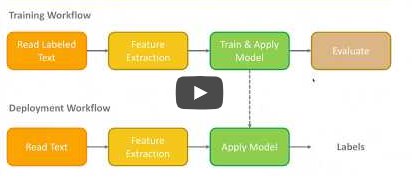
I am trying to execute the sentiment analysis through KNIME. I was able to find few readily available workflow to carryout sentiment analysis, however, my doubt it appears that these samples seemed to be available for the dataset which already have labels in it. How can I use these models on a new dataset which does not have a label in it (i.e. as Positive or Negative)?
I came across a KNIME webinar in which it is being discussed about deployment of a trained model for the dataset without labels.
Can someone help how can I extend the attached workflow for deployment?
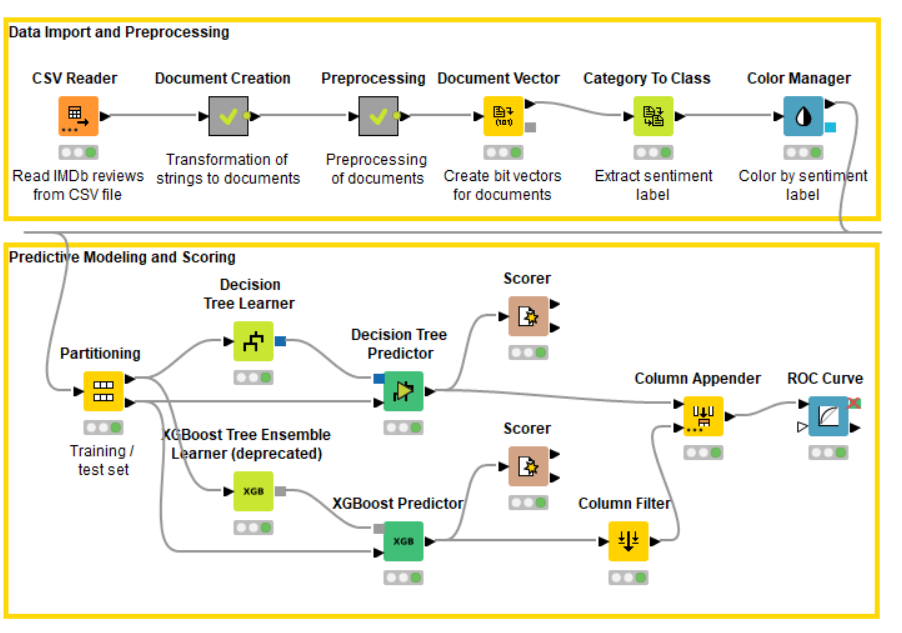
You might find this workflow more applicable for what you’re trying to do:
This uses a partitioning node to split into two branches - one for training a model, and one for applying the model to unseen data. You could adapt this WF to use unlabeled data in the bottom branch - the key to doing so is correct use of the Document Vector Applier node as shown. Of course you won’t be able to do any of the usual scoring on unlabeled data.
Once this makes sense to you, you could experiment with splitting this WF into two separate WFs - one for model training, and one for model application. In this case, this would involve use of Model Reader and Model Writer nodes for both the Document Vector and Decision Tree Learner nodes - writers in the training WF, and readers in the application WF. You can see an example of a WF for application only using REST API inputs here:
Eventually you could move on to Integrated Deployment, if you’re feeling adventurous.
Thanks @ScottF for sharing a detailed insights on my query.
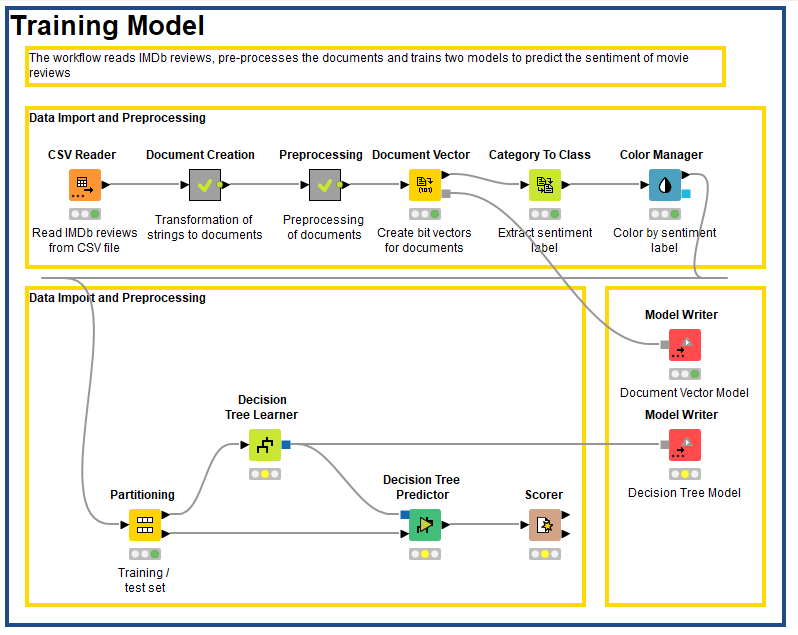
I tried to follow the steps proposed by you, however, there is a slight doubt that I have encountered. In order to use Document Vector Applier node I had to export model from the training set of Document Vector too and then again from Decision Tree Leaner Node for the final output of the trained model.
Using which I tried to predict the texts without considering any labels, i.e. by using Model reader in the appropriate section.
I just want you to verify and let me know whether my approach is correct. Can you please have a look at the attached screenshot of workflow which I created as per above explanations?