I was wondering what the underlying algorithm/configuration for extracting clusters in the keygraph keyword extractor node is? How exactly does KNIME define “the top |HF|-1 associations” as it says in the description?
I prepared a small sample document and tried to verify the results in KNIME by a manual calculation. I compared everything from the number of words, frequency of words, co-occurrences of words; every number in KNIME coincides with the results I achieve by manual calculation. Yet KNIME calculates 7 clusters based on it and I cannot seem to figure out the algorithm behind it.
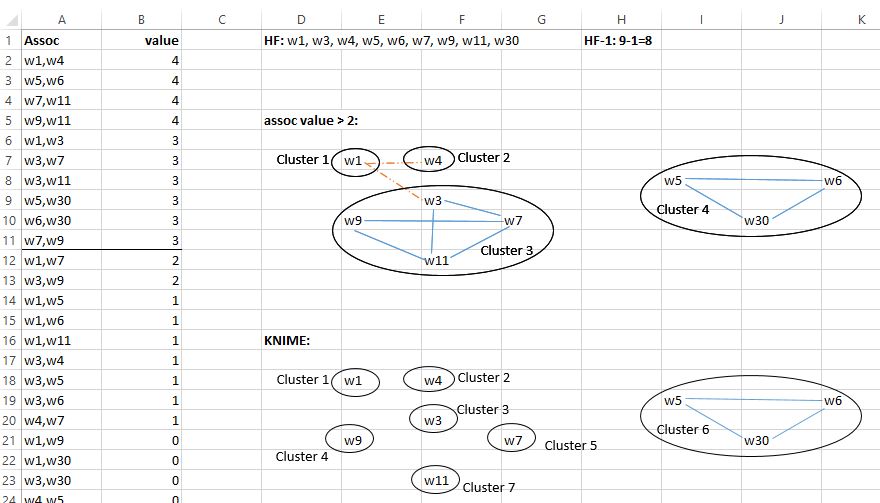
I used 9 high frequency terms. If I chose the highest assoc values (here assoc value of 4) as edges there are no clusters (or rather every word forms a cluster by themselves). If I include also the ones with an assoc value of 3 or even less, I do not receive 7 clusters even if I prune the path between those terms which are only connected in one way.
It seems that KNIME randomly chose a cutoff which assocs to consider as edges and which not?
at first the X highest frequent (HF) terms are calculated and added to an undirected graph G.
In the next step edges between all HF terms are generated. The weight of an edge between two terms n1 and n2 is the sum of the minimal frequencies of the two terms within each sentence of a document. The |HF|-1 edges with the highest weights are added to the graph.
Afterwards, each edge e that is considered as the only connection of the two incident nodes/terms n1 and n2 are removed. In other words, an edge e is removed if there is no other path between n1 and n2 in the graph G - e.
After pruning these edges, a set of all of the graphs connected subgraphs is extracted and considered as concept clusters. Based on these clusters, scores are calculated to retrieve the top Y key terms that are added as nodes to the graph.
Then for each high key term, all edge weights between the high key term and all high frequency term are calculated and the one with the highest weight is added to the graph.
In the end a score for every single node in the graph is calculated.
The Keygraph Keyword Extractor Node then returns the Z top keywords.
X, Y, Z can be set in the node dialog.
I hope this helps. Otherwise feel free to ask.
Cheers,
Julian
PS: The node is based on the approach described in this paper.
I am still struggling to understand on what grounds KNIME calculate the clusters. I run a small sample document and have the following values/weights for all the edges between the nine HF terms (see screenshot).
What does “The |HF|-1 edges with the highest weights are added to the graph” now mean? That the first (HF=9) 8 highest values are added as edges? If that is the case, what are the highest eight if the values are the same?
Or as the paper says “number of nodes in G – 1th tightest association are represented in G” which would mean in this case 9-4=5 ; all values above 5 which would be, however, none in this case?
If I chose the highest values (which is in this case 3 and 4), I come up with four clusters.
If I just chose 4 as the highest value, there are 9 clusters.
If I am supposed to choose only the eight highest values I do not know which of the assoc values of 3 to include and which not?
KNIME calculates 7 clusters and I cannot seem to figure out why…