Hello,
I am currently building a model to try and predict sales numbers.
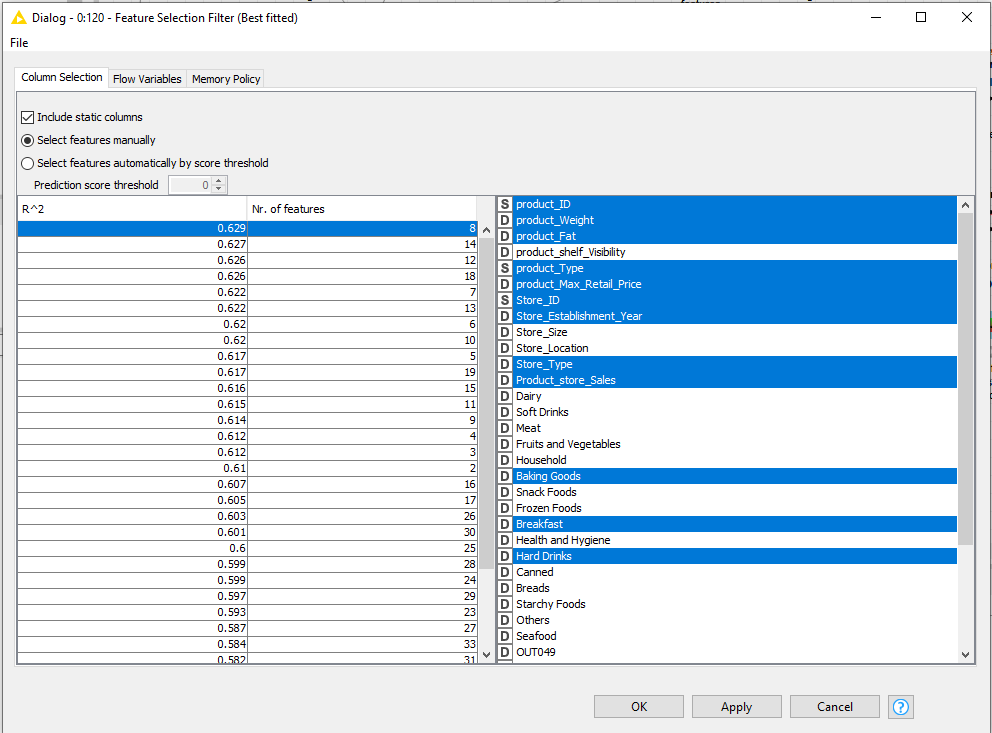
My problem is that when I make a feature selection loop, it shows me that the best r^2 is 0.629,
but when i put those features in the model again, i get a lower r^2.
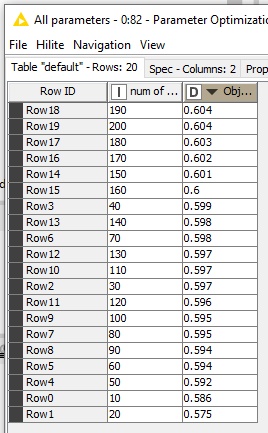
Also, The parameter optimization loop gets i lower as well.
Anyone have an idea why is that happening?
thanks!
Including the flow and data (changed from csv to xls in order to upload.
I’ve seen a few requests in recent weeks for help on class problems involving the Piggly Wiggly dataset. Do you mind sharing which class this is for, and who your instructor is?
We like to keep track of who is using KNIME in the classroom where we can. If you’d rather not share here, would you mind dropping me a quick note at scott.fincher@knime.com?
And if I can find some time later today, I’ll see if I can download your workflow and take a closer look.
The data in the excel file looks quite strange and not like a standard table and I have not inspected it fully. Since it seems to be the same data set my remarks in this thread might also be relevant for you:
First my obligatory rant about using the Feature selection loop. Simply said: Don’t. It’s borderline p-hacking. If you give a process enough degrees of freedom, chances are it will find some random “correlations”. And that is exactly what this loop is doing. On top of that it is often used wrongly (which is the reason for your issue) and a waste of power.
Why are you most likely seeing different results? well because the result depends on your train/test split. If you have a different split, your result (r2) will be different. Another possibility is that you have different hyperparameters which also lead to different settings.
Back to the feature selection loop. Besides the fact it’s a waste of resources, your doing it wrong. You will need to do a cross-validation for each set of features. Because else you optimize features for 1 random train/test split and not for the general data set. Using CV means runtime will increase even more.
So how should you select features? Well obviously by knowing about the problem domain. But besides that? Some partial automation? You must!!! filter out correlated features which KNIME offers the hand correlation filter node. Even decision trees (Random forest, xgboost,…) suffer from them. The after filtering correlated feature, I like to filter out constant/low variance features. For that they first need to be normalized (to 0-1). What threshold to choose in both cases depends on the problem but <=0.95 for correlation and 0.01 for variance seems to be a good starting point. Note that this is very fast to compute.
If you still have too many features after this, using Random Forest feature importance as a filter is also a good idea. Google it if you don’t know what it means. But basically you can then select the best n features or defined a cutoff how important it must be at least.
Note that all of the above needs to happen inside a cross-validation loop only on the training set. Because this process is part of your model!!!