Hi,
we retrieve contents of a webpage to get a list of ID’s. We use a URL that looks kind of like this:
https://XXXXX-1.net/api/upload-history?projectId=XXX&authKeyXXXXXXXXXXXXXXX
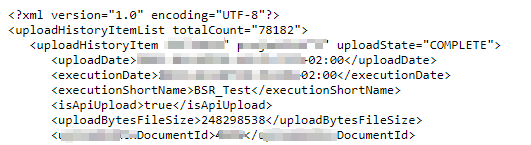
whenever I access this webpage via webbrowser or powershell I can extract the data in XML that I need. It looks like this:
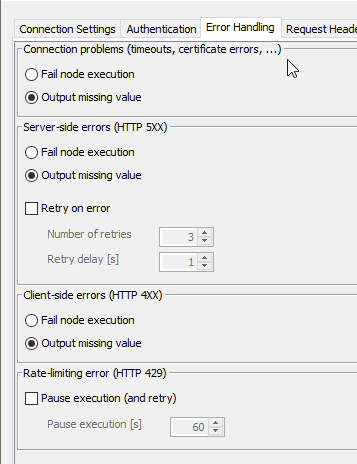
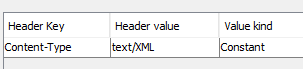
Last week we could also achieve this with KNIME using the Load text based files node by simply giving it the URL. However the admins of the URL seem to have changed something and now we cannot access the data via KNIME whatsoever. We also tried using the Palladian nodes (HTTP Retriever), that worked on an earlier build of our workflow but this does not seem to work either.
There is a parallel webpage running on an earlier server version where the Load text based Files node and all other ways to access it have been working flawlessly.
Further info:
- accessing the link with (different) browsers works
- accessing the link with powershell works
- website cannot be accessed with GET because it returns nothing (–> GET Request problem)
- tried other KNIME versions did not work
- tried the Palladian nodes (HTTP Retriever), does not work anymore
- tried using different Authentication Keys in the URL
- tried using Webpage Retriever node (never worked)
- tried the XML reader node with the URL (never worked)
- tried changing up the KNIME internet settings
I asked the server admins, but they did not know about any changes on their side, that should affect the url.
Does anybody know how I can extract the webpage content again? Is there maybe a way to change the user agent, whith which KNIME accesses URLs or something similar? Maybe that has to be updated.
Thank you for reading!