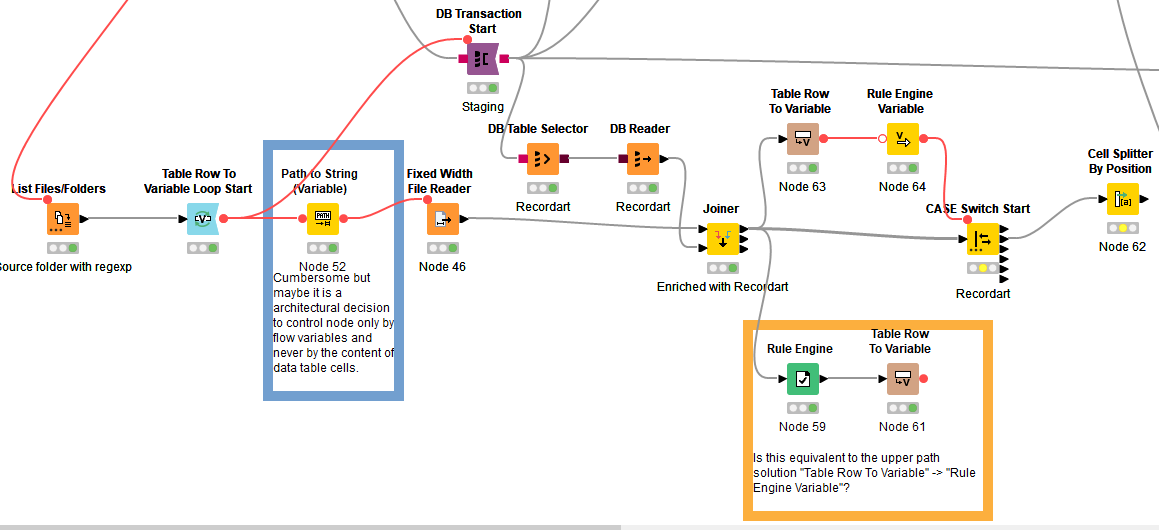
Set up
I have a bunch of fixed length files to load. One file can hold different types of records. Which line is of which record is determined by the first to characters of a line. My line type definitions are held in a database table.
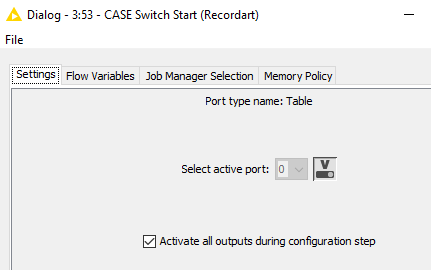
I activated the activation of all port during configuration.
So far, so good.
Problem (to me at least now)
The further split of the records is different depending on the record type. So I wanted to test the main record type (which is second in the list/switch). However, I cannot as with “unrun” switch the splitter node has no data. And if I run the switch all but the first outport get deactivated and the splitter node gets no data either.
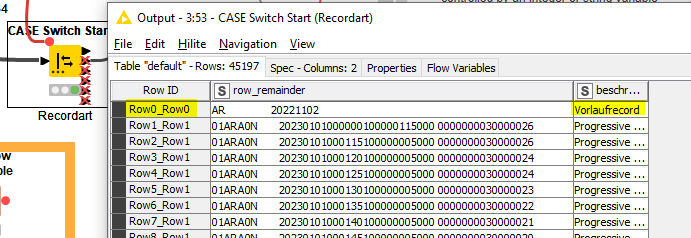
To me, it looks as if the switch would only consider the output of the first record.
I was not expecting the records of “Progressiver Tarif” to appear in the first outport at all. How can I fix that? I initially tried to feed only the data table after the join into the switch expecting to define the conditions with the values of the data table (see also comment in the blue annotation.
I’d appreciate some light shed on my problem. Kind regards
Hi Thiemo,
I think you need to use a cascade of Row Splitter nodes, because the Table Row to Variable node only converts the first row to variables and then depending on that the switch switches for the whole table. But you want to do have one branch for each value in “beschreibung”. Alternatively, you can use a Group Loop Start to start a loop where each iteration handles the records with one specific value of “beschreibung”. If that handling is very similar for all, it might be the better option because your workflow has less branches.
Kind regards
Alexander
Thanks for the nudge. I see I choose the wrong node, even though I do not see the purpose of the switch node yet. And sort of pity, the splitter cannot add more out ports.
Hi Thiemo,
Yes, would be cool if the splitter had dynamic output ports. That is why I suggested the Group Loop as an alternative.
The Switch node can be used to enable one or the other branch based on a condition. It is very useful for Data Apps when you need to decide whether to show one or the other view to the user (e.g. some call was successful → Show data table and bar chart, otherwise show error message). But also in normal workflows, it can be useful, e.g. when you check whether some DB connection is available. If it is, you load data from it, otherwise you fall back to some CSV file.
Kind regards,
Alexander