I have a file called Sample_data.csv.1 which I want to convert to Sample_data1.csv
I am pulling these files from an API and I was wondering how can remove .#number extension and append it to the file name. As the data dump gets larger the value of .#number gets bigger, so manually thing is simply not feasible.
The file cannot be read when the file extension is csv.1 and we simply cannot remove the .1 as we will have duplicate file names.
I want Knime to change the filename and extension in the desired directory.
Welcome to KNIME forum.
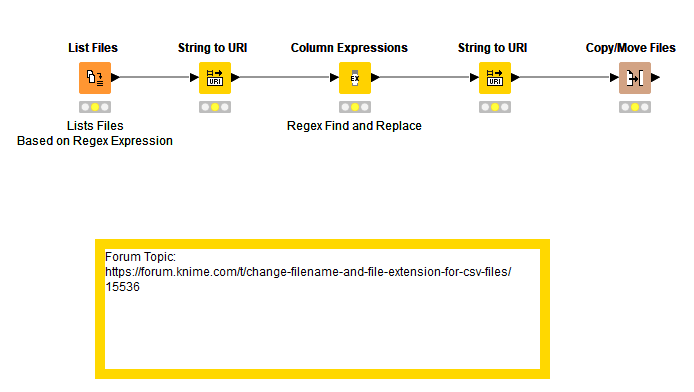
If you use File Reader node, it will read the file with any extension. The way it numbered now could be simply used in the loop.
For testing purposes I created 3 files based on your ’ Sample_data.csv.1’ filename. I placed 3 of them on my desktop and ran the workflow. It renamed all 3 on my desktop to the name format you are wanting.
If I use regex it gives me, “WARN List Files 0:258 Node created an empty data table.”
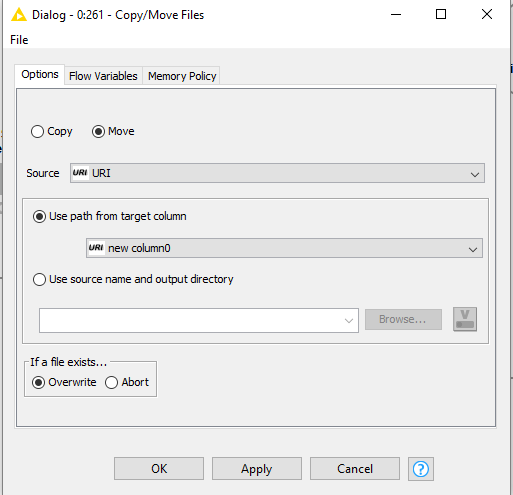
If I use none it gives me, “ERROR Copy/Move Files 0:261 Execute failed: Could not rename C:\cygwin64\home\Data\data-hourly-01012015-01312015.csv.11 to C:\cygwin64\home\Data\data-hourly-01012015-01312015.csv.11”
Hi, to get this to work we have to change the Regex to mirror the filename format. I based my Regex off of your example which was string data and smaller. I will update and send to you.
Oh thanks, now the regex works but the second error message still shows. How exactlly are we handling the file duplication if all csv**.#** is converted into csv.
I modified the regex to this ([A-Za-z].)-([A-Za-z].)-([0-9].)-([0-9].).([a-z]{3}).([0-9].*) as my file name is to be exact: “gen-hourly-07012018-07312018.csv.13” and I can have multiple “gen-hourly-07012018-07312018”