Hi I’m new to KNIME (switching over from 2 decades of SPSS & SAS).
I’m trying to create a new variable that is equal to the standard deviation across a range of columns. I notice that I can use the math formula node to do this for average and other measures. But I can’t find standard deviation. Note that this is NOT a group-by situation as I want to create a new column in the dataset.
the Statistics node and the Data Explorer (JavaScript) node creates a new table with some statistics, including the standard deviation for all numerical columns. With a column filter node and a row filter node you can extract the information you are interested in.
If you want to add a new constant column with the standard deviation to the original table you can use the column appender node and control the constant value with a flow variable.
I don’t think that will work. I believe your response speaks of calculating standard deviation within a column. I need to calculate within each row across a range of columns.
I’m working with online survey data and I need to eliminate respondents that clicked through an entire bank of questions giving the same answer for each question. The way to do that is to calculate the standard deviation for each respondent (row) across a selection of columns. Then filter out those with sd = 0.
Hoping you can help
I feel I need to ask the obvious question… why isn’t this feature simply in the most obvious place - the math formula node - along with it’s peers like “average”? It seems odd that it isn’t there.
Dear Kathrin,
I have the following situation: I am working with COVID data, and at this very moment I am facing some issues with optimizing the PNN algorithm as a function of Standard Error.
After (a lot of) hard work processing my workflow, I reached the point to apply the PNN learner. The input data (with data grouped by municipality and month returned me a dataset with 182 rows) were stored in an XLSX file as follows: Input data for PNN.xlsx (11.2 KB).
I wish to apply the loop for Parameter Optimization (Start and End nodes as flow variables for PNN Learner and Predictor). I tried to apply some parameters as ‘number of hidden layers’ and ‘number of hidden neurons per layer’ in the Start node, but I didn’t reach (yet) how to optimize including what I most desired, which is the Mean Standard Error as a parameter to be minimized (by the Loop End). The inconvenient aspect is that the Mean Standard Error (i.e., the distance between the predicted value and the real value) just could be found with the values attained after the PNN Prediction is executed. I thought about following what you suggested in the conversation above (possibly with the Statistics node and column filter node). Therefore, I didn’t realize how to implement this parameter into the Loop Start node.
I hope I made myself clear in what I am currently searching for. Otherwise, pleases let me know if my doubt needs additional clarification.
So, can you help me? Or would you mind suggest me anyone that could enlighten me about the resources needed for calculating the Standard Error and use it as a parameter?
Thank you so much.
Best regards.
Rogério.
Dear Kathrin,
I am currently facing a new problem (arisen this dawn), which is forbidding me from sending you my current workflow and the related problems with PNN configuration (the last remaining step on the tasks for my project).
I posted about this problem here, on the Knime.forum. It is related to free disk space for my temp file on c:\ partition. Indeed, a couple of years ago, I reformatted my hard disk, designing: a d:\ partition for programs; an e:\ for documents; and reserving a small amount of space for OS (Windows) in c:\ When I installed Knime, I tried to install it all on d:, and to save my workspace and all the related files and workflows in e:\ I haven’t even decided to work or to store any small part of my work in c:\ partition. As far as I know, I haven’t opted for any work or storage there…
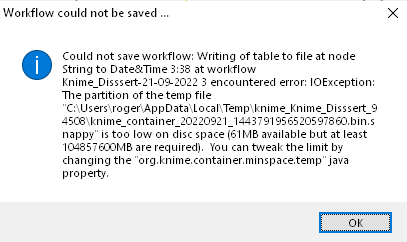
After several weeks of hard work on my project (for my master thesis), it all was going pretty well and effective on all my proposed steps. But a couple of hours ago I received this message:
Since then, I cannot save anything else, any workflow or additional steps… I tried: cleaning the temp file, uninstalling and reinstalling Knime, and tried all the alternatives that occurred to me. But, after a couple of hours, nothing is working well for saving my workflow or any step or node.
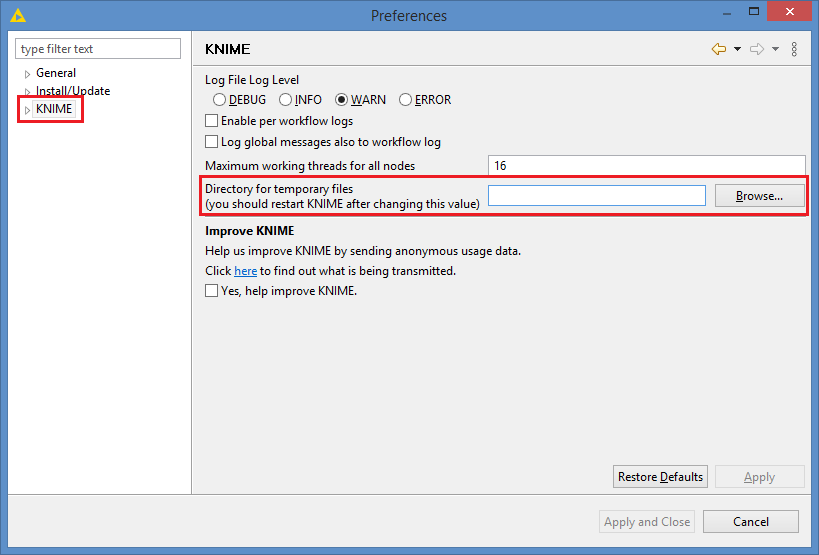
Can you refer me to someone (for instance, on the Knime Community) who could help me on changing this temp file from c:\ to d:, where I have a lot of free space? Or any other practical measure for enabling me to return to work on Knime? At the end of the day, over these several weeks, I have made a (relatively) complex workflow to unify all the needed steps for implementing all the tasks related to the KDD process I planned to reach. Right at the last task (the PNN branch of my workflow), all of it is not reachable anymore for me.