I am trying to Manipulate Strings in several columns, however, I am only interested in making changes to the first occurrence of that string in each column, everything else below, in the same column, should be left ‘untouched’. What is the best way to go about it? I didn’t want to speculate grouping, then concatenating, then counting, then ungrouping again, after asking. Maybe someone knows of a Module that will simply have a ‘occurrence’ checkbox in it making all the thought and work behind it unnecessary. Thanks in advance.
J.
In your case, just replace twice in the regex the sentence “default\ substring” by the string you would like to replace only once, in this case the desired string is the word “replaced”.
Note that here the "\ " in the dummy sentence “default\ substring” denotes a blank character.
So… why was this info not given since the beginning? That’s a question I keep asking several people just to understand that train of thought when you wrote your question to understand why people leave important information when writing their questions.
On top of the sample you provided, can you also have 2 strings to be replaced in the same row? For example, can you have this:
An apple is not a banana => An strawberry is not a lemon
after which of course, apple and banana would not be replaced. But could you have more than 1 string to be replaced (in my example being “apple” and “banana”)
@bruno29a no, the string will only show up once per row.
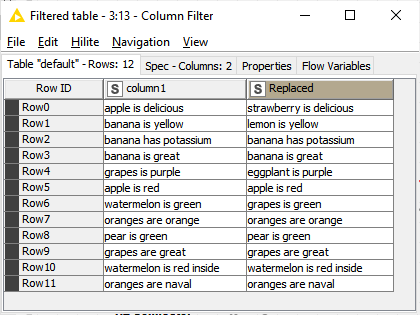
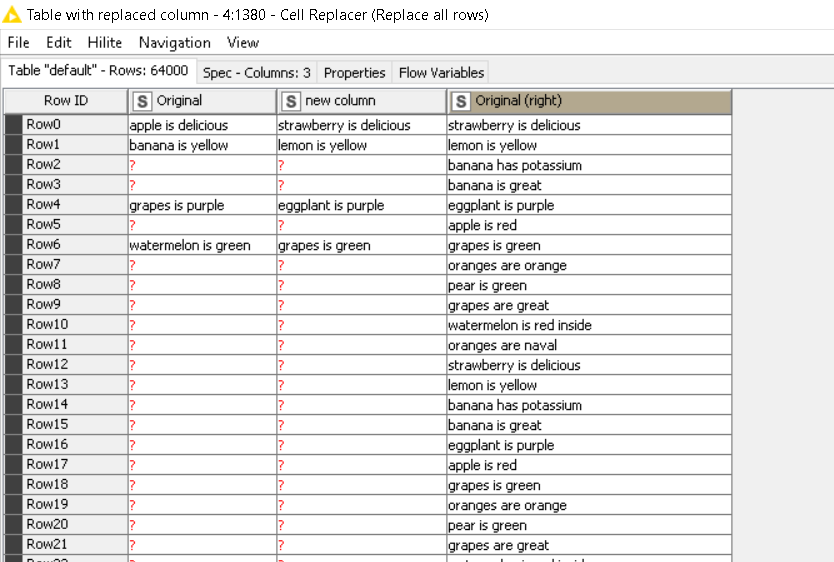
Replace only the 1st occurrence
Replaced
1st occurrence of Apple
a1
1st occurrence of banana
a2
1st occurrence of grapes
a5
1st occurrence of watermelon
a7
This is an example of what was to be replaced according to my example. In this case, the first occurrence would a1 for apple, and a7 for watermelon for example.
@bruno29a I am simply stating that the first occurrence of Apple is at cell a1. I could/should have omitted that information. Just tried to give more information. You’re correct as well, apple replace with strawberry etc…
Details:
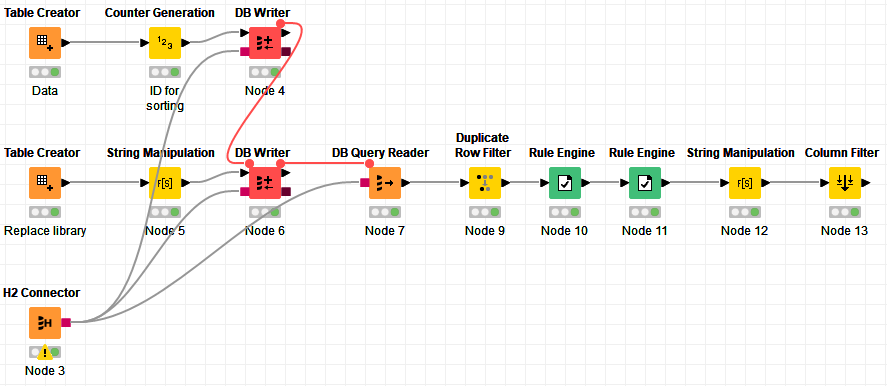
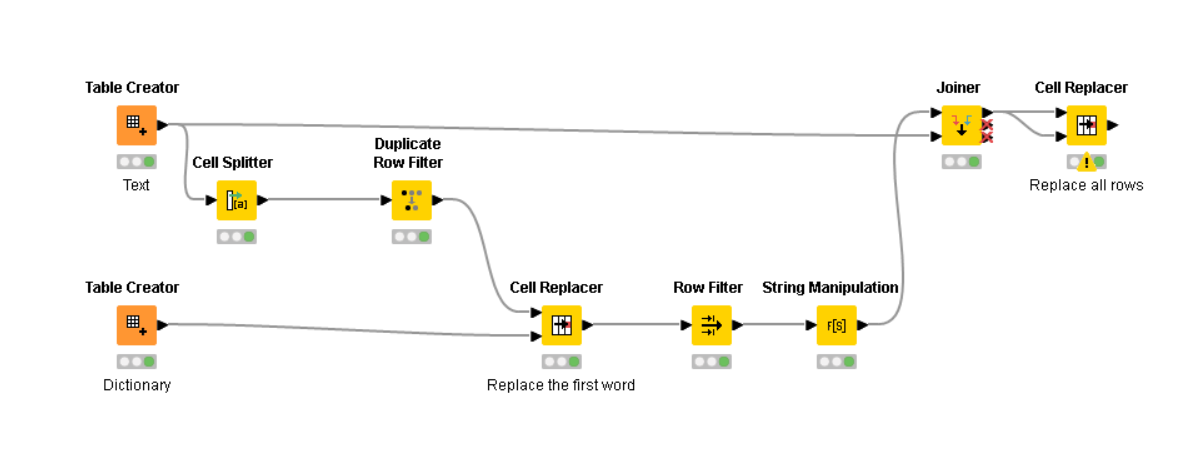
To check for each string to be replaced within all the rows, you have to either do a Cross Joiner and then compare, or use the ability from a DB engine to do a join using LIKE. I chose the latter in order to avoid a Cross Join as the amount of rows after a cross join can be huge, depending on the amount of rows you might have originally.
In this case, I use H2 and I load the data in memory. Node 3, 4, 5, 6 and 7 do this. Node 3 contains the connection, Node 4 writes the given data to a DB table, Node 5 prepares the search string to be used as a wildcard, Node 6 writes the search and replace library to a DB table, and the Node 7 does the join.
If you would do a cross joiner, you would replace these 5 nodes.
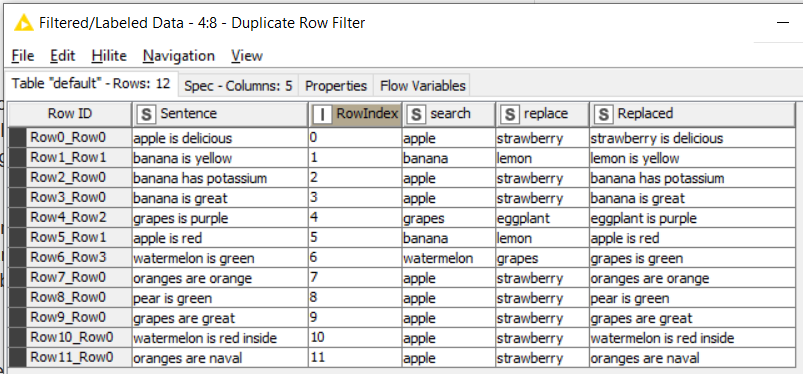
I then flag what to replace and what not to replace using the Duplicate Row Filter. I don’t remove any duplicates here, but rather use the other option to keep the duplicates, but mark which one is chosen (apply replace) and which ones are duplicate (do not apply replace)
Another approach is to use a group loop. First create groups based on the first word in the sentence.
Loop every group. Take the first row and replace the first word using the Rule Engine. Concatenate the group together and aggregate the separate words to a sentence again. Change only first occurence of specific string.knwf (45.3 KB)
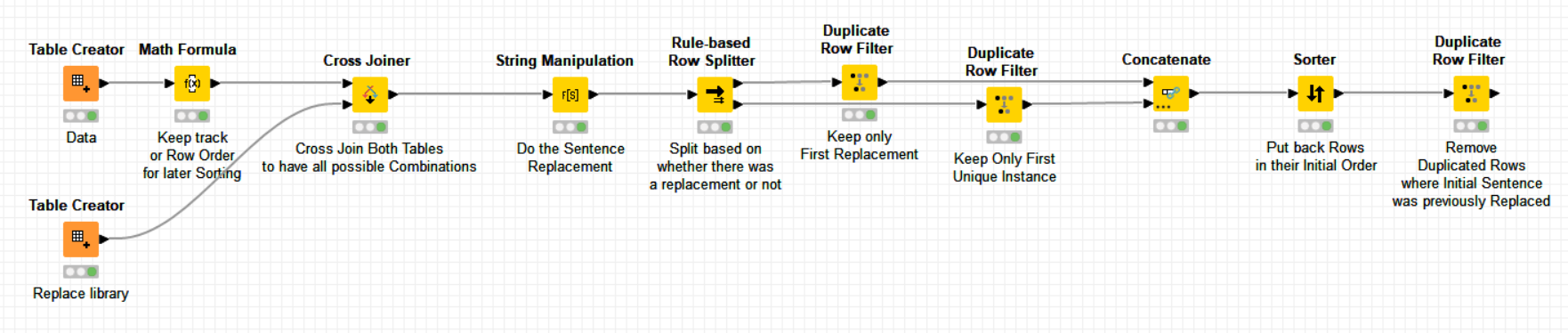
Based on this information and complementary to @bruno29a and @HansS workflows, please find below an alternative solution that is based on the -Cross Joiner- node of KNIME:
Hi @HansS , though the sample data had the string to be replaced as the first word, there was no indication in the explanation that they would always be the first word.
If that were the case, it would definitely make things easier, and the approach can be simplified.
Loops in general should be avoided when they can be avoided, and in this case, it is quite inefficient, since you would want to do the replace only the first time, meaning you would still go through all iterations after the first one. In addition, it still needs to do an if (represented here by your Row Splitter) in each iteration to validate if it’s the first iteration or not to apply the replacement.
Hi @jarviscampbell , next time, please consider to reveal all info so that others who are helping you won’t have to go back & forth to dig up the details.
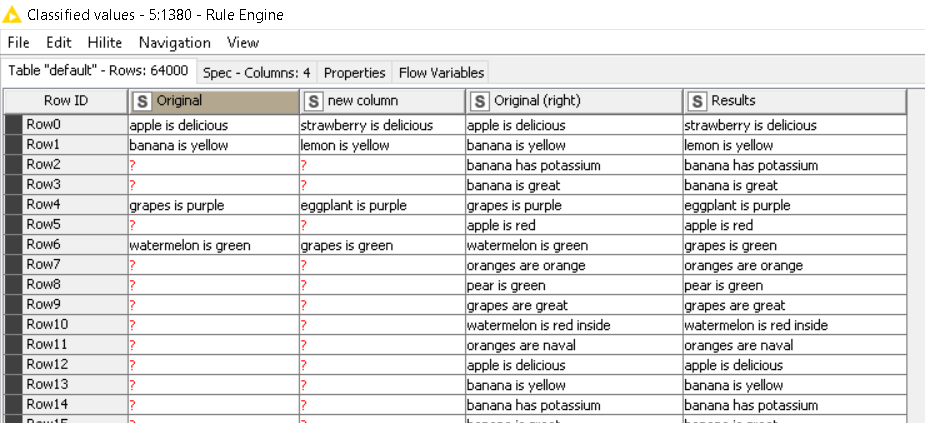
Anyways, here’s my attempt on it. I tried it on a 64,000 row table, and it took about 6 seconds. Each of the above suggestions have their own bottleneck node, and my bottleneck is the last node in the workflow.
Hi @badger101 thank you for your help. I will try to provide all the information at once in the future. I am sorry about that. In my defense in a couple hours past from the original post I had provided extra info. But will def do it in the future.
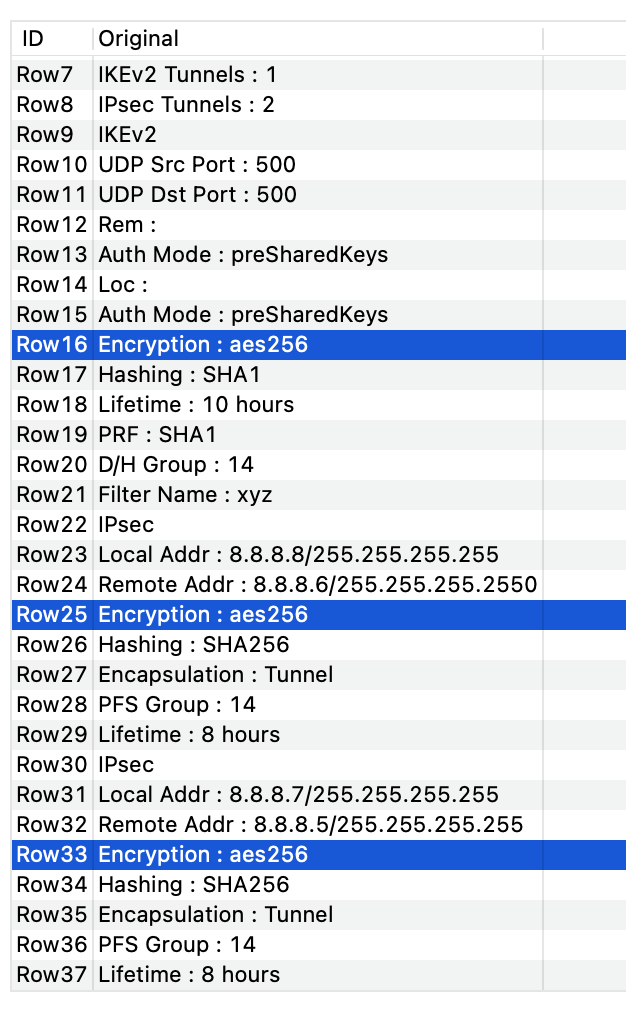
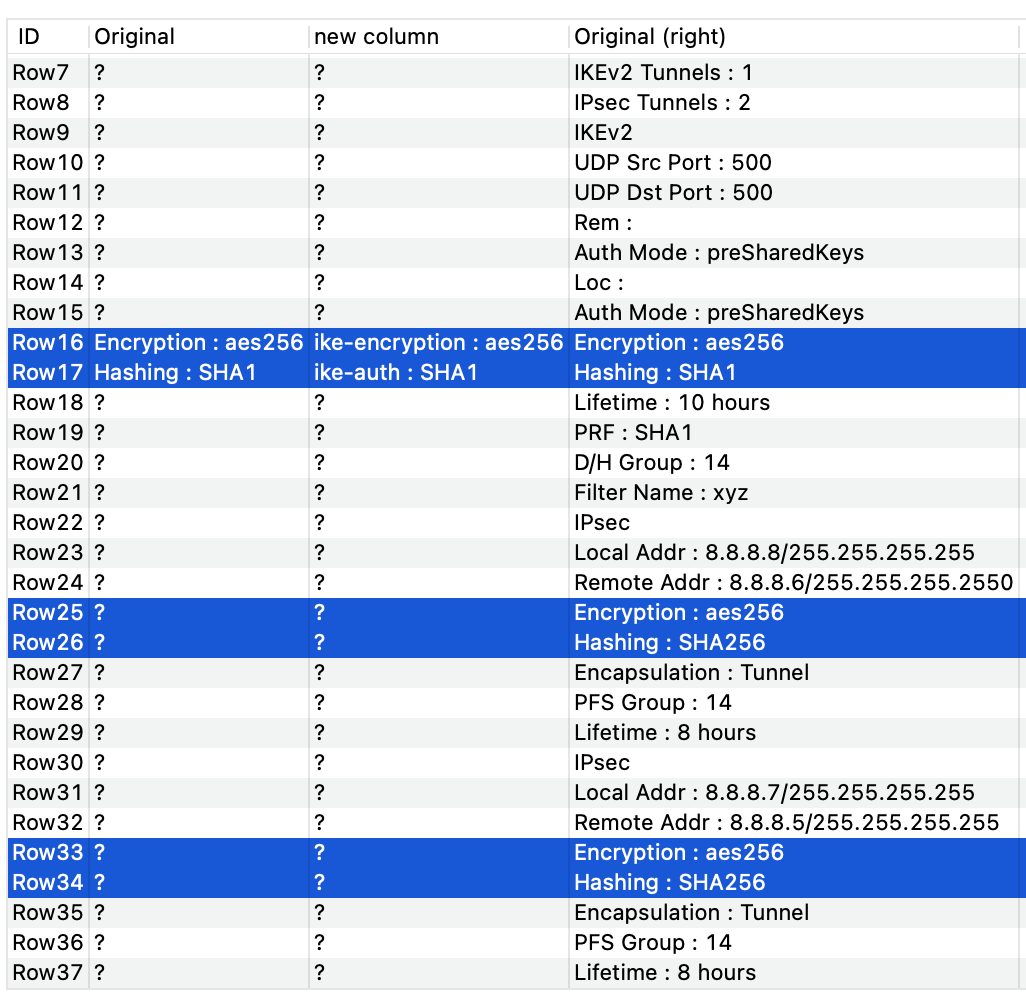
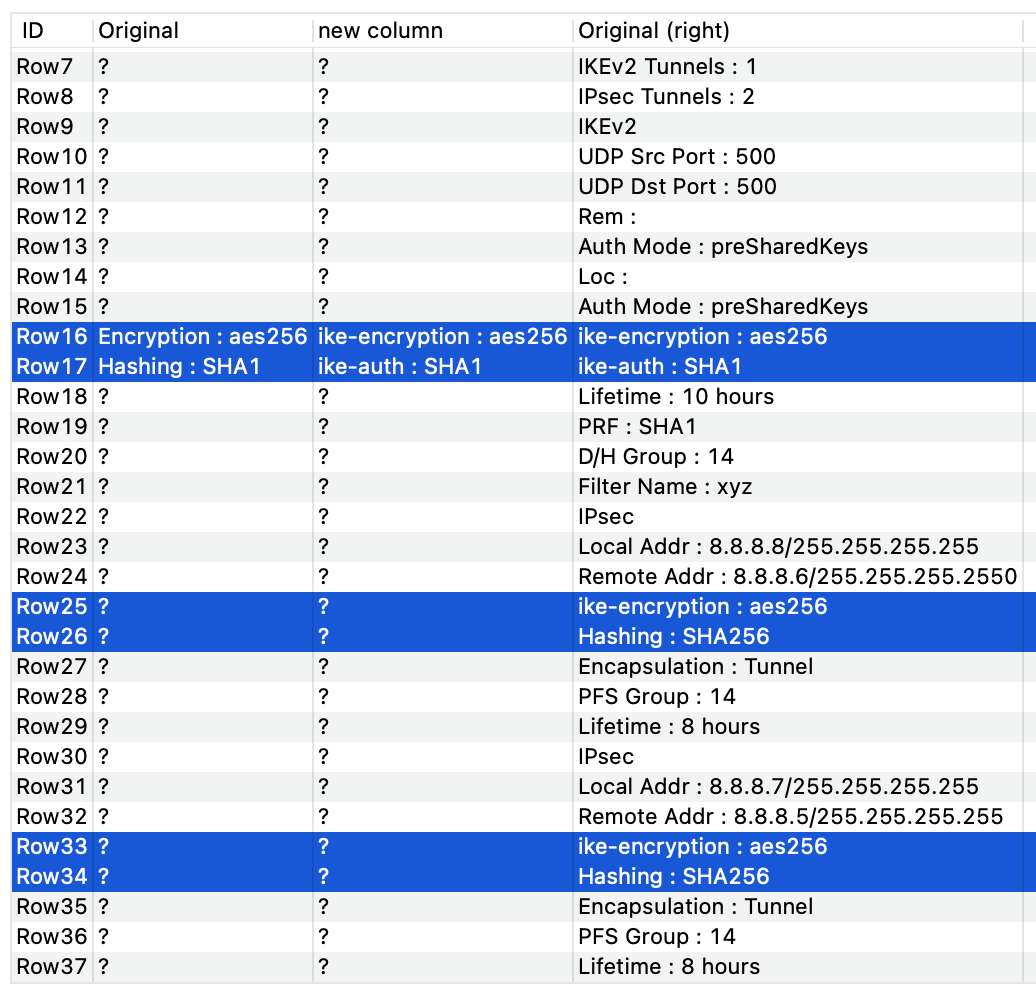
I found that your formula was the easiest to use out of the previous one, however, I have used two words to start, for the replacement to happen. Encryption to ike-encryption and Hashing to ike-auth.
As you can see. Somehow, hashing worked fine. However, encryption does not. It keeps repeating the replacement. Could you please tell me the reason behind it?
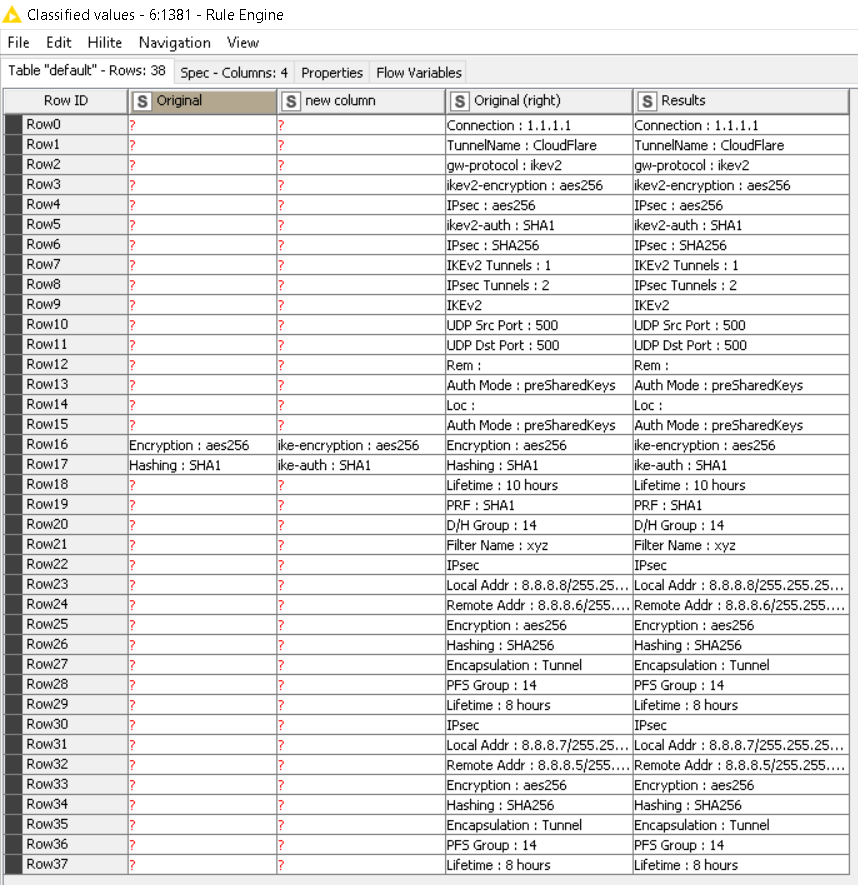
The three examples shown is the progression of the data on its original form, then on the Joiner node and then on the Cell Replacer. As you can see, On the Cell Replacer, I see Encryption being repeated more than once.
Thank you @bruno29a. I will try to understand cross joiner a bit better and use your proposed workflow if that is the case. I am currently working on using @badger101 's workflow. I appreciate you.
@jarviscampbell I have looked at the workflow, and yes I can see the issue. I’m trying to think of why it occured, because it shouldn’t, and it didn’t occur in my dummy data. Will get back to you.
Hi @jarviscampbell , I am NOT using cross joiner. I said that it was another option, but I was not in favour of it cause of the amount of records it could generate.
I simply pointed out what nodes you would need to replace if you wanted to use cross joiner.
I’m actually using the ability from DB to join using LIKE, which Knime cannot do (hence why you would use a cross joiner in that case).
EDIT: Also, is it confirmed that the string that you want to search is always the first word (this was not mentioned in your explanation, so I assumed that it could be anywhere in the row and built the workflow according to this assumption. It would have been much simpler if it was confirmed that the string to search was always at the beginning of the row)