I often use In my integration & data mining KNIME workflows alternate flows between a pair of CASE Switch nodes. It works perfectly well for me unless there’s a need for processing a larger portion of data. The bottleneck is the CASE Switch Data (End) node which often takes a considerable amount of time.
Let’s have a look at a fragment of my workflow:
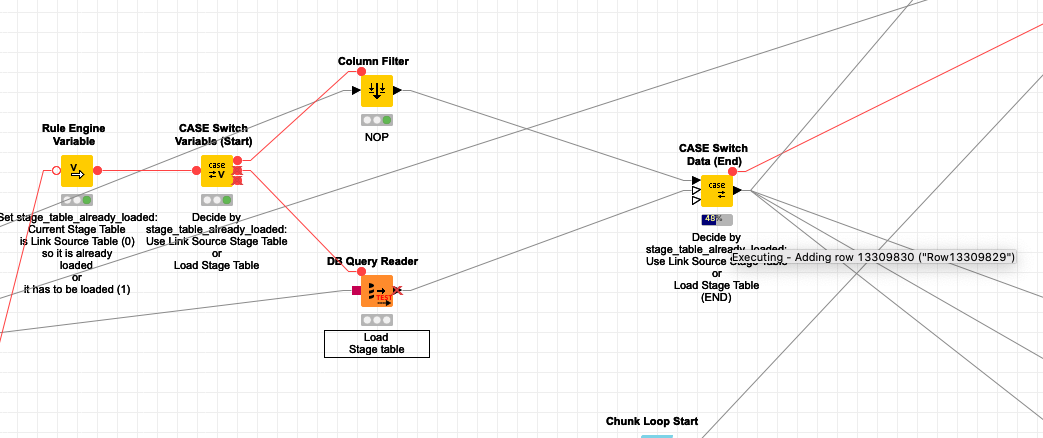
In this particular case, the table the fragment has been processing was ~27M rows, 21 columns of types as follows:
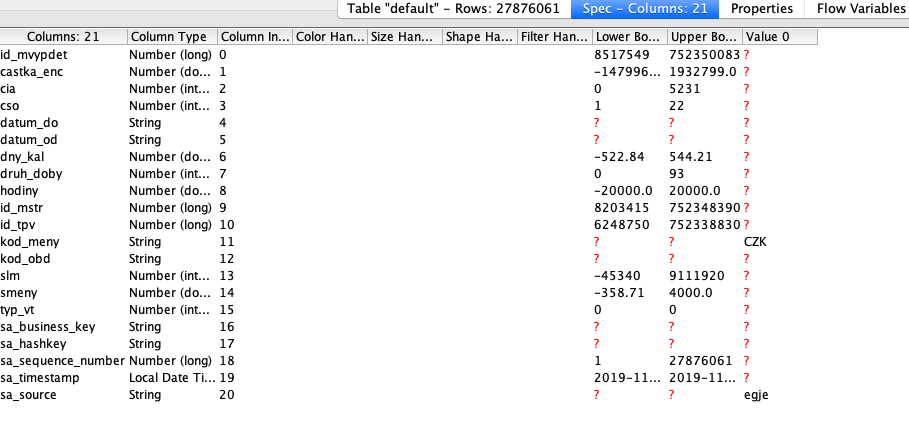
The CASE Switch Data (End) node has been invoking for 14 minutes on my mac with 16GB RAM and SSD disc. On windows running machines I would end up with more time wasted I guess.
2019-11-26 14:18:05,069 INFO CASE Switch Data (End) 0:645 CASE Switch Data (End) 0:645 End execute (14 mins, 12 secs)I know, optionally the node has to concatenate all tables from its input but in this case, there’s just one active branch entering the node.
So, my question is, is there another less time-consuming way of joining (exclusively disjunctive) alternative branches of data connections into a single one?
Just to explain the logic of the workflow I pasted above. There are two options in it. Either the data has been already loaded before or it has to be loaded in the DB Query Reader we can see in the picture. I believe my node names are descriptive enough. BTW thanks for the option of visual formatting, I got used to using it a lot despite the fact it is not noticeable in this particular example. But all in all, thank you.
Regards,
Jan
