Hello,
I have a time data series that is not uniform (values are taken at arbitrary intervals).
I want to calculate the average value per hour. How can I do that? A Group By node will calculate the mean value of all the measures in a given hour but it is different from what I need.
Thank you and sorry for the dumb question (im new to knime!)
Hi @ArjenEX . Thank you for spending time answering my question. Unfortunately a group by node is not enough because I do nothave constant time intervals between measures. I don’t need the average of every single measure, but I have to take in account the time spent between measures. Immagine having a measure every 10 minutes and at some point 10 repeated measure at a very short time intervals. You cant average all together.
Can you manually draft your expected output then in terms of data?
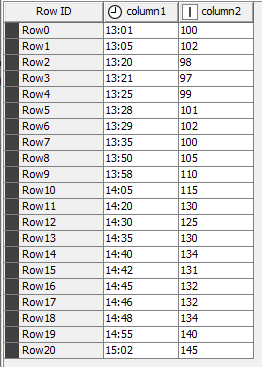
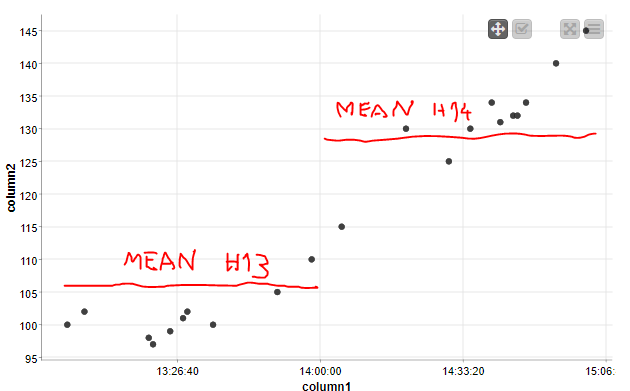
Based on the image in your original post it looks like you want the average of all records that have a certain base hour (13,14, etc.) but your second reply confuses me.
Are you trying to predict the value at a certain time during that hour or something?
I am also confused by your description, but I will often apply a calculated “weight” multiplier to granular data (but in a much different application). Just throwing out the general idea of scoring the values (with unchanged =1) and then multiplying them by their scores weights as a possible way to build a more complex approach… Just taking a shot in the dark.
Sorry for the confusion. I will try to meke it clear by an example.
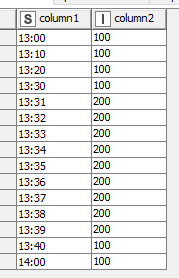
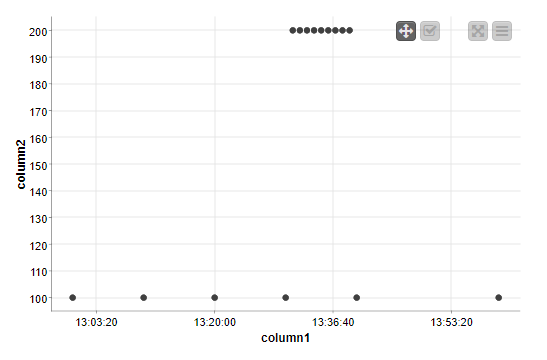
Let’s say I have readings of a car speed over an hour, as following:
The car run at 100 for the whole hour except five minutes at 200.
Now I want to calculate the average speed of the car during the hour. By hand the result is something around 108, but if i average all the readings I get 160 which is not what i’m looking for.
In that way the average value of the groupby node is not enough.
Hi @Olivier_G,
the reason for your problem is that your data are not equally distributed (time frames). Therefore a simple averaging doesn’t give you the correct result.
(10/20 mintue blocks for speed 100, 1 minute blocks for spped 200)
Descriptive statistics takes the number of data points in account not the delta (distance) between the datapoints.
You can think about to calculate the absolute driven route for each time point and sum them up.
@morpheus is right, you need take into account the sampling intervals (or time frames) because data is not equally sampled (hence distributed).
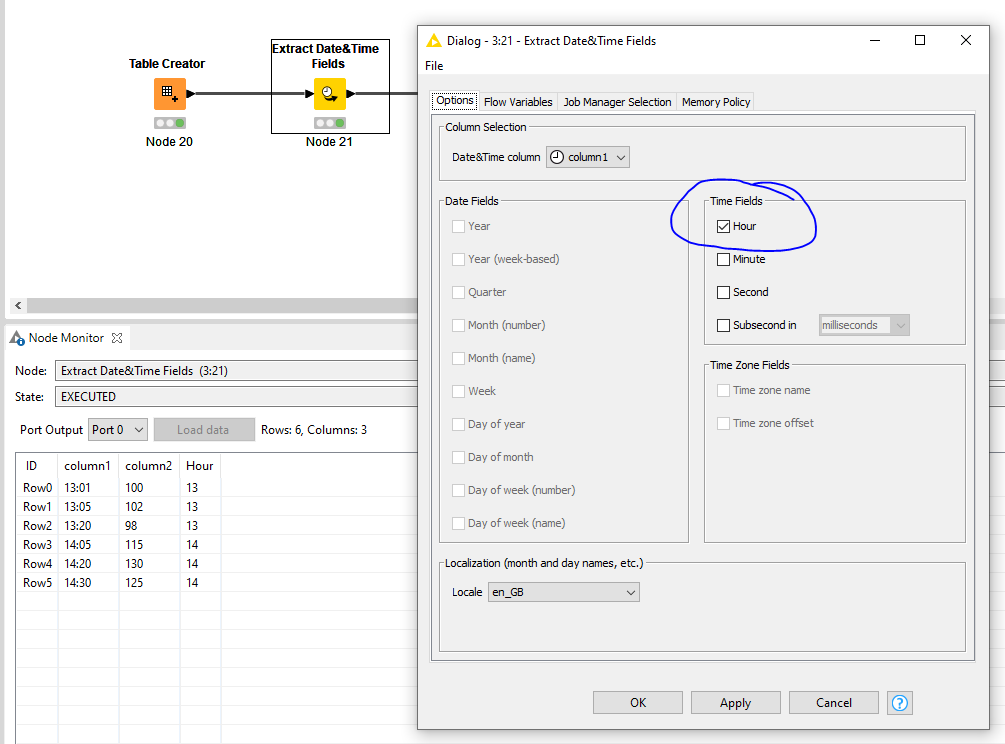
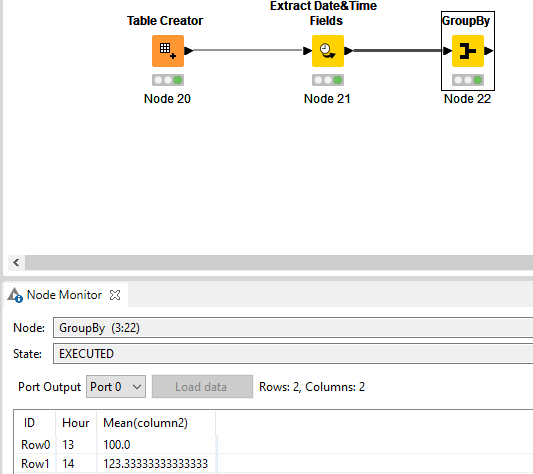
There are different ways this could be solved using KNIME.
Could you please upload here a bit of your data so that we can take the problem from there and provide you with at least a solution adapted to your data ? Thanks in advance.
The way I have handled things like this in the past is as I described above. You could use the lag node to drop down the prior value, then calculate the interval, then use that to create a weight multiplier for each recorded value to use in the average calc.
Sure,
Here is the actual data I am working on. It is the status of 3 industrial machines (1= machine running, 0 = machine stopped). I need to calculate the AVAILABILITY value of every machine for every hour, that is the fraction of the time the machine was running (eg. 90%).
I like this approach. I could add a “duration” weight for every row and do a weighted average. Is there any way I can do a weighted average in the groupby node?