Hi there,
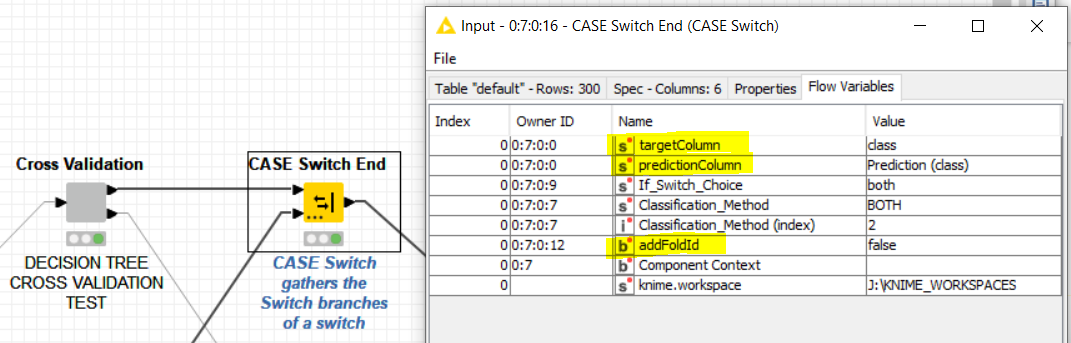
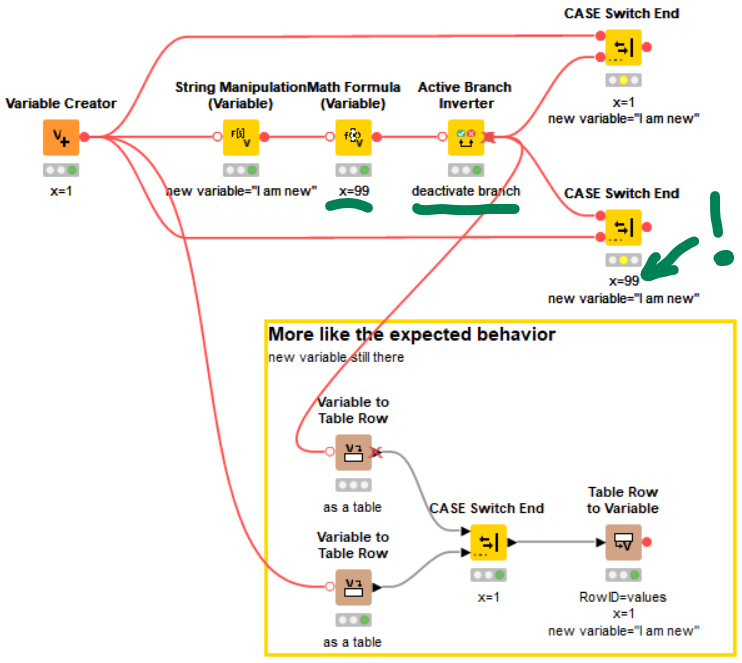
I think we all agree that the nodes (both, CASE Switch End and CASE Switch Variable (END)) work as intended and as the description suggests: flow variables are merged from the top, regardless of the in-/activeness of the branch. This means, that all flow variable end up at the output. The confusing part is, that if you modify a flow variable in one branch, i.e. two of the branches hold the same flow variables, but with different values, always the top value will be taken - again, regardless of the in-/activeness of the branch.
Albeit being as expected, this is counterintuitive and not at all what one would expect. Unfortunately, this is a design flaw in how flow variables work and changing this behavior would mean to break backward compatibility quite dramatically. It’s still great that you raise this issue, so that we can estimate its priority.
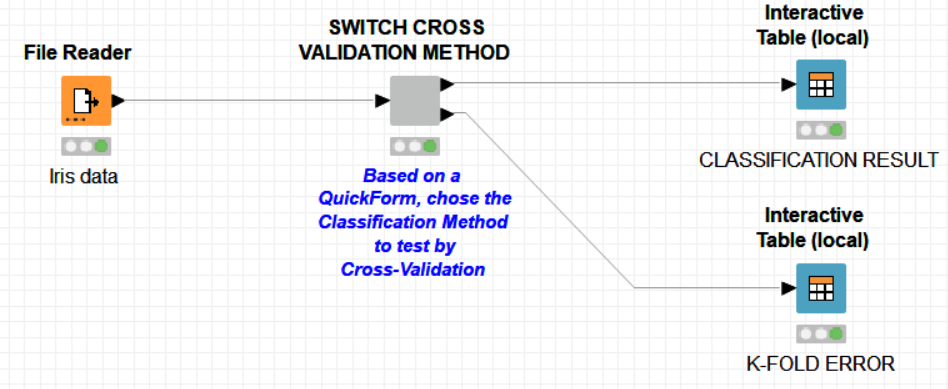
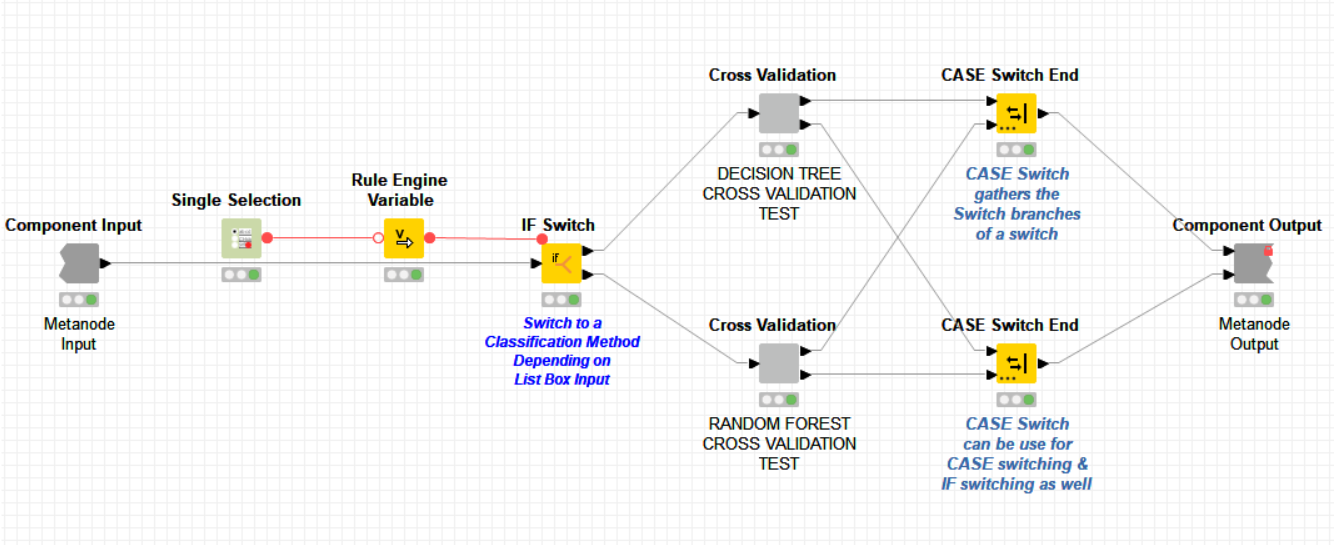
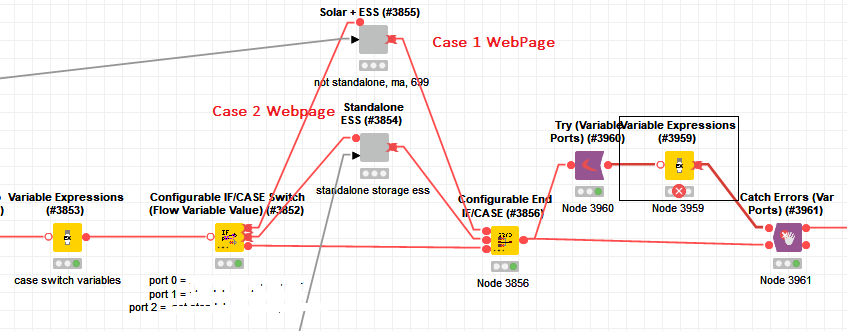
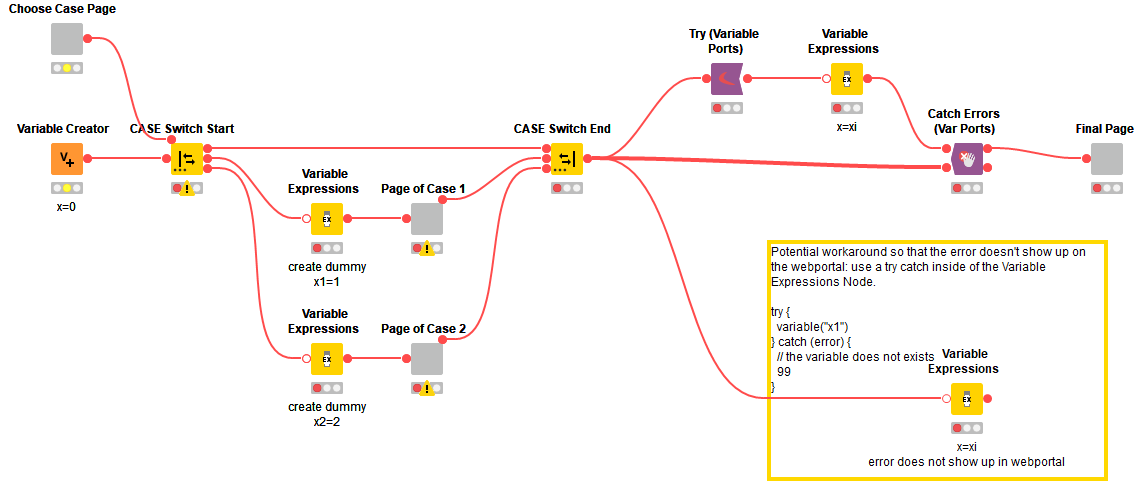
So, coming back to @irene_x’s original question “Is there any way to fix this?” - kind of. You can use Variable to Table Row, a regular CASE Switch End node and Table Row to Variable node. This gives the intuitively expected result (that is, taking the flow variable value of the active branch). However, it adds quite some nodes to the workflow and again all flow variables will show up at the output node, since there is no Flow Variable Filter (yet).
The Math Formula (Variable) Node sets x to 99 and is later deactivated to illustrate the case. (If you want to play with it: Flow Variable Confusions – KNIME Community Hub)
“Are there any alternative Nodes?” - unfortunately not, since this is from a technical perspective not easily possible right now due to how flow variables are designed.
I’d thus recommend creating new Flow Variables instead of “re-using” old ones. Since components are scopes for flow variables (flow variables from the outside of components can be blocked, and propagation to the outside can be blocked), I can recommend these to control the amount of flow variables.
I hope that sheds some light!
Lukas