Hi, how can i configure the “Call Workflow (Row Based)” to keep all jobs, but not only the last row from input?
I have this settings:

Hi Karsten,
Thanks for posting in the forum. From the given node description, I would have expected this behavior with your configuration indeed. Let me reproduce and look into this, back asap ![]()
In the meanwhile, could you tell me the version of your Server executor please?
the executor version was 4.7.2.
Hi Karsten,
There is a known issue that has been resolved in AP version 5.1.2. What version of the KNIME Application Platform (local to your own computer) are you running? If it’s 4.7 or 5.1.1, you might find that upgrading to 5.1.3 or 5.2.5 resolves the issue. You can download those versions here. (Please also note that KNIME Server version 4.16 end of support will occur 6 December 2024.)
1 Like
Thanks for your replay currently i use KNIME 5.2.5 and i guess i have still the sma issue. Maybe you can try to reproduce it?
Hi @KarstenS ,
I’m very sorry, I misled you with my last message. I didn’t make it clear that the version of the Server Executor (SE) must match or be more recent than the version of the Application Platform (AP).
I am working on replicating the issue you’ve reported to make certain that behavior of the Call Workflow (Row Based) node is fixed in newer versions (because the known issue was reported with the non-row-based node).
What I should have told you was that there is a similar issue that has been resolved in version 5.1.2. Assuming that what you’re seeing is the same thing, you would need to update the KNIME Executor to version 5.1.3 or 5.2.5. to resolve the issue. (As a reminder, please refer to the Server Update Guide for this process.)
Going back to your original question, I think you might be expecting that the Call Workflow (Row Based) node runs separate jobs for each row. That is not what it does. All the row iterations are part of the same job ID.
If I’m understanding correctly, you would prefer to have separate profiles for each row of the input be accessible via the API afterwards. In order to have that information stored within the Server, you would need to have some sort of concatenated report generated by the caller workflow and accessible during the execution that corresponds to your final row.
Thy for your reply.
I want to see the data processed in the called workflow.
If i look on the server for me it looks like only the first call(row) is stored, where can i find the other rows that are processed?
BG Karsten
Understandable. In that case, you’ll want to either add some sort of report to the flows or rework the caller to do each run as a separate job.
Yes i want to noe e.g. why job 3 from 10 didn´t run(and see the used data).
Do you have a idea how i can do that?
After the fact, with the workflows as you describe them, you can’t access the information for any but the final iteration. Two changes you could make:
-
Add output(s) to your callee workflow so that it will write out information during each iteration.
-
Put the Call Workflow (Row Based) into a loop to run each iteration as a separate job. (You could also add an output to the end of that if you want the outputs in a single file.)
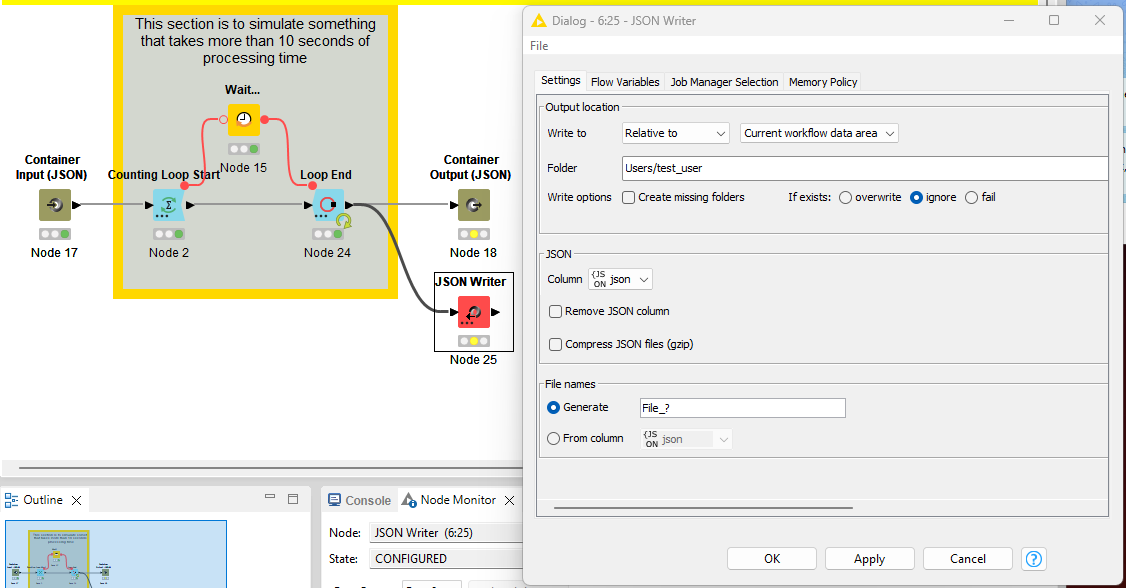
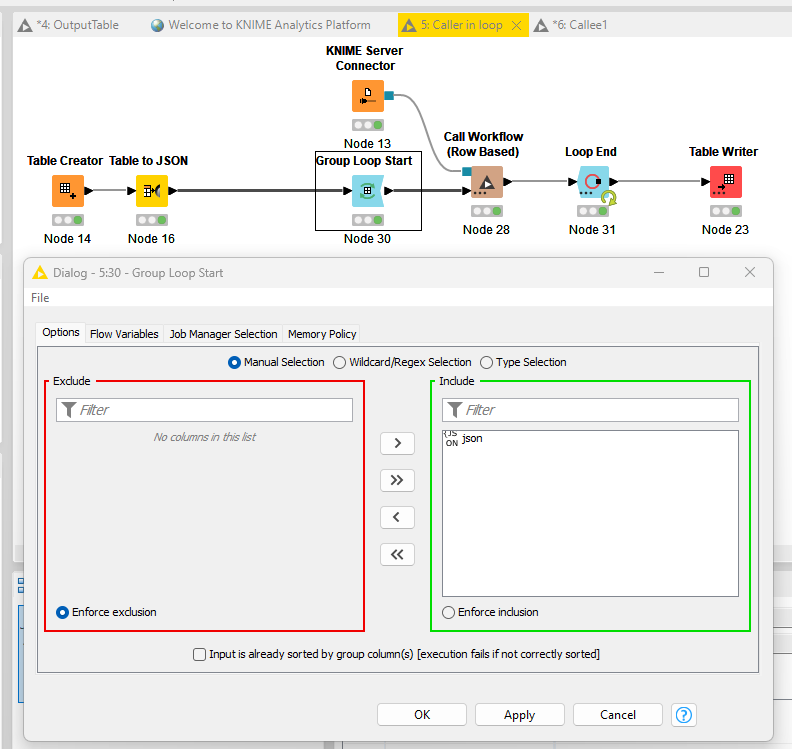
Callee.knwf (21.7 KB)
Caller in loop.knwf (18.2 KB)
2 Likes
Good Morning, that’s a nice workaround, thank you and have a nice day.
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.