I am stuck at reading pdf files. I used PDF Parser Node first but after viewing the parsed document using Documents Viewer Node I got only the title and section heading but not the text in each section and subsection of the pdf file. Then I tried to access it using Tika Parser Node and got the same output. I am still very knew to KNIME. I read related topics but couldn’t find the exact solution.
Can anyone tell me how I can parse the whole content of pdf file? What I am trying to do is to read a pdf and perform some data cleaning (using Number Filter, Punctuation Erasure, String Replacer Nodes etc.) and store the document as csv.
May be I could get a link to somewhat similar workflow ?
There are several workflows dealing with PDF files on the Hub that may be of use:
That said, as @izaychik63 suggested, it might have something to do with your specific file. If you have a non-confidential, non-working PDF file you can post here, maybe we can check on that for you.
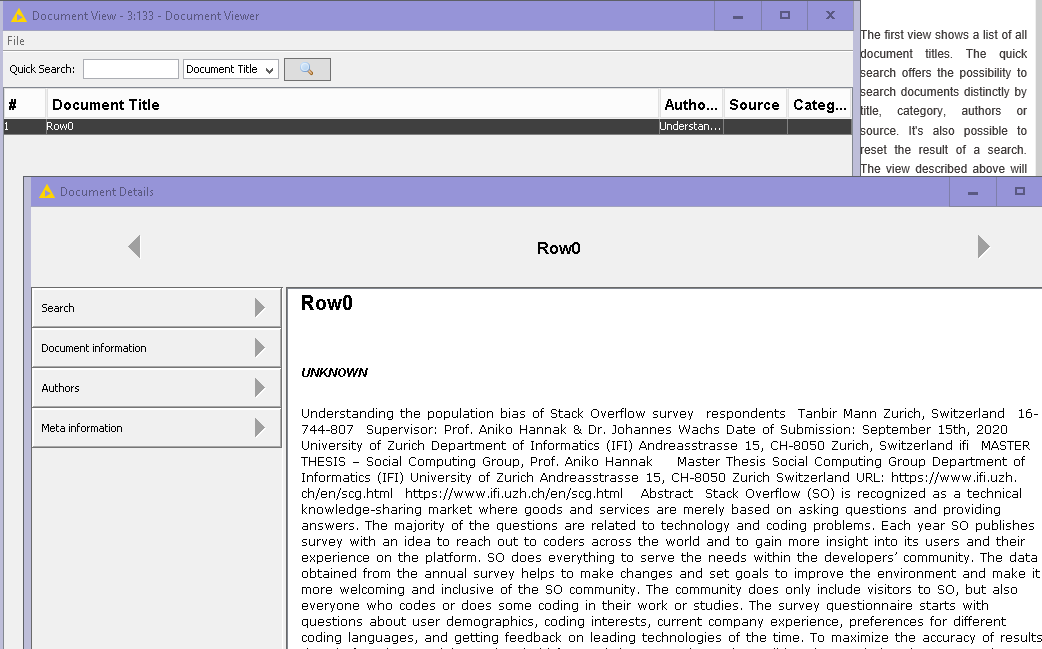
Everything is good with your document. After Tika Parser I Used Strings to Document node using RowID as a Title and open document in the Document Viewer
@izaychik63 Thank you it worked.
I can view the whole text. But, there is still some problem. When I view the document it shows two copies of the same text one in bold text format and other in normal text as in your above solution. Do you know what could be the possible reason for this ?