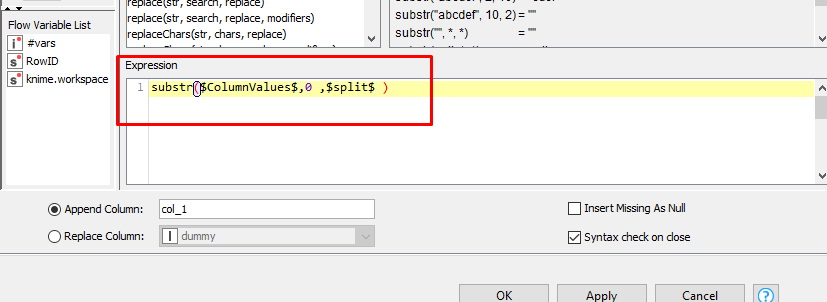
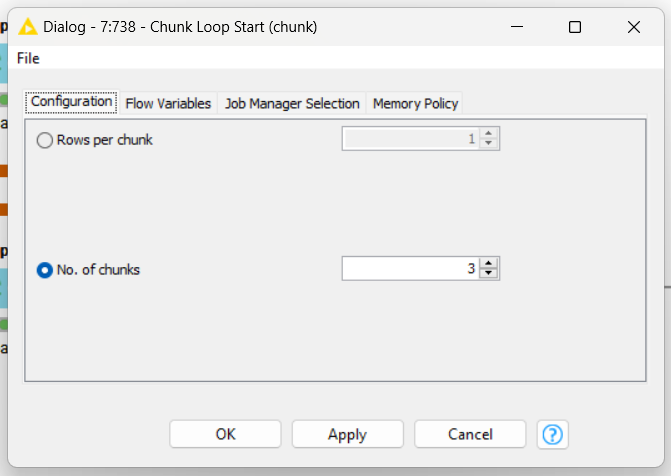
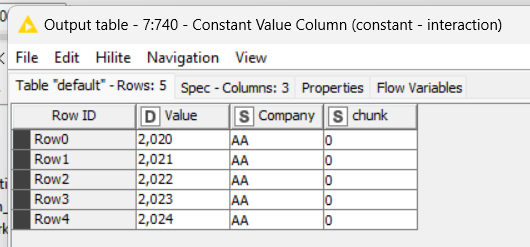
For me the Chunk Loop with Flow Variables behave strange. I expected that the loop reacts on every company (AA, BB, CC, DD and EE). However, it sitcks to 5 (#rows per chunk).
What I’m doing wrong?
Hopefully someone is able to help me reach the final situation (screenshot)
I saw the file and your flow and I have some doubts.
First, you can use the group loop start to separate company values. Each process can use a rule engine to set the split number to row or chunk options.
After that, I saw that you use a group node to concatenated all rows as one value column. Then you used a split cell to break the information into columns, that’s it you need?
thnx for you fast feedback. Yes, your input gives me a great new insight how to solve my problem.
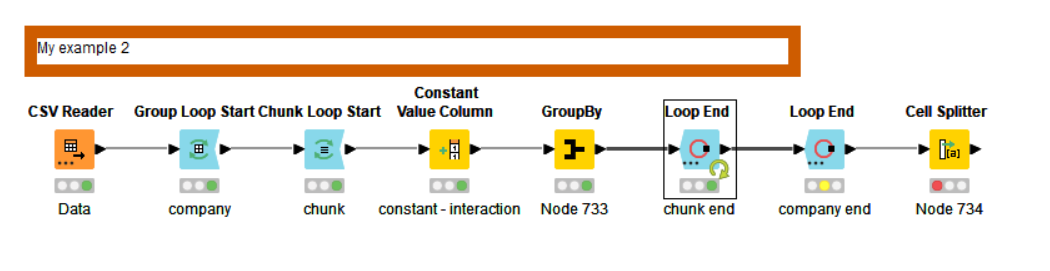
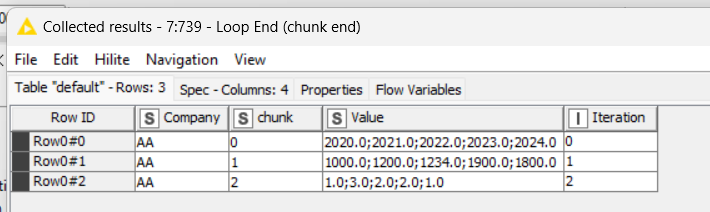
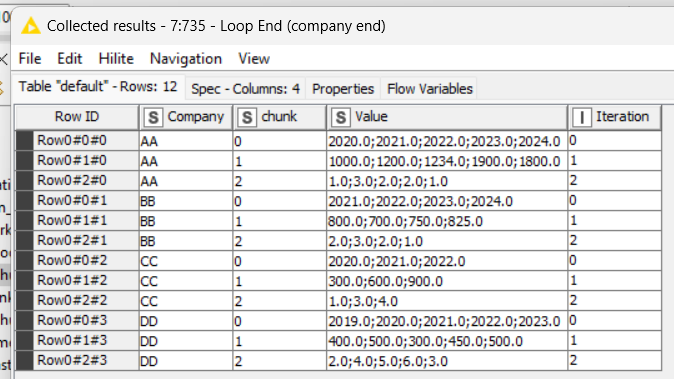
The reason I developed the flow as I did was that I need per Company 3 subgroups (in the real world there will be 50+ subgroups). See screenshot beneath.
Via String Manipulation you can split the first subgroup but with 50+ subgroups that’s not handy
FYI . . . the structure within each row is fixed (e.g. row1 5 times a value for each subgroup). But rows differ so row2 consists of 3 times a value for each subgroup.
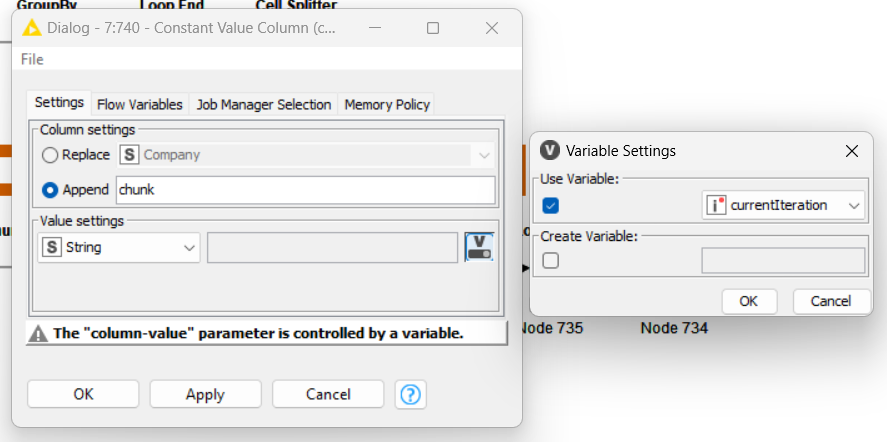
Therefore I thought earlier about Chunk in combination with Flow Variable.
So, do you or anyone else have an additional suggestion for my problem.
1- Company “AA” have 21 values, if split as chunk group by 3, you 'll have 7 values each one, right? Company “BB” have 10 values, 1 group will have 4 values and the others will be with 3 values… so go on…
My suggest here is to set a value using the interaction value from the loop to set these silos (1,2,3).
2- Other tip is remove duplicated rows… If you don’t need it, just unique values, before all of it, use a reme duplicate rows ou when you are grouping information, see if its necessary too.
many thnx for your help . . . it works !!!
Earlier I thought like your solution about a nested loop with unfortunately lacked the overview.
I learned a lot from you . . . muchas gracias
But now I’m struggling with the classical problem that the dataset is not so clean as promised