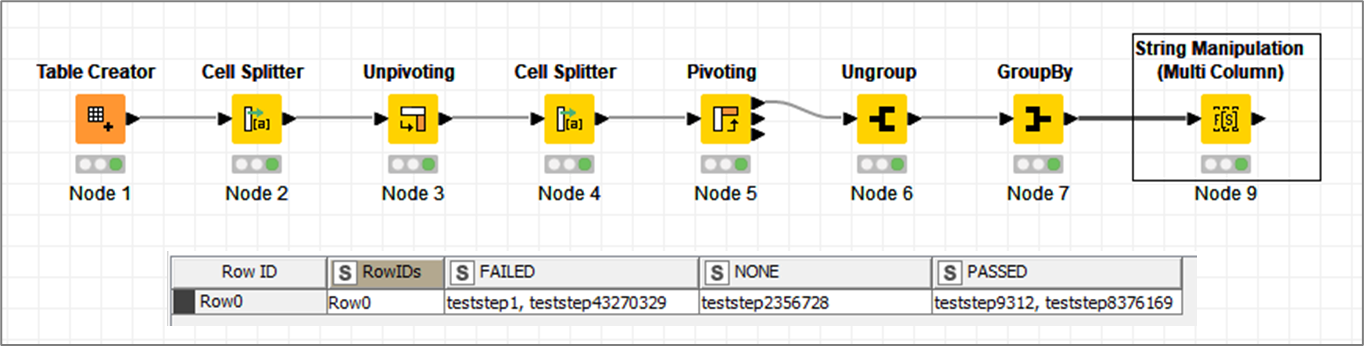
I have a column with the name: “teststeps+verdict” in which are my teststeps and the according values (passed,error,failed) in this style: teststep1__FAILED, teststep2356728__NONE, teststep9312__PASSED, teststep8376169__PASSED, teststep43270329__FAILED, …
I want to get two new columns: teststeps passed and teststeps failed/error. Can you give me the code for both stringmanipulation nodes?
Thanks for your help
Hello @simonmng
As @ipazin suggested Cell Splitter is a good option. But with comma as delimiter. Then unpivot resulting arrays, and validate FAILED/ERROR wildcards as a filter criteria.
Then you can use Cell Splitter with comma as delimiter, transpose your data and then use Cell Splitter as described in first post. That is under assumption I understood correctly how your data set looks like. In general it’s always a good idea to share part of your data. Dummy data works just fine
ok. Now it’s a bit clearer. If you want to use regex you can but using standard KNIME nodes is, I believe, good enough.
Here is regex for passed tests: (teststep\d+)_passed
And here is regex for tests that are failed or ended with error: (teststep\d+)_(?:failed|error)
I used Regex Extractor (for Output choose List) node from Palladian extension but maybe you can try it with some base KNIME node like Regex Split or regexReplace() function from String Manipulation node.