I’m reading in a lot of XML files. I extract the information in the XML nodes with the XPath Node in KNIME. This works fine if all XML files have the same number of XML nodes inside the XML file.
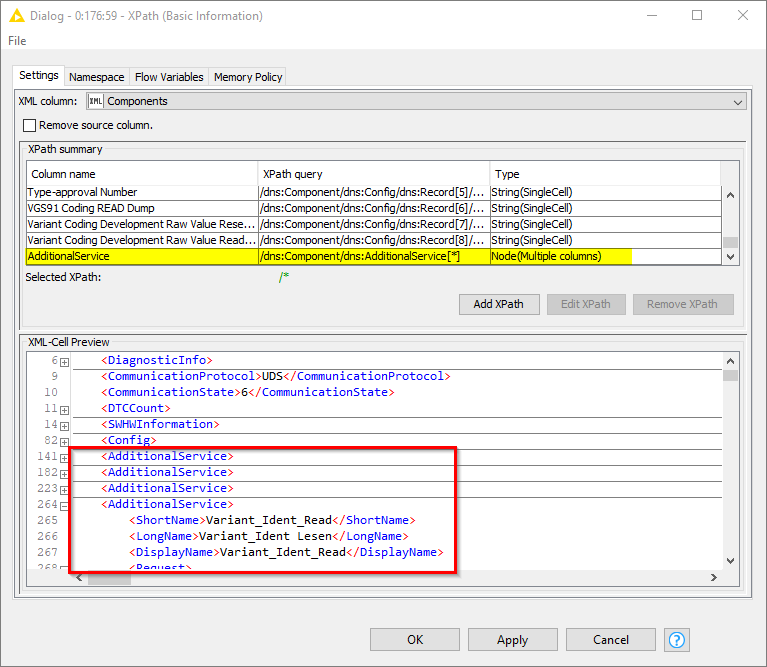
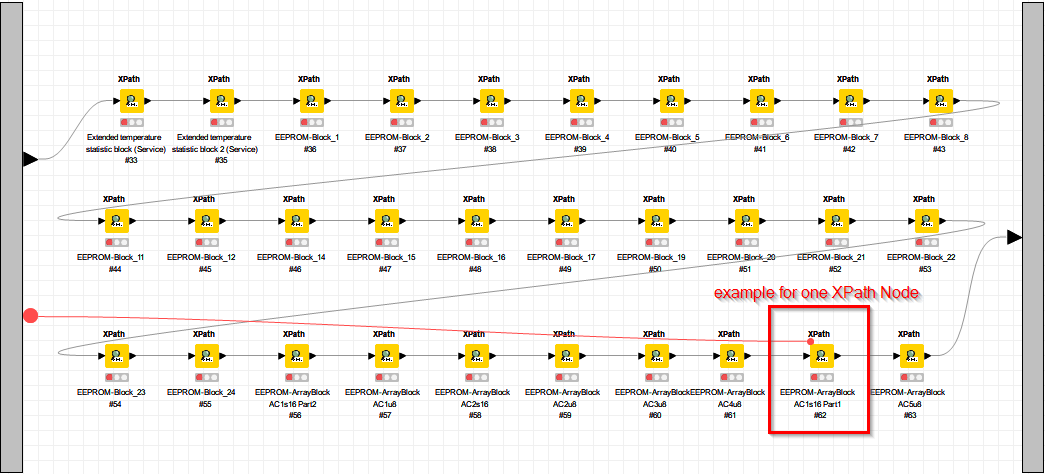
Problem is that in some XML files XML nodes are missing. The result of these missing nodes can be missing values in my output table. That’s no problem for the workflow. The problem occures if the number of “AdditionalService” nodes varies (shown in the red frame in the screenshot)
By now I’m knowing 73 “AdditionalService” Nodes. I don’t know if in the future new “AdditionalService” Nodes will be added nor if the order of these “AdditionalService” Nodes is always the same.
My idea was to check after each XML file if my XML nodes that are of interest exist. But how? I try the Simple File Reader Node as well as the XML to JSON Node and the JSON to Table Node. Do I need a refernce table which has all the entries I want to extract?
Has anyone of you an idea how to fix this porblem in an elegant way?
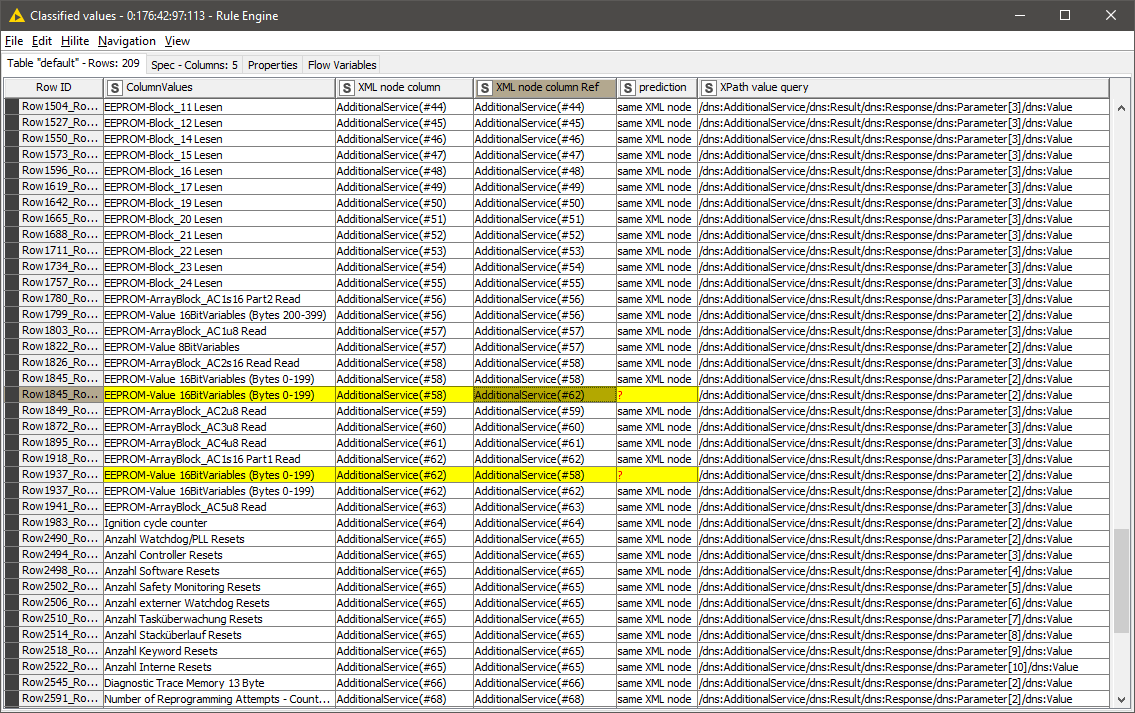
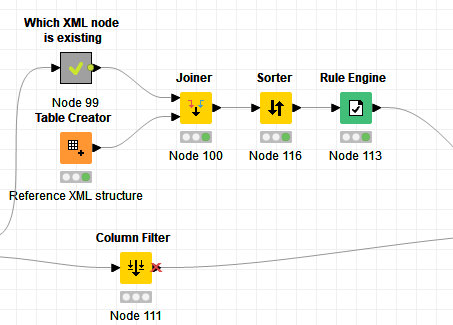
OK, after 100 nodes later I have a reference table with all XML nodes I’m interested in. With a Joiner Node I compare the content of the actual XML file with the reference table. This look like this:
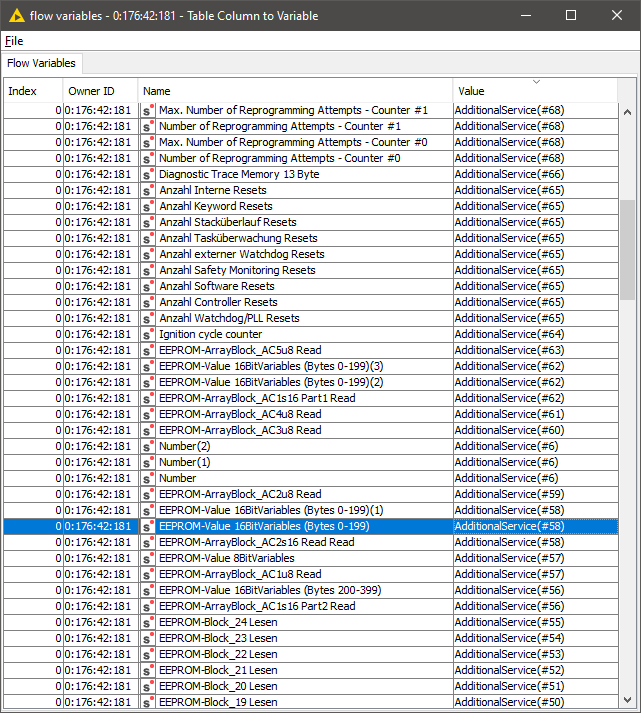
Now my idea is to tell my XPath Nodes via Flow Variables which XML column to select. In the shown case my specific Xpath node has to read in XML column “AdditionalServce(#58)” insted of “AdditionalServce(#62)” Does this the Tabel Column to Variable Node? If so the Flow Variable output table looks like this
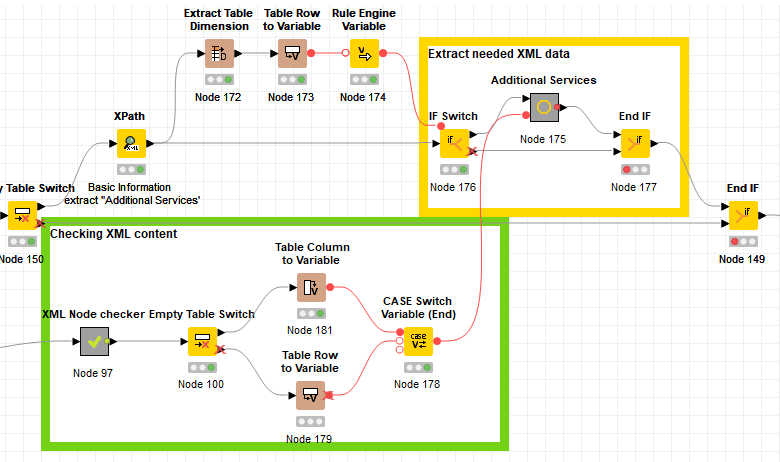
Going deep in the meta nodes the flow variable connection comes to the corresponding XPath node. Which switch do I need at this point? And I have the dull feeling that then I need this switch 60 times (for each XPAth node), right?
Here is the Meta Node with the example XPath node to change the input column by flow variable
I still have some problems regarding to the Joiner Node. With this Joiner Node i will join the XML structure of the current XML file with a reference XML structure. With the Right Inner Join option I nearly get my desired output table but nearly only.
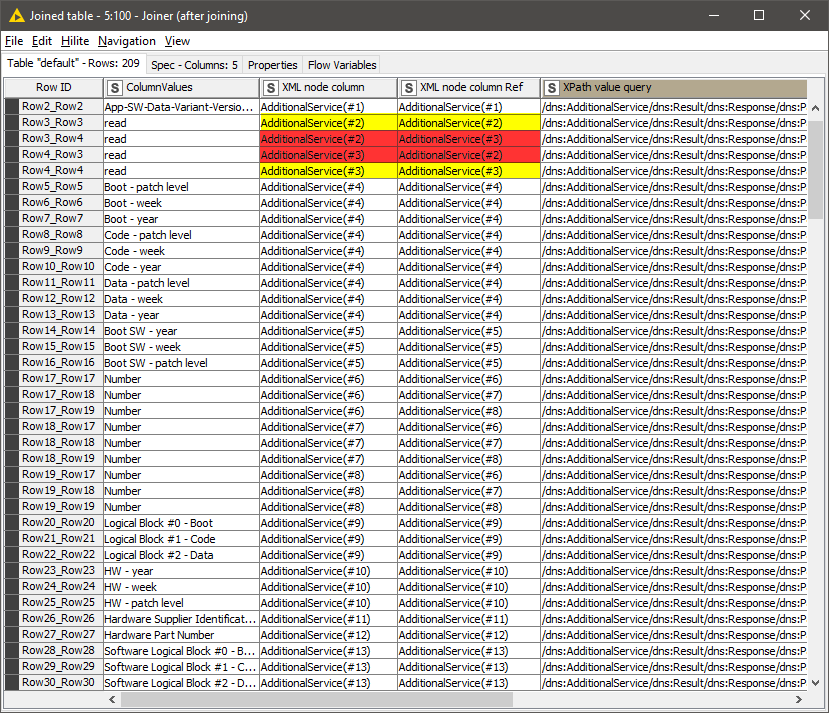
I get some duplicated rows after the Joiner Node which I can’t filter out with the Duplicate Row Filter. Why you can see in the following screenshot:
You can see that for example Row ID “Row3_Row4” and “Row4_Row3” are interchanged.
My questions is: Can the Joiner Node Configuration be improve in that way that no interchanged rows are in the output table? I always need an output table with 199 rows, like the reference table.
For better understanding I attach an example workflow with a current XML structure and the reference XML structure.
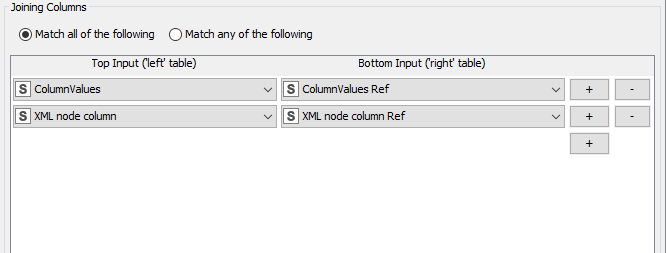
Hi @Brotfahrer , you are joining on Column Values = Column Values Ref, and both of those have a duplication of the value such as “read” in your example, so you will inevitably get the product (cross-join) of those which leads to your duplication. What result are you actually after? If you only wish for “read” to match in one place, you either have to remove the duplicate entry from your reference table, or you need to also add “Xml Node column” to your join to make the join exact.
with this join I want to extract the information how many XML nodes “AdditionalServices” are in the current XML file the workflows reads. In the 2nd post you can see a screenshot with a lot of XPath Nodes. Depending on the existing XML nodes, I must control the XPath nodes so that the data that can be read out is read out by the correct XPath node.
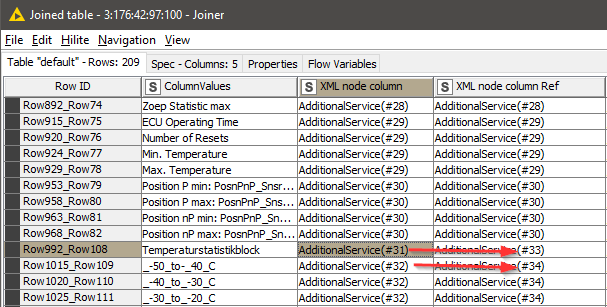
In my example you can also see in Row ID “Row992_Row108” the following content.
The important information is to “route” the current AdditionalServce(#31) to XPAth Node extracting “normaly” AdditionalServce(#33) and current AdditionalServce(#32) to XPAth Node extracting “normaly” AdditionalServce(#34). The Rule Engine Node creates the column for the IF Switches.
This is my actual idea to scrabble through my XML data “lettuce”.
I’m open for any ideas decreasing complexity in my workflow
Ah ok, my apologies. I think my over simplification was a misunderstanding about what you are trying to do.
I am trying to work out what result you would be looking for if you were doing this join by hand (instead of with knime), and what your decision making would be.
Maybe if we can take a step back and use a simplified example with a smaller number of items it will help me understand.
If your first table (currently containing 165 rows) only contained the following rows:
You wouldn’t want the duplicated nodes, but if you were doing this manually, how would you choose which of these rows would be valid, and which wouldn’t?
Would the rule be that if, for a given matched ColumnValue, the XML node column and XML node column Ref matched, then choose that one, otherwise arbitrarily choose the first row that matches for a given Column Value and XML node column combination?
So in the above picture, the first 3 rows are acceptable, as are Row3_Row3_Row3 (because they match AdditionalService(#2) ) and Row3_Row4_Row4 (becasue they match AdditionalService(#3) )?
Sorry it is taking me some time to understand your exact requirement.
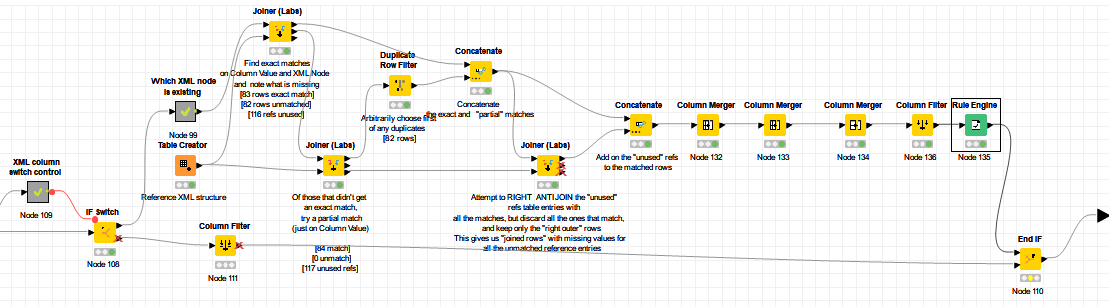
If my understanding is correct, then maybe this workflow achieves what you want.
If we call your tables A (the 165 rows) and B the reference table, then my logic is as follows:
Attempt to find all in A that match with B on BOTH Column Value and XML node. These are your EXACT matches. Put those to one side.
Of those from A that did not have an exact match, attempt to match those with just Column Value. These are your PARTIAL matches. Some duplication may occur with partial matches, so check for any PARTIAL matches that have a duplicate Column Value and XML Node and arbitrarily choose the first one. These are your UNIQUE PARTIAL matches,
Concatenate your EXACT matches with the UNIQUE PARTIAL matches.
“Anti-Join” the EXACT and UNIQUE PARTIAL matches" to table B to find ONLY the rows in table B that did not match to any Column Value. This is then your set of UNUSED REFS.
The total rows from EXACT MATCHES + UNIQUE PARTIAL MATCHES + UNUSED REFS should be required 199, so concatenate the UNUSED REFS onto the end of EXACT and UNIQUE PARTIAL.
I made use of the Joiner (Labs) node as you can see in the attached workflow, as this provides the ability to ANTI JOIN, and filter the matches and mismatches separately. Joiner4Forum-multipass-join.knwf (95.8 KB)
I’m open for any ideas decreasing complexity in my workflow
OK, let’s go bak to work.
I took a while to understand what the Joiner (Labs) Node does. But the result is exactly what I needed!
The part of my workflow now looks like this:
The output table of the Rule Engine Node now has all the information I need.
I have the correlation between the actual “AdditionalService” node number and the node number it should be, see above screenshot - is #31 should be #34. And if a “Column value” is missing I have port switch information for every XPath node. I hope this is the solution for my problem. I will give an update.





 Hope it does work for you.
Hope it does work for you.