Hello.
I have been ding some exersizes with knime cluster analys and encontered with one issue.
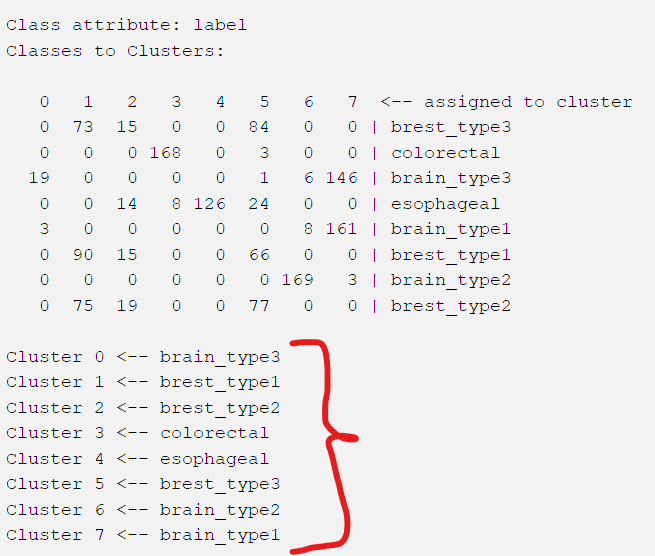
I have 8 labeled types of disease and 20k features (float drype aka D) and 1000 samples(patient). I use k-means node. I recived 8 clusters but I don’t know what type of disease KNIME assign to each cluster.
for example:
Cluster_0 , 1, 4 , 5,…
Cluster_1 , 2, 4 , 7…
I try to use column appender after k-means node but I suppose it’s wrong because the score is unrealistic.
In other words I would like something what call in WEKA software “Classes for claster evaluation”
Which node distinctly assign label?
Like that:
Cluster_0 to disease_5
Cluster_1 to disease_6
Hi
How is that working in WEKA? I would assume more diseases are matched to one cluster so how could you assign a distinct label to it?
I could only imagine mapping the disease column back (if same order column appender node could be used, then do a groupby cluster and concatenate / create a set of disease names for each cluster with the groupby node
br
The problem is that I dont know which cluster Knime choose internaly. Also if I label (brain_type3 for Cluster_0 in Knime, the score is almost 0, because it is wrong association, but it is work for Weka