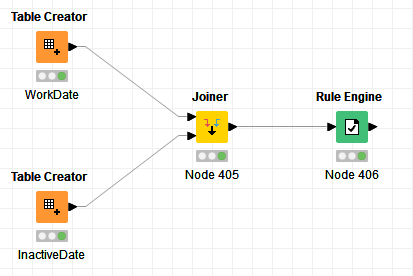
Well. I’ve a workflow. In this workflow i check the active times of users. its always end of month check.
In my wf i’ll try to take the table row to variable loop. But its the false way, because i’ll get iterations of tables. I need just one table.Date_between.knwf (14.6 KB)
Well, I know what you mean. The Problem is, that you have a really big table “workdate” and a also big table in inactive date. More than 18 duplicate NameIDs for each NameID. If you have e.g. 80k rows in workdate you must have 80k rows in the end of the WF to check the correctness.
This rulengine check 0/1 is like one filter. The Big WF have more then 4-5 rounds with filter. Everytime to use a join gets really massive more rows.
Thats why i want to use a intelligent loop.
I’m not a hero in group/ recursive loops. Maybe this is a way to get to the right output table.
Welll. Its also a good way. But i need a workflow where is at the start and the end the same number of rows. More than one time a table would be checked and sets the Number of ActiveTable to 0. In the End i can filter out the 0’s not before.
thats why i used the loop. but in my case the loop makes various table with iterations. I need just one table.
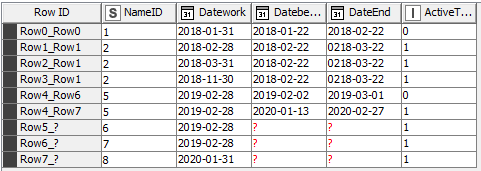
Table one row check table two if a row has the same id. Then check if the table one date is in the table two date range and mark that as 0.
your task is a bit specific and seems best approach is the one @ScottF laid out in first reply. Only thing missing is Duplicate Row Filter or GroupBy node which will give you same number of rows as starting, WorkDate, table. Configure it in a way that NameID and Datework columns are your grouping columns in both nodes with rule to keep row where ActiveTime column is minimum in Duplicate Row Filter or minimum as aggregation method on same column in GroupBy node. I prefer GroupBy as you will get rid of joined columns from InactiveDate table but maybe pick the one that is faster considering you table size. To sped things up more use new joiner node - Joiner (Labs).
Well. That’s not what I want, but it works. Basically, it often happens that you want to compare 2 lists / arrays with operators. Every time the solution seems to be the joiner node. I would like to see in the forum if someone tries a Python snipped or a loop. Are you sure that the joiner node is always the fastest option?
The thing is that the joiner node changes the number of rows. Then operations are carried out in the same line with the Mathruler. At Least you can get the sourcetable with groupby. But if you have an output table and want to run through the individual line with an array (other table), then that should only work with a loop and an IF statement. Or. IF or Case. In this case the joiner node is really faster. I would have loved to test it live to see whether Joiner is really faster than the loop version.