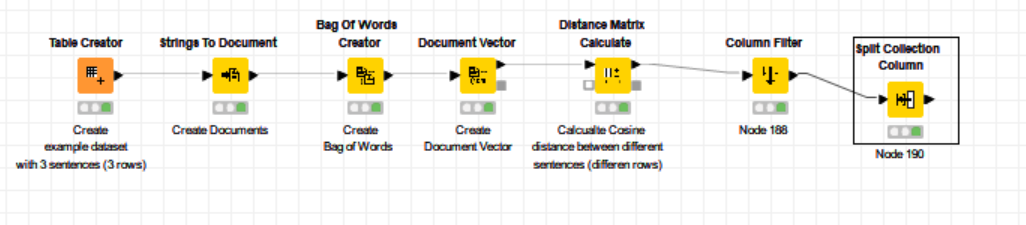
I have created some sentences and wanna find similar sentences. I used cosine similarity and it is very weird because those sentences have nothing in common, but the result is that they are perfectly similar (cosine similarity = 1). Why? I dont get this. When I use python and scikit-learn library it works well, but here something is wrong.
Hi,
Here it is not a similarity but a distance. A distance of 1 means the sentences are as far away from each other as possible. The similarity would be 1 - distance.
Kind regards
Alexander
Hi,
Creating such a table is possible, but may be a bit time consuming. Do you really need the full distance matrix, or are the k nearest neighbours in B for each document in A maybe enough? Because then you can use the Similarity Search, which is quite quick.
Kind regards,
Alexander