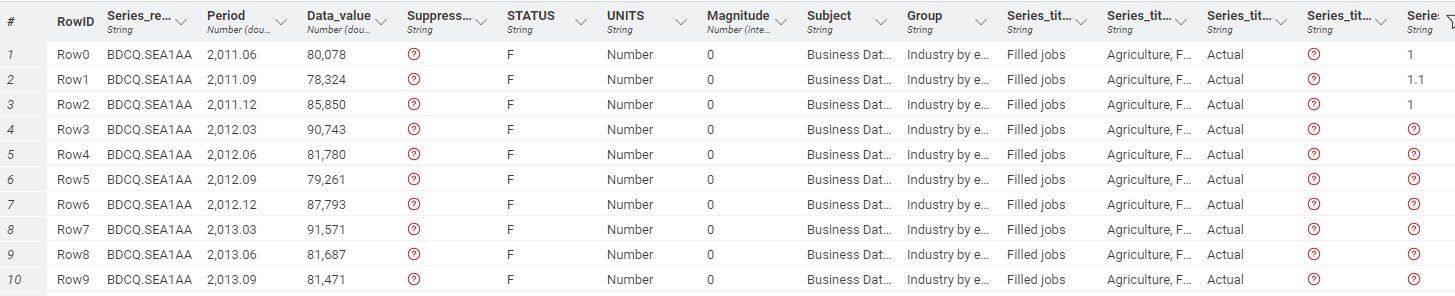
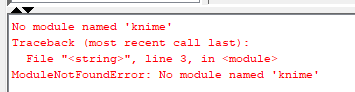
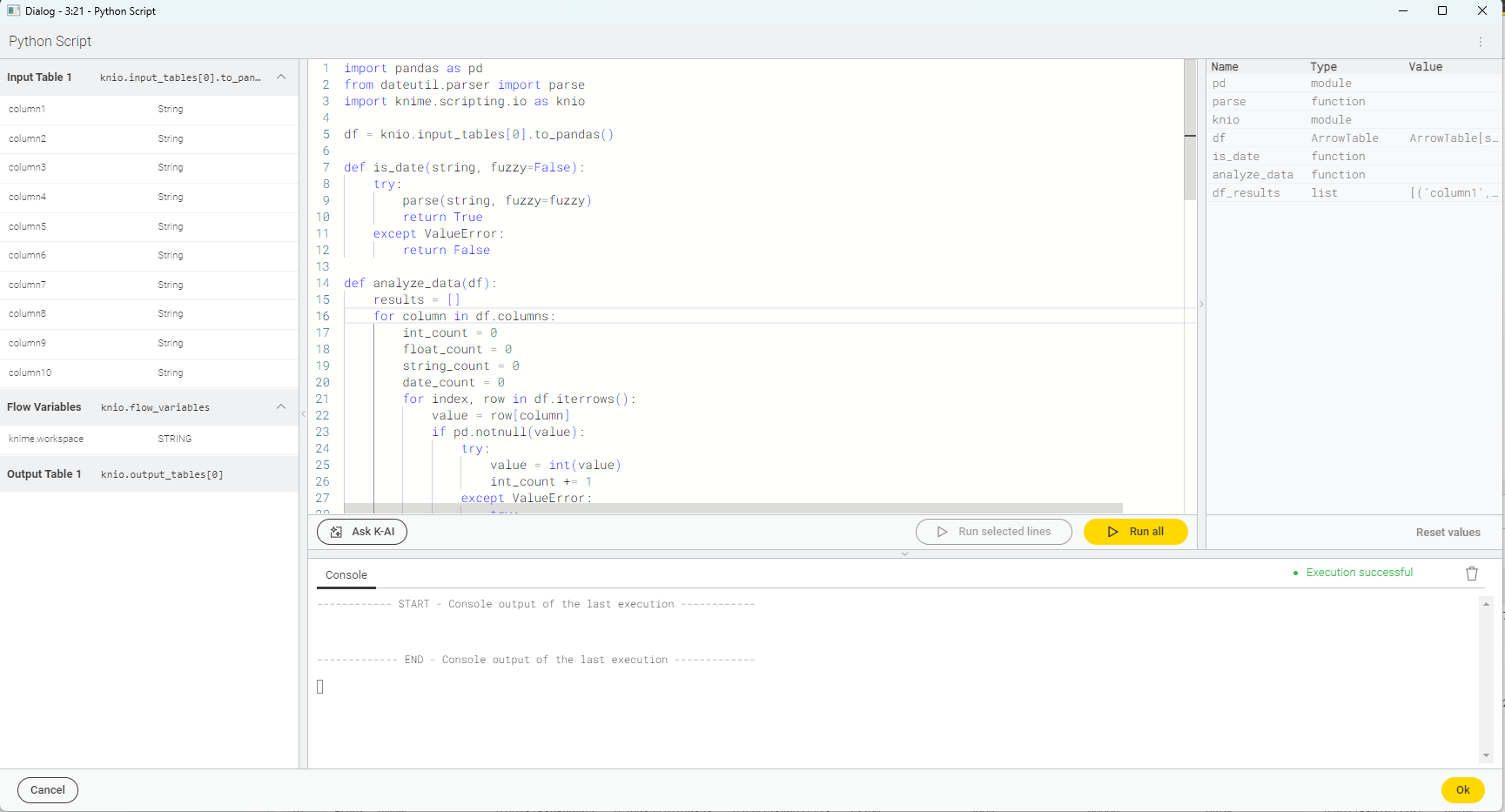
Hello, I used csv reader in the first node, then I came to the second node, I used python script to change the data type of my columns, the code I typed is the same, but it does not change in the output of the table, according to the example, the data type of the last column should be changed. But it doesn’t work, what should I do?
Copy input to output
output_table_1 = input_table_1.copy()
import pandas as pd
def analyze_data(df):
results =
for column in df.columns:
int_count = 0
float_count = 0
string_count = 0
for index, row in df.iterrows():
value = row[column]
if pd.notnull(value):
try:
value = int(value)
int_count += 1
except ValueError:
try:
value = float(value)
float_count += 1
except ValueError:
string_count += 1
total = int_count + float_count + string_count
if total != 0:
int_percentage = int_count/total100
float_percentage = float_count/total100
string_percentage = string_count/total*100
max_percentage = max(int_percentage, float_percentage, string_percentage)
if max_percentage == int_percentage and max_percentage == float_percentage and max_percentage == string_percentage:
results.append((column, “string”, int_percentage, float_percentage, string_percentage))
elif max_percentage == int_percentage and max_percentage == float_percentage:
results.append((column, “float”, int_percentage, float_percentage, string_percentage))
elif max_percentage == string_percentage and max_percentage == float_percentage:
results.append((column, “string”, int_percentage, float_percentage, string_percentage))
elif max_percentage == int_percentage and max_percentage == string_percentage:
results.append((column, “string”, int_percentage, float_percentage, string_percentage))
elif max_percentage == int_percentage:
results.append((column, “int”, int_percentage, float_percentage, string_percentage))
elif max_percentage == float_percentage:
results.append((column, “float”, int_percentage, float_percentage, string_percentage))
else:
results.append((column, “string”, int_percentage, float_percentage, string_percentage))
else:
results.append((column, “No data”, 0, 0, 0))
return results
results = analyze_data(input_table_1.copy())