i have uploaded a file regarding an average Problem that i have.
It’s about me wanting to pattern my customers. An important point here is the sum they spend on counterparties (column Amount). An important key figure that has to be checked is the amount. At the beginning of a transaction it should be checked whether it is a suspicious payment. As you can see in the file we have e.g. the company Aksu GmbH. Aksu GmbH has two customers. Both customers have different amounts in their history. In order to determine outliers, I would like to calculate the average on the basis of which I later query run. If it is within the range of the average value, the transaction is let through, otherwise it is rejected and must be checked manually. Do you know how this could be done? Because in the next step I would like to do a pattern analysis and the field amount is not always the same value I have to do it differently, so I hope you can help me.
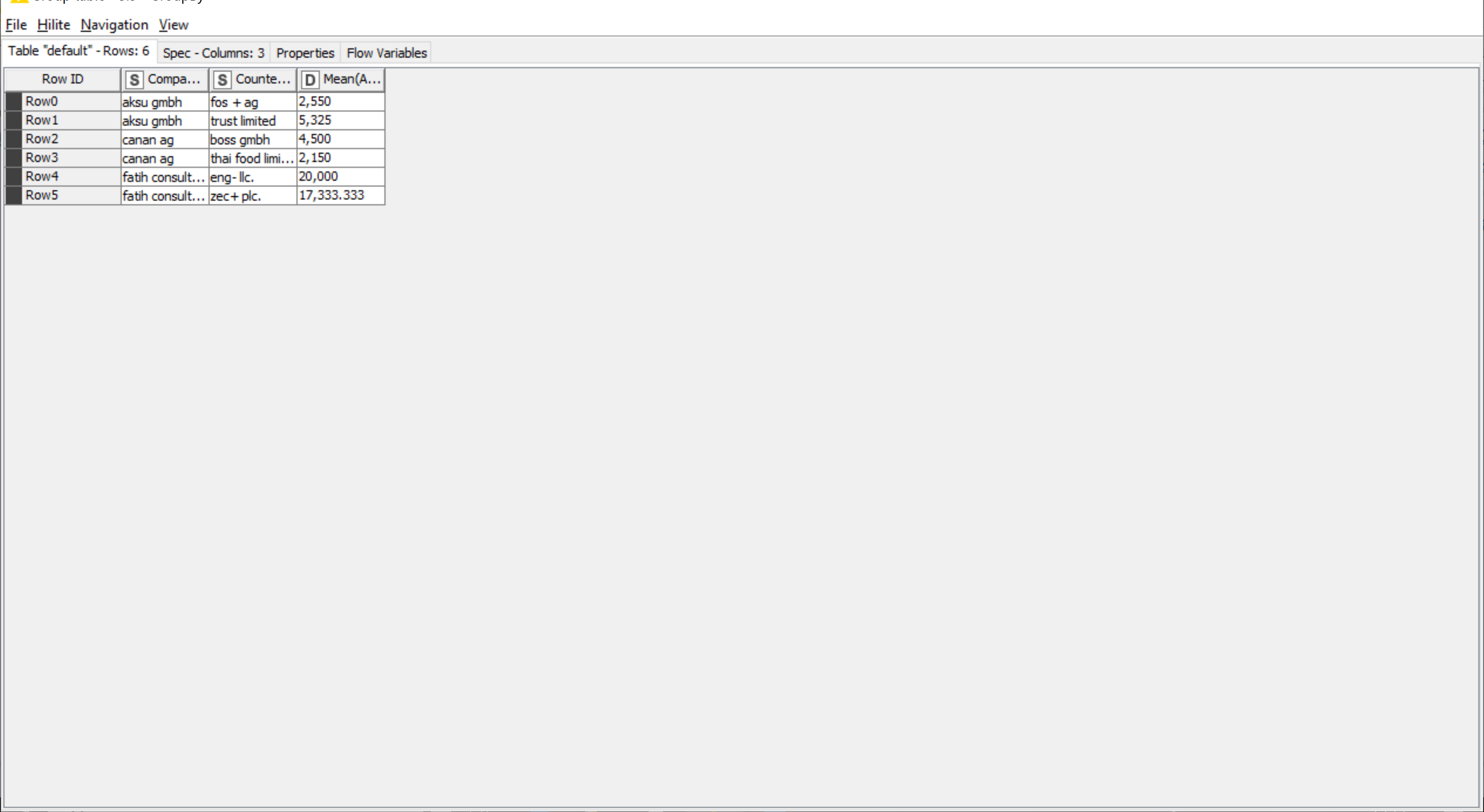
sounds to me like you need the GroupBy node. In the Group tab you choose the company name, in the Manual Aggregation tab you choose the amount and the measure you want to take (mean, median, sd…).
I would now like to use the value for future transactions. For example, the average for aksu GmbH and fos+ag is 2550. The lowest value was 2300 and the highest value 2800. If a new transaction comes in in the future, I want it to be within this range. If it is an outlier and the sum is too much higher than the average, such as 4000, then this transaction should be marked as a red flag. How can I do this Kind of check?
looks right to me (depending on your ultimate intention).
You basically have different options, depending on what you define as outlier. If you just consider everything outside the current range as outliers, you shouldn’t go with the mean but rather with the min and max, followed by a Rule Engine which tests for your new data if it is within the range. Or if you do a six sigma approach, you’d use the standard deviation (multiplied by 6). Or if you want to follow a more scientific approach, you could use the Numeric Outliers and Numeric Outliers (Apply) nodes, which implement widely accepted techniques to identify outliers…
You see, there are many paths to treat (and I listed just a few common ones), you need a very clear definition of your goal in order to choose the best one…
I have tried to build a workflow, but i am not sure if this is correct. AVERAGE.knwf (61.7 KB)
The first Excel Sheet uses the average, min and max that was calculated on the Basis of “historical data”. And the second Excel sheet is the sheet where i have to decide whether it is a outlier or not.