want to find is the beginning and end node of a set of connected nodes, i.e. a path leading from “a” to “d”. Btw, your 3rd column is the name of the path: for instance path x is “a-b-c-d”.
The thread given above should thus be a solution to your question.
Hope this helps. Otherwise please let us know and we will be happy to help.
I checked the other solution and I think I need something very similar. I had a similar idea to what @ipazin proposed by using cell replacer. The issue I have is that I don’t know how to take the 3rd column into account. Let me use another example here.
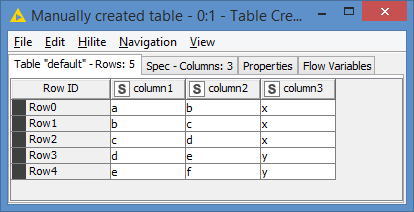
col 1|col 2|col 3 a | b | x
b | c | x
c | d | x d | e | y
e| f | y
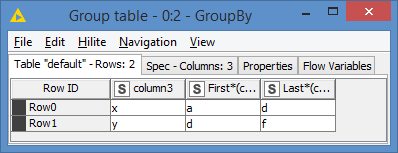
The expected outcome is the following
col 1|col 2|col 3 a | d | x d | f | y
As you see, the third column defines the start and end of the path. Without it, there is only one path going from a to f.
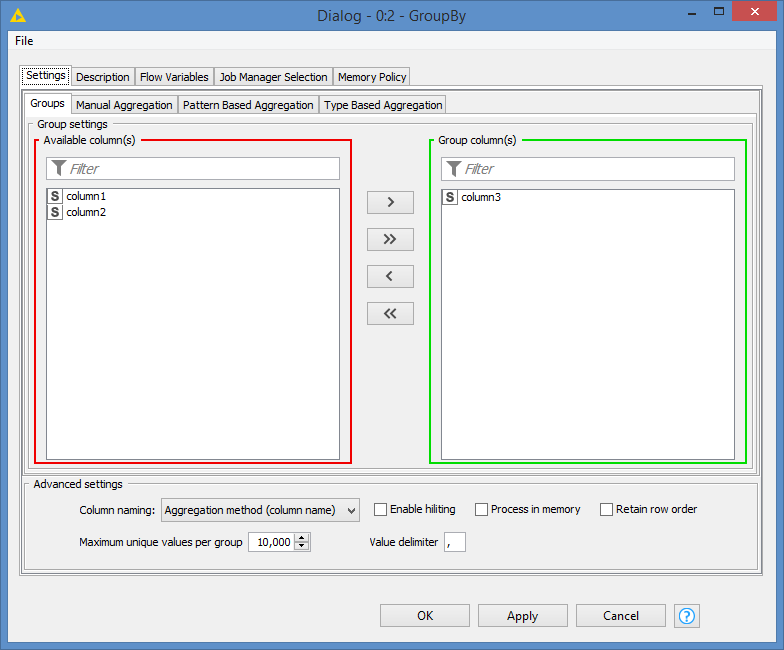
Interesting ! It happens that your label is already splitting your relational graph into subgraphs, so if instead of giving all the rows to the workflow that I previously suggested, you give them to the workflow by chunks, then the problem should be solved. Every chunk should only contain the rows of the same label in col 3. For instance:
1st chunk → Label x
2nd chunk → Label y
…
and so on so forth. Thus the solution here is to use an extra chunk loop to deal with separate subgraphs.
Thanks @aworker . Sorry I could not get back sooner. That was a great idea and worked well. I get the rows with same values in col3 in the outer loop and then go through the targeted rows with the inner loop.
I just use “Table Row to Variable” node for defining the number of loop iterations but it has become deprecated. I think the substitute for this node is “Java Edit Variable”. Could you please explain how it works? Or guide me to the right place (preferably with an example)?
Deprecated nodes in KNIME still work just fine - it’s just an indication that there’s a newer version of the same node that you may want to try out (maybe it has additional features, or executes more quickly).
It doesn’t mean that you should switch to an entirely different node, that’s for sure
It works because the relationships are between letters that are sorted:
a → b
b → c
etc …
It would not work if the relationship were between not sorted letters, for instance:
a → c
c → b
b → e
… etc.
I thought the problem was generic, as in the latest example, and not just for the case of relations between sorted letters as in the former example.
So definitely the -groupby- node solves the problem in this particular case but (i still believe) it doesn’t solve the generic one of -relations between non-sorted letters-.
In other words, my solution was more generic. But if @hmd_pouya’s problem is only for -relationships within sorted letters- then @Daniel_Weikert solution is perfect.
Hope this clarifies my previous sincere comment to @Daniel_Weikert.
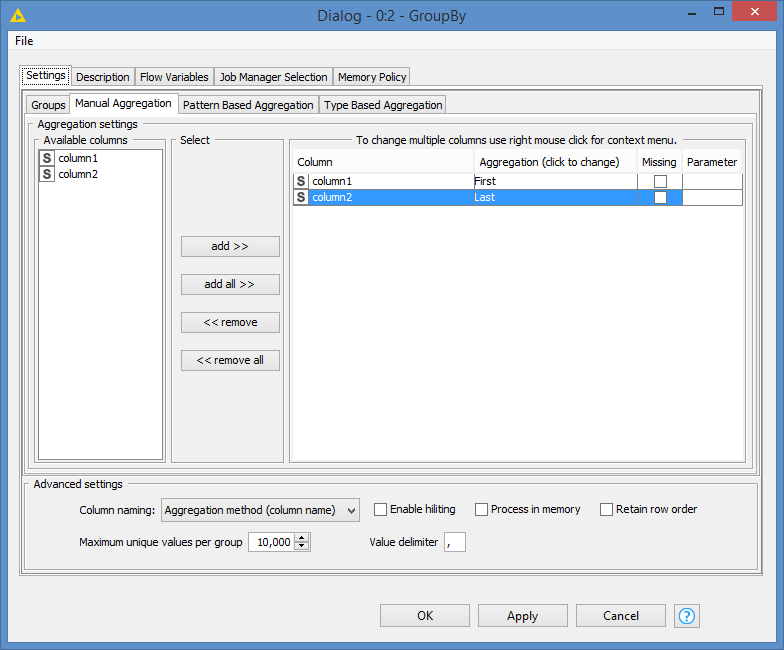
Hi @aworker , right, that was the only “weakness” I could think of, but I think first and last does not rely or sorting the data alphabetically, but rather in which order the data is.
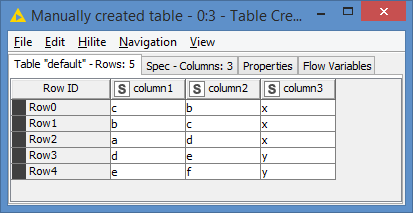
For example, look at the following input data (I swap a and c in column1):
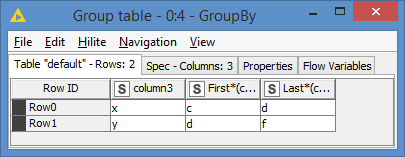
If I run the same groupby, I get this result:
c was indeed the first record. It’s not sorting the column to detect that a was first.
Still your example is again a special case. To put it simple: If in every chunk, first letter in first column is the first expected letter and last letter in the 2nd column is the 2nd expected letter, then the groupby works. The solution I provided is generic: it works regardless of the order of the letters or/and the rows.
I think I missed what you were saying, and also what has been said through the thread.
To your point, you are seeing a relationship a->b->c->d, etc… I don’t think there is any relationship. I think that was more a coincidence in the sample (@hmd_pouya should confirm if there is any link/relationship there). To me, I thought @hmd_pouya only wanted to know the first occurence from col1 and last occurence from col2 for the values of col3. I never thought that the data was linked that way.
IF the data is linked to each other, then I full agree with you, that the groupby would not work, at least it would not be guaranteed to work in all cases.
Thanks @bruno29a for your last email and understanding of the point. It is exactly what I thought and that’s why I suggested this generic solution for perhaps a very simple -groupby- problem.
Definitely only @hmd_pouya can tell us what it is really his need. It seems that the -groupby- fullfills his need so the simplest the best !
Still I think the generic solution will help other people to solve more generic problems if they land on this thread in future …
The problem is simple. There are some paths and the links of each path has the same key. The letters show start and end for each link. I just want to find the start and end of every path (every unique key). The links are in order.
col 1|col 2|col 3 a | b | x
b | e | x
e | d | x e | m | y
m | c | y
In this example, I look for a->d with key “x” and e->c with key “y”. Your solution was flawless and what @Daniel_Weikert suggested was simple and right to the point needed for my use case.
 ! It happens that your label is already splitting your relational graph into subgraphs, so if instead of giving all the rows to the workflow that I previously suggested, you give them to the workflow by chunks, then the problem should be solved. Every chunk should only contain the rows of the same label in col 3. For instance:
! It happens that your label is already splitting your relational graph into subgraphs, so if instead of giving all the rows to the workflow that I previously suggested, you give them to the workflow by chunks, then the problem should be solved. Every chunk should only contain the rows of the same label in col 3. For instance: