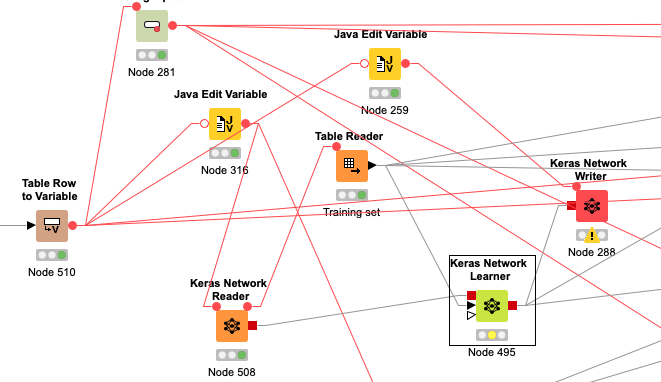
I have a Keras network learner within a loop. The loop cycles through various previously saved Keras networks (saved as .h5 files with different network configurations). Specifically, feeding into the Keras Network learner are values from read-in tables (also changing in within the loop). The number of “bitvector*” columns intentionally vary from the read-in tables. The Keras Network Learner node has wildcard selection (i.e. bitvector*) for the streaming columns - i.e. input inclusion - which precisely match the size of the input layer(s) for the read-in .h5 file. One would expect that the wildcard selection in the Keras Network Learner inclusion would thus accommodate the changing number of input columns. This does not seem to be the case. Any suggestions on a work-around strategy for what appears to be a bug in the Keras Network Learner node?
Note, the loop stops after each iteration, noting this warning in the logfile:
2020-02-13 18:36:11,090 : WARN : KNIME-Worker-71-Column Filter 0:318 : : Node : Keras Network Learner : 0:495 : Input deep learning network changed. Please reconfigure the node.
Manual entry into the Keras network learning node to simple change something seems to reactivate the node for execution. Of course, this defeats the purpose of having a loop if a manual entry is required.
Any ideas on how to get through this issue? I have had no issue with the same loop structure strategy which reads in other .h5 files that all have the same input/hidden/output node configurations - but I really need to explore varying network configurations in this loop.
I believe your problem is not related to the include-exclude settings but rather to the spec of the in- and output layers of your network. The Keras Network Learner will require reconfiguration if the in- and output layers change, i.e. have different names, or different shapes.
The naming part is rather easy to handle, just make sure the in- and output layers of your network have the same names in your different network architectures.
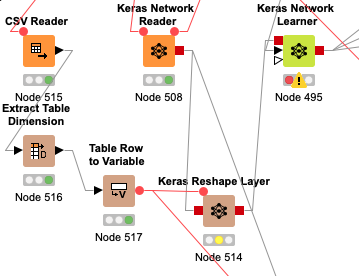
The shape part can proof to be more difficult. You wrote that your inputs vary, this can be handled by using partial shapes followed by a reshape layer to get to your actual input shape for the network.
Note that, in this case, the learner can’t check if the provided input values are compatible with the shape and in case they aren’t it will crash during execution.
If you output shapes vary, you might be out of luck because at least our Keras Reshape Layer does not allow to define a partial shape.
However, it might be possible if you manipulate your networks directly in Python.
Thank you so much for taking the time to read and respond to my problem! I have been so impressed with knime, but have really struggled with this for several days.
The names of the input layer do change, but I handle this with wildcards and as you hypothesize this is not the issue.
So I am assuming per your response that the issue is the changing shape of the input layer. I would have thought the Keras Network Reader (that is connected to the Keras Network Learning node) having read-in a new .h5 network with a changed input layer shape would address this.
I am so optimistic with your response, but not quite clear how to implement your comment - [quote=“nemad, post:2, topic:21033”]
this can be handled by using partial shapes followed by a reshape layer to get to your actual input shape for the network.
[/quote]
As mentioned, in my workflow the Keras Network Reader reads in a previously saved but different configured network. Only different by the number of input nodes. So how do I configure a partial shape and reshape?
Note, I am using this strategy to systematically improve upon trained networks, so it is important that I am able to read in a previously saved .h5 that has had some degree of training. After a cycle of learning, the workflow saves over the previously read-in .h5 network:
My apologies for the spaghetti workflow image. I have been experimenting with the thought that maybe the order of operations was the problem - i.e. trying to make sure the network reader loads in the .h5 file before the network learner has a chance to pull in the data from the table reader. I use flow variables to control file names of data tables and the neural network’s .h5 file.
we are happy to hear you find the AP useful.
Regarding your problem, I think there was some degree of misunderstanding, so let me clarify:
You can only use wildcards for the names of the input columns, the learner does not support wildcards for the names of input layers.
However, if the shapes vary, fixing the names won’t solve your problem and you’ll have to go with the slightly more complicated workaround I briefly outlined in my previous post.
In your case, you’ll have to work with the DL Python Network Editor
node, to change the input layer of your network.
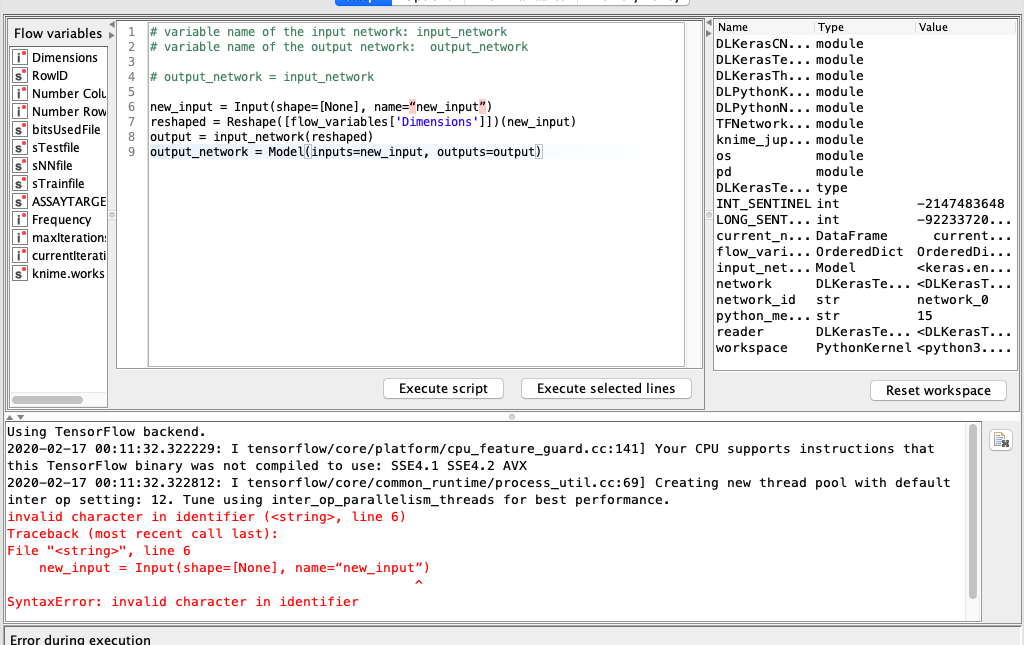
Here is an example how the code might look like for a network that expects an input shape of [3]:
Note that this code should work for any network that has one input layer, you’ll just have to change the shape in the reshape layer to match the shape of the input layer of your network at hand.
After training you can then extract your original network from the trained network with another DL Python Network Editor and the following code snippet:
output_network = input_network.layers[2]
This works because a model can serve as layer in Keras and we can therefore simply retrieve the model from the wrapping network.
I hope this solves your problem.
One last thing: The order of operation does not play a role in your case, as the Keras Network Learner is only configured/executed once all the specs/inputs are available.
Thanks Adrian. I will dig more into it this week. Is it a problem that the color of the tabs for the DL Python Network Editor node is grey, while the Kerase Network Reader’s are red? I experimented with the Keras Reshape Layer without success:
I quickly tried your above code in a Dl Python Network Editor node per below, but get the following error when test/executing the scrip - sorry if I am missing something obvioust:
The different colors are only an aesthetic problem caused by the fact that the DL Python Network Editor can also output any other supported type of deep learning network (as of now TensorFlow and ONNX).
Unfornutaley, you can’t use the Keras Reshape Layer to fix the problem because the input of the network needs to be modified.
Wow, that’s a hell of an uninformative error message… I believe the problem is that you are missing the necessary imports, that I left out for brevity. Here they are:
from keras.layers import Input, Reshape
from keras.models import Model
Thanks for the additional information. Definitely a journey!. Still get another uninformative error even with the imports - unchartered waters for me, so my apologies if I am still missing something obvious:
I am now considering changing hidden nodes within a single layer. I trust the DL Python Network editor will come to the rescue again, but I am not quite sure how the above commands may vary when referencing hidden nodes within a hidden layer. Can you recommend how to achieve this in a similar way as above?
I am not sure if I understand correctly, what do you mean by hidden nodes in a hidden layer?
Above a model was used as hidden layer, so do you want to change layers of such a model?
No, recall in the above model we were changing the number of input nodes in the input layer. This is a 3 layer network: input, hidden, output. Now I need to vary/change the number of hidden nodes in the hidden layer.
Well, we weren’t really changing the number of nodes, just the shape the network reported to the learner.
Actually manipulating the number of nodes is far more difficult to achieve (at least as far as I know).
Here is how I’d do it:
Define the new network architecture
Extract the weights from the old network
Insert the weights into the new network
Note, however, that subsequent layers of a network typically depend on all there predecessors, so if you change any layer, you’ll have to assume that all your subsequent layers are now broken and need retraining.
This leads me to the quesion what your actual use-case for this procedure is?
Now I am confused. I guess I don’t understand the distinction between “shape” and actual numbers of nodes.
The use cases are fairly simple. For the first case as mentioned at the start of the above stream, The goal here is to alter the number of input nodes which corresponds to the actual number of input parameters fed into the neural network. Here, a loop effectively changes which and the actual number of input parameters fed into the neural network. In the second more recent use case, I am attempting to alter the number of hidden nodes to find an optimal neural network architecture - i.e. the best number of hidden nodes for a given set of input/output parameters. This is a fairly standard strategy I have employed for decades using other neural network simulators.
So now you have me concerned. I used the suggested DL Python Network Editor node and above suggested code to change what I thought was the actual number input nodes. The assumption here (of course) is that the fully connected network of inputs to hidden nodes would then change. Since I am training the networks after the network change, I am fine with the network weights changing on the architecture change. In fact that is expected.
Ah ok, I think I misunderstood you earlier.
What you want is to use different network configurations that vary with respect to there hidden layers as well.
I thought you wanted to manipulate an already trained network by changing the hidden layers.
For your use-case you actually don’t have to do any extra work, the Keras Network Learner only uses the input and output layers to decide whether the configuration fits the network or the user has to reconfigure.
What we did earlier in this thread was essentially tricking the Learner to believe that all your networks had the same input shape ([?]) but we did not actually change the number of inputs of your individual networks.
I am especially confused by your last couple responses. In the first use case, I have used your technique in the DL Python Network Editor to what I thought was changing the number of input nodes - not trying to “trick” the learner into anything. I punted on the second use case and simply restructured my looping so that all variations of numbers of hidden node networks were saved in advance and just recalled within the main loop, adjusting the input number of nodes per the DL Python Network Editor. I really wanted to be more elegant with the hidden node varying approach, but your recent comments put me into a state of concern and workaround.
However, I did leave in the suggested DL Python Network editor node prior to learning, and then another post learning per your earlier recommendation which together enabled continuation of the looping mechanism that this original stream was struggling with. As mentioned, the pre- and post- DL Python Network Editor strategy seemed to be working. However, I should say my network evaluation/scorer steps (i.e. Keras Network Executor) are pulling from the Keras Network Learner node directly, not after the post DL Python Network editor step. So I have a sinking feeling I have been led a bit stray.
What still confuses me with your most recent comments is that they suggest the network’s number of input nodes were not changing. This seems incorrect. Below are examples of saved networks which suggest the input (and actually hidden nodes) are changing:
I see that my comments were confusing, so let me try to clarify by starting from the beginning.
The way I understood your problem is that you were evaluating different architectures that especially had varying number of input nodes (but the same number of input layers). This didn’t work because the Keras Network Learner would always prompt you to reconfigure the node whenever the number of nodes in the input layer changed.
This is because the Learner identifies a network by its input and output layers i.e. the shape (number of nodes) and the name of the respective layers. If these don’t match, it will require you to reconfigure the node.
The workaround we developed worked because it ensures that all networks have the same input layer definition (with name “new_input” and shape [?]). Therefore the Learner is “tricked” to believe that the networks are the same and doesn’t require reconfiguration.
If I understand your second request correctly, you now want to also change the hidden structure of the network, and I believe this should be possible out-of-the-box.
The only obstacle you might encounter is if you add more layers and therefore the name of the output layer changes.
However, here you can use a variation of the approach of the workaround for the input layers, you essentially have to ensure that the shape and name of the output layer of all your networks is the same.
Regarding your concern about the DL Python Editor applied after learning:
My idea here was that it allows you to end up with the same network architecture as you passed into the loop. If you, however, want to use the network within the loop e.g. with the Keras Network Executor, the same restrictions as for the Learner apply (in fact the underlying code is largely the same), therefore the Executor also needs to be tricked in order to deal with inputs and outputs of varying shapes and names.
Thanks for the clarifications, I think I am o.k. now. I am not changing the number of hidden layers, Indeed, multiple hidden layers are frequently not necessary and often over-determine your system (i.e. total adjustable parameters far exceeding learning examples). I have found over the years that good, clean numerical input/output representations can be the key to success.
It seems the saved networks (after training) within my loop have the “shape change” from your suggested DL Python Network Editor script and when used later with a network executor, their outputs are as expected. So all good!
The concept of “shape” was perplexing. I am used to thinking in terms of numbers of input, hidden, and output nodes (and thus network weights). From my perspective, the end-game is all about optimized network weights and leveraging them in a predictive capacity.
That is correct, although that’s what Deep Learning seems to be all about
I am sorry for the confusion around the term “shape”.
I believe the use of the term mainly emerged from CNNs and RNNs where inputs are not simple vectors but multi-dimensional tensors, which have a certain shape i.e. size in each dimension.