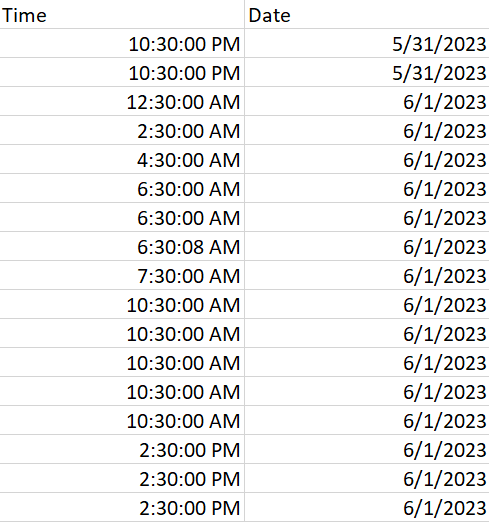
Hi @caratsweet, no there is no facility to add additional outputs on the Rule Based Row Splitter. It is a simple binary TRUE/FALSE where TRUE (by default) goes to the Top output, and FALSE goes to the lower output.
A scripting node such as Java Snippet or Column Expressions (which if you are new to KNIME, you may need to install) could do the whole logic in a single node, but does require use of script/programming constructs.
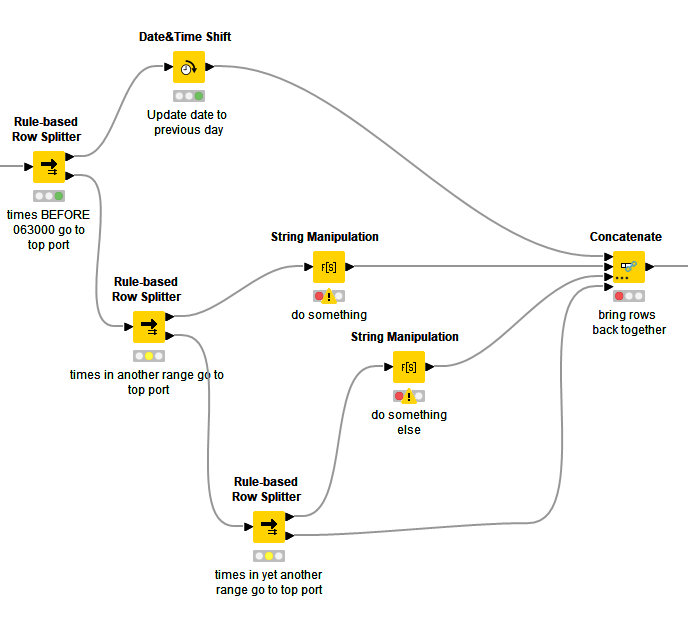
Within the low/no codes, if you did not wish to “chain” Rule Based Row Splitters, you could have a series of Rule Based Row Filters with each given one of the rules, and they would then do the same as the upper-port outputs in the above “waterfall” picture I put in my previous post, with each then having a branch terminated again by the concatenate node:
There are other more complex ways, and whether they are worth the greater time invested to write/test depends very much on your use case.
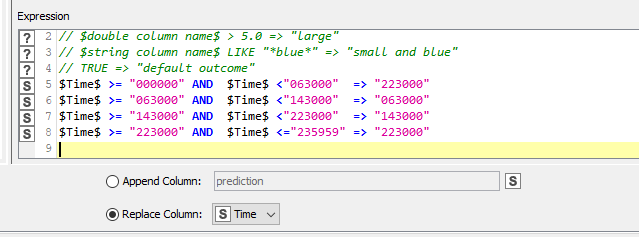
For example, to put all of the rules into a single Rule Engine and have it choose a branch, ideally we’d be able to then just use a “CASE Switch Start node” to have it choose the branch based on a column value in the data. Sadly it isn’t quite that straightforward as the CASE Switch Start node acts only on a variable value and treats all rows the same way based on that value.
To get round this limitation, it can be placed inside a loop, and then the variable can be changed on each iteration, so dealing with different rows in different ways.
You could, for example use a Table Row To Variable Loop Start node, and have all rows handled one-at-a-time by the case switch node. The trouble with using loop like that is that performance takes a dive as the data set grows, which isn’t that noticeable on a small dataset but more than a handful of iterations and you will see how slow it becomes, as 1000 rows will take 1000 times as long as 1 row. So that approach really doesn’t scale.
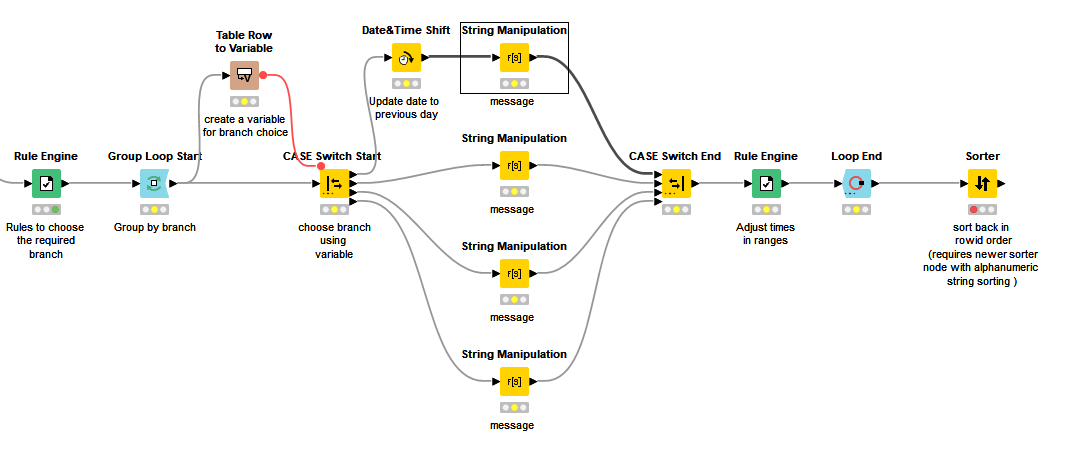
To optimise this pattern, we can use a Group Loop Start instead. It still has a performance penalty but instead of acting on the rows one-at-a-time, it would act on the rows one group (branch) at a time. Theoretically then, the performance drop off becomes a factor of the number of branches rather than the number of rows, which whilst not as fast as a non-loop option remains much better from a scaling point of view.
As an example, see the section of workflow below. Here it does the same as the previous workflow, but also adds a message based on the branch it runs through.
NB this demo is only to show a possible implementation of branch processing. I have left the other functionality from the earlier workflow, (such as Rule Engine to change times) where it was, and of course in a real world scenario this may be done somewhat differently!
Convert and modify dates and times - 3 - group loop and branch demo.knwf (84.4 KB)