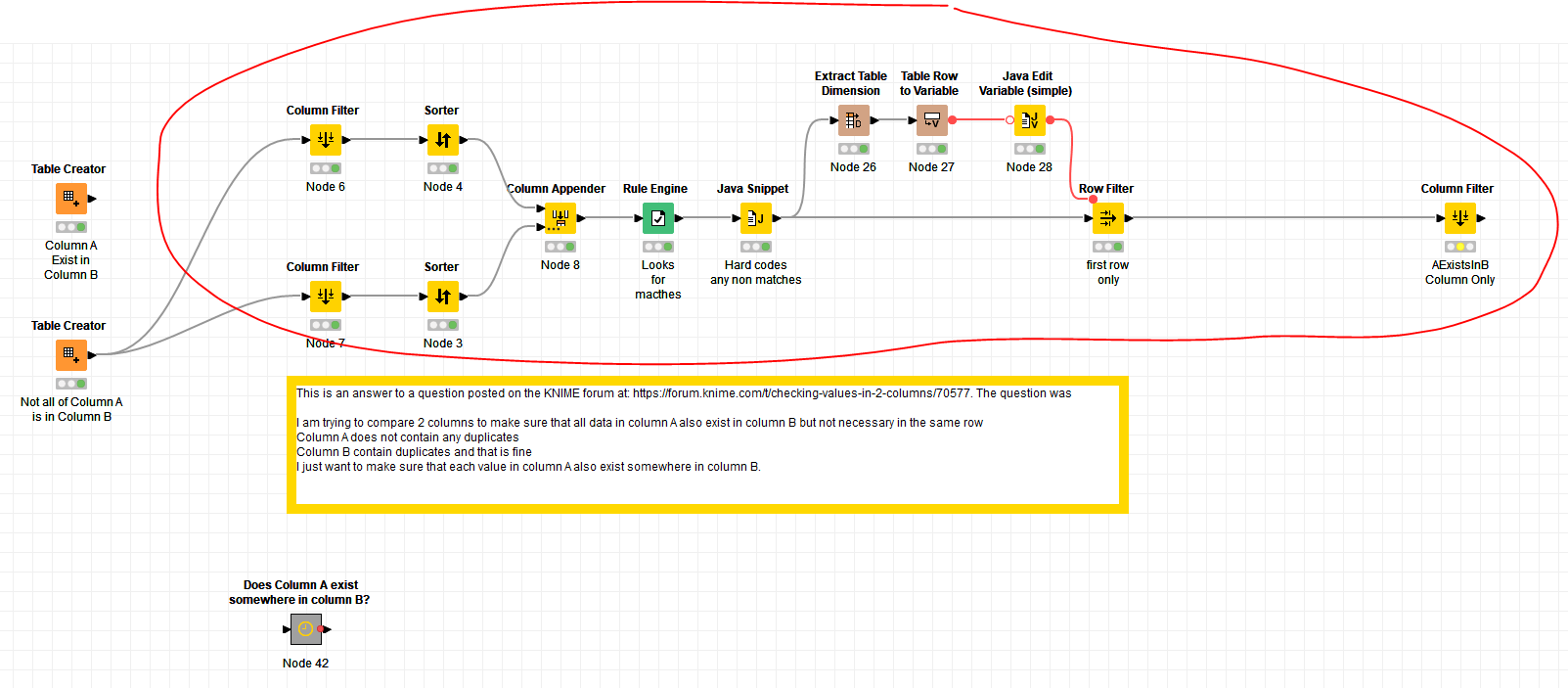
I am trying to compare 2 columns to make sure that all data in column A also exist in column B but not necessary in the same row
Column A does not contain any duplicates
Column B contain duplicates and that is fine
I just want to make sure that each value in column A also exist somewhere in column B.
I am taking your question literally. “Does each value in Column A exist in Column B?” the only possible answers are True or False. Also, I am using the rule Column A does not contain duplicates.
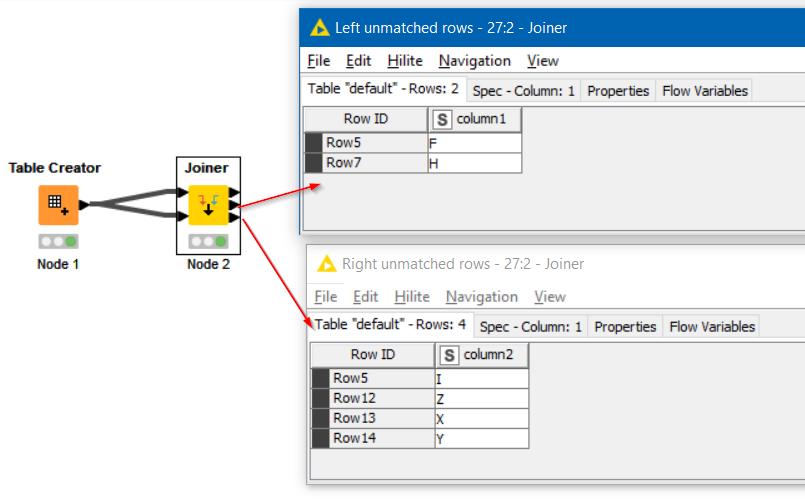
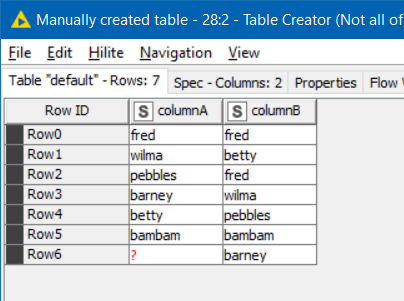
I am impressed at your flow which effectively emulates a sort-merge join. One thing though, is that there is a very small flaw in the logic, in that if it were presented with data such as this:
which still satisfies the “A doesn’t contain duplicates but B can” specification, this would say that there are items present in one but not in the other.
This is because of the missing value in A which by definition must be allowed since A must have missing values if it contains no duplicates, but B does, and also because if B contains duplicates then a sort without removing duplicates would always see rows being “offset” when they are appended and tested at your Rule Engine.
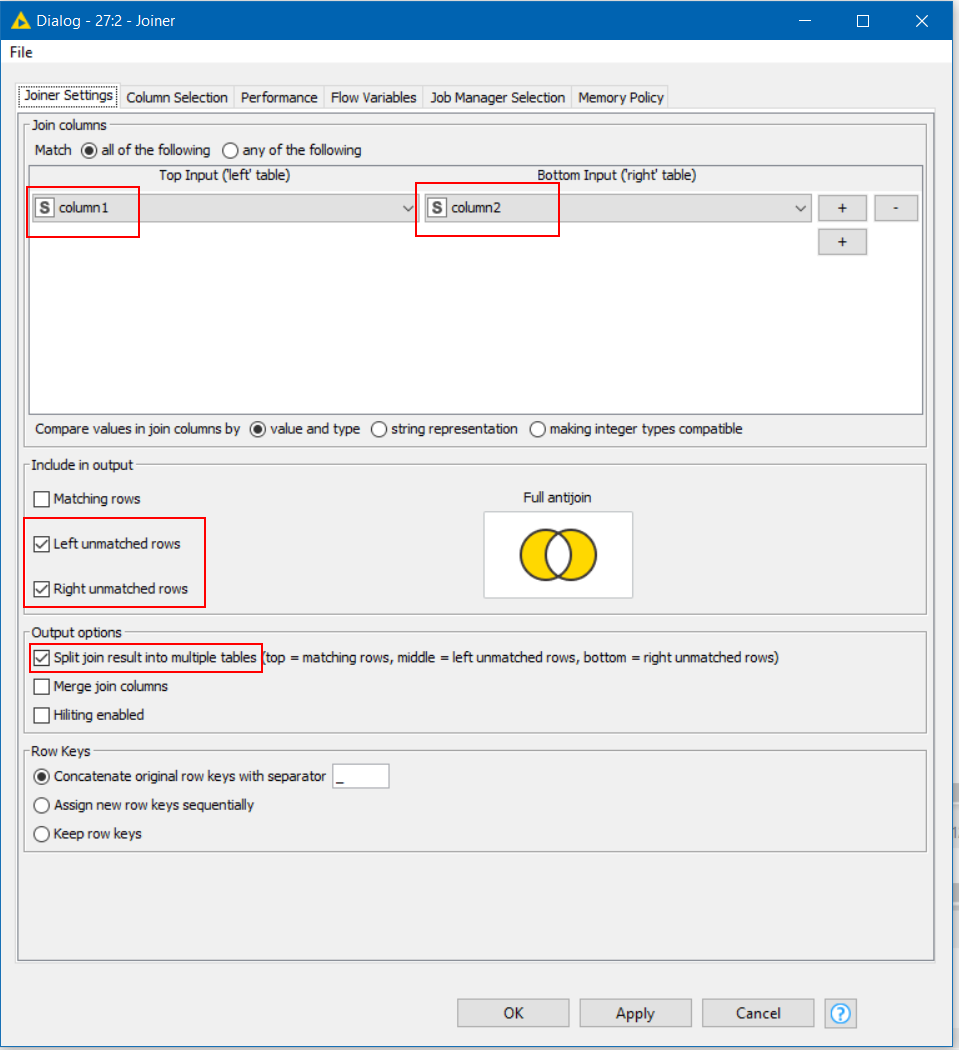
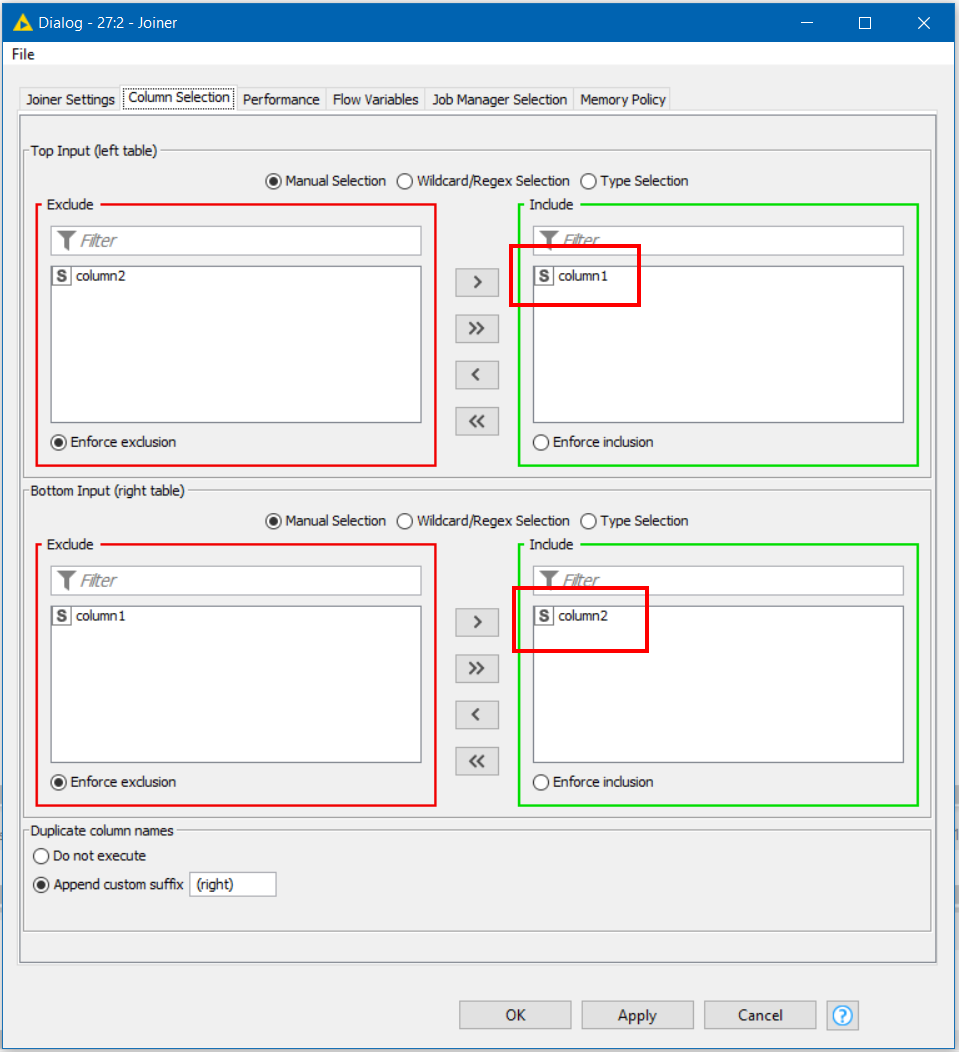
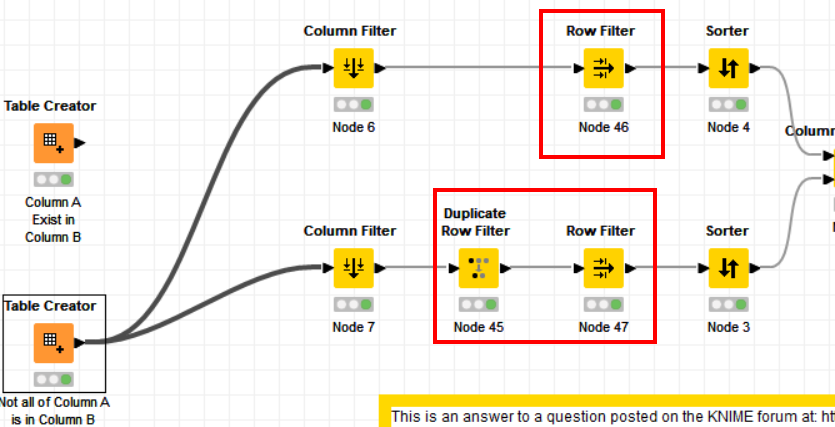
To avoid that, I think you would need to add a duplicate row filter on your lower branch and also remove “missing rows” with a row filter on both branches:
(all that said, I may be wrong in how we should treat missing values! Are they considered to be values in their own right, in which case my solution isn’t quite correct either as missing values don’t match in a joiner)