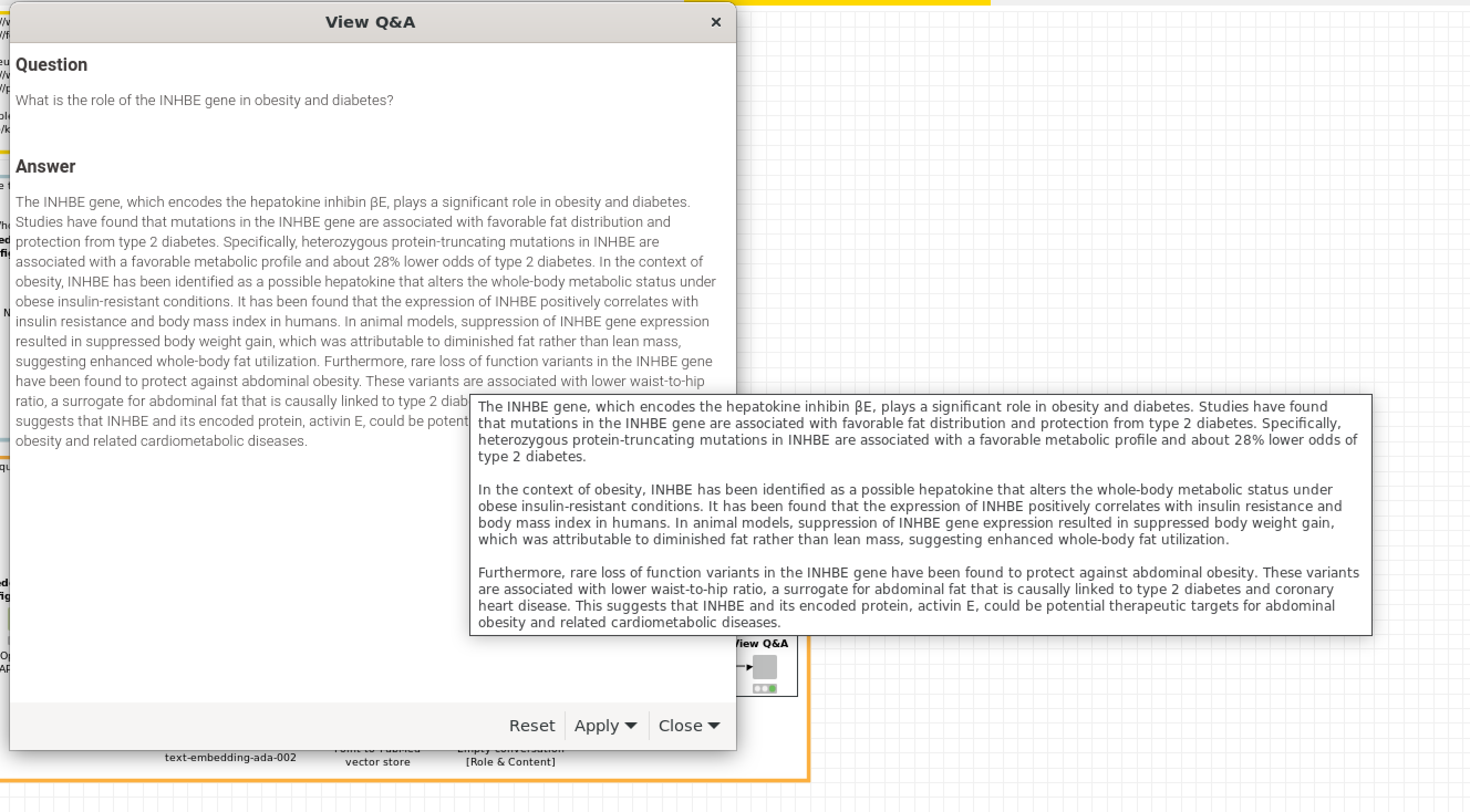
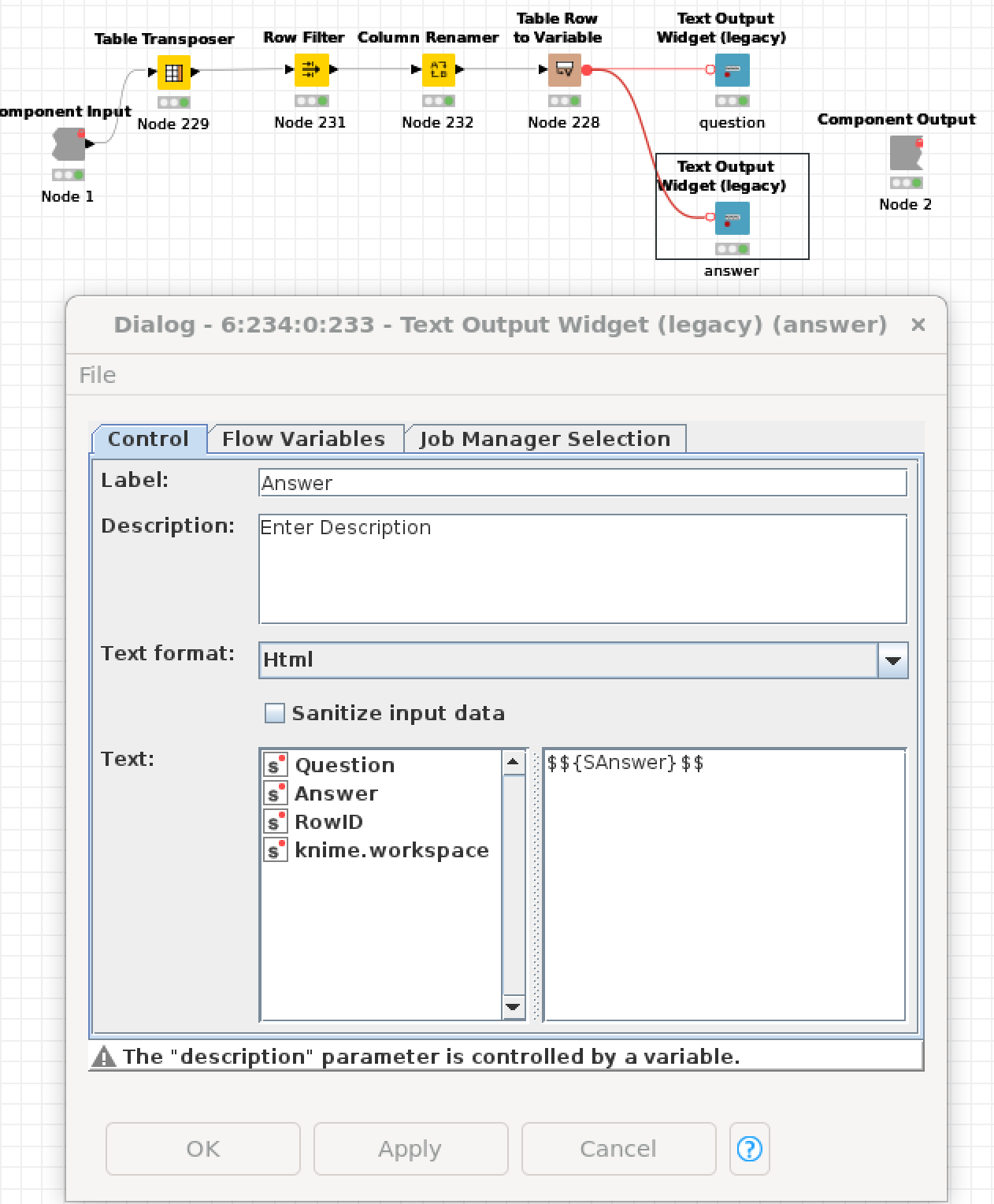
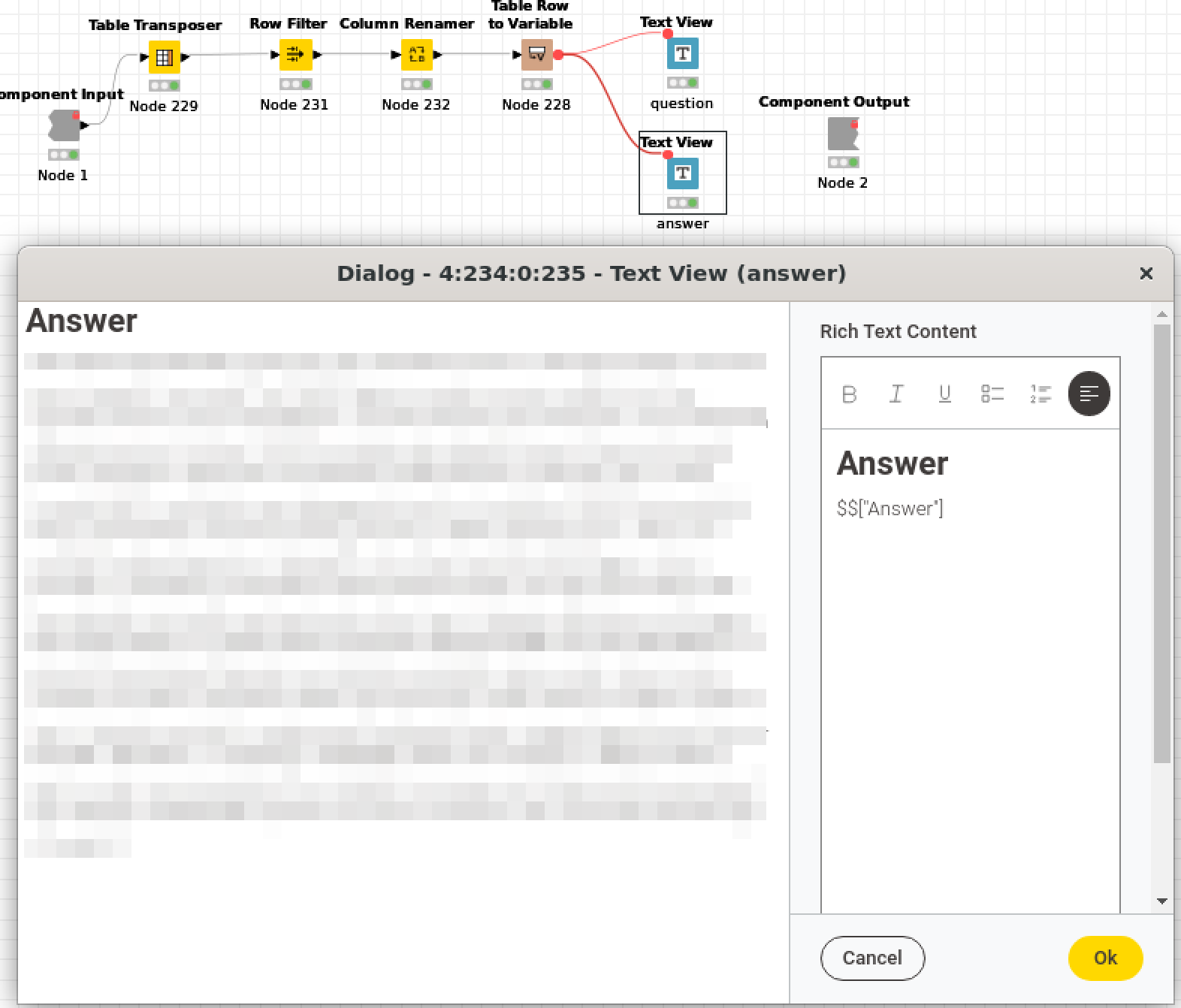
This question concerns how text appears in a Chromium view, or a full Webportal view, when using text nodes to display text. I’ve noticed that neither the Text Output Widget (legacy) node nor the new Text View node are able to render text with some features, like line breaks. Curiously, these line break do appear when I mouse over the text, but only when I’ve used the Text Output Widget (legacy) node, and not the newer Text View node. Any tips on what I might be doing wrong and how to display with formats like line breaks? I’ve included screen captures that show the general behavior, and how I’ve formatted each of the two different text node types.
Good morning @longoka,
something about your setup might not be correct. Here is my test workflow for reference:
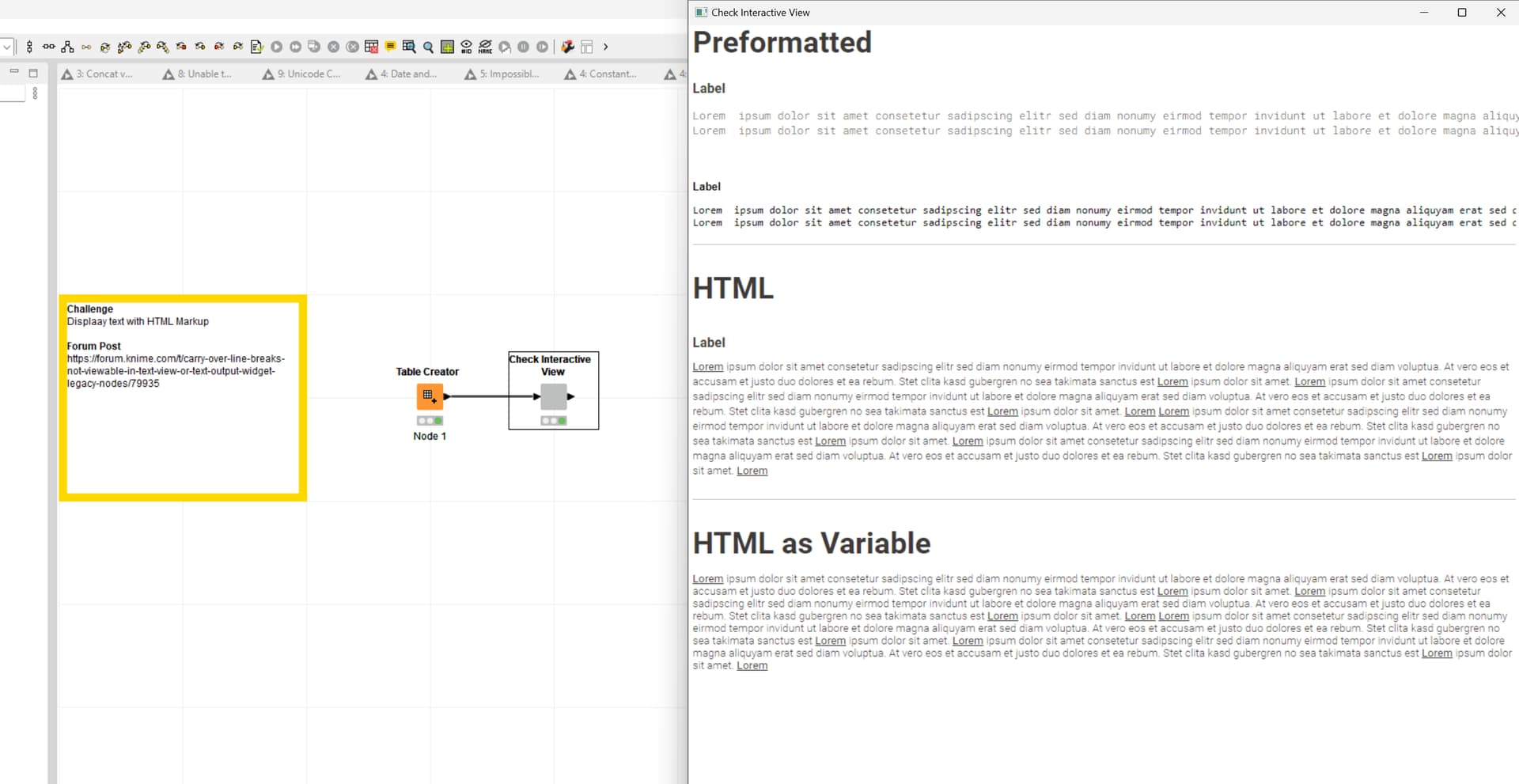
Let me know if there is anything else I can help with.
Best
Mike
1 Like
Thank you for your thoughtful response, Mike. I’m probably going a little too far down the rabbit hole, but I think what I’m observing in the data return from the OpenAI API is not explicit html formatting, but something more cryptic that I don’t fully understand. Playing around a little, I noticed that when I perform a URLencode of the answer text string returned from the OpenAI API using the string manipulation node, there is an ‘%0A%0A’ format (URL newline encoding) that appears to delineate the paragraph separations that I observed in the first picture in the thread above (see attached pic of the URL- encoded string in this message as well). There is something that is being interpreted when I hover over the text in that first figure. This is, in my view, the correct paragraph segmentation of the resulting text, and I’d like to exploit it more fully in subsequent view in Webportal. Theoretically, I can do some string replacement exchanging the URLencode elements with HTML elements, and achieve the same result as in your example workflow. But that’s a lot of work! I was just wondering if I was missing something obvious about ‘carry-through’ formatting, and not exploiting it correctly. Anyway, hope this exercise helps any others with similar questions!
Hi @longoka,
you are welcome and thanks for sharing the screenshot that cleared up a lot. %OA is unfamiliar to me but %0a. Checking the ASCII table %OA is also not found but the linefeed is:
https://www.eso.org/~ndelmott/url_encode.html
Have you tried, after decoding the HTML string to use the String Cleaner node?
You might also be able to use a RegEx replacing all characters of a certain class like \p{Z}, representing all whitespace characters, or more simply at least two following white space characters \s{2,} by just one.
https://www.regular-expressions.info/unicode.html
Cheers
Mike
1 Like
I finally figured this out; I discovered the answer on another thread. It really boils down to a misunderstanding on my part of how line breaks are actually formatted in the Text View node, and interpreted in Chromium (or any browser). The answer is to replace the line break “\n” with “
” in the String Manipulation node with:
regexReplace(column(“Column”),“\n”,“<br>”)
2 Likes
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.