Hello good afternoon, I present the following query:
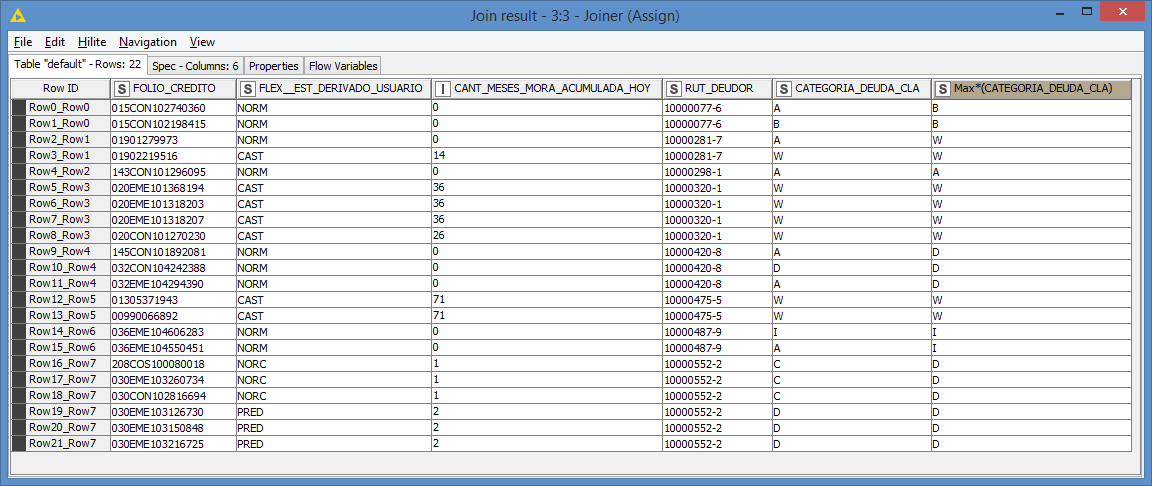
I have a column called “CATEGORIA_DEUDA_CLA” which is ordered according to the level of risk where the letter A is the best classification and the letter W is the worst classification, the composition of the field is the letters A, B, C, D, E , F, G, H, I, W.
Likewise, I present a field called “RUT_DEUDOR” which in my workflow is ordered in ascending order and presents duplicate values (which is correct that it is like this).
What I need is to register a new column which allows me to register for each row of the field “RUT_DEUDOR” the worst classification associated with the field called “CATEGORIA_DEUDA_CLA”
Example:
-
“RUT_DEUDOR”: 10000077-6 presents two classifications A and B, I need the letter B to be entered for both records
-
“RUT_DEUDOR”: 10000281-7 presents two classifications A and W, I need the letter W to be entered for both records
-
“RUT_DEUDOR”: 10000320-1 has the same classification, therefore the letter W must be kept

Finally, an example base is attached with some cases and how it should look (highlighted in the yellow column)
Libro1.xlsx (11.3 KB)