Dear Vladimir,
Sorry for the delay.
Regarding your dataset and the question, I assumed that “the most” here means the most amount of purchase which is the total money paid by the customer.
Now, the first thing you can do is to find the top shop in “amount” value. Just to specify the top shop for each customer.
But to answer the question, you have to check which attribute(s) has the most impact on “amount”. By “amount” I mean the 5 columns named “amount_purchased_shop_#”.
So, I did some aggregations to find out what makes customer to buy from a shop more. The only available variable here to investigate is the distance. But when I checked this variable, found out that the distance to shop itself has nothing to do with the amount a customer buys. Why? Because although 60% of the customers has the shop 1 as the top shop in amount, only 3% of them have the shop 1 as the nearest shop to them.
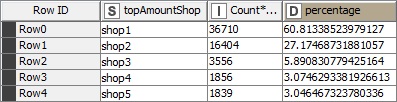
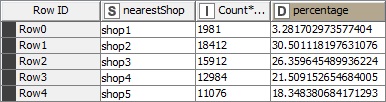
The sum of the amount sold in each shop is almost the same as the top amount for each customer:
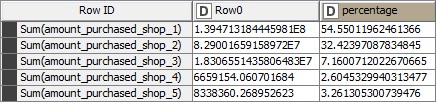
And as you see the sum of distances to each shop does not have a significant difference:
Now the question is why people buy the most from the shop which is not the nearest?
Perhaps the reasons are: Being the first store in the chain (more reputation), being the biggest one (more available products) and being in the city center (the least avg distance).
From the shop numbers in the dataset we can infer that which shop was operational sooner and has more reputation (more reputation = more amount). So the first shop in the chain is the shop 1. Even if this assumption is wrong, it does not matter since we just relate the shop number to the amount sold based on dataset. So one attribute can be the shop number, but although this number has the order (the shop 1 is higher than shop 2 and so on), it does not have the distance. Here we can convert the amount to shop number so the distance can be measured as well as the order.
The shop size or available products cannot be inferred from the dataset (maybe the unique product has some meaning related to this but I do not trust that). So the second attribute (how big a shop is) has nothing to do here.
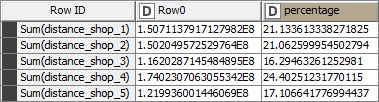
Now the third one. Being in the city center or let me say it in a better way, being the nearest to the customers in average. Here we can calculate the distance to the average distance which somehow makes sense regarding the results:
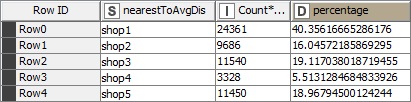
First, I have calculated the difference between the distance to each shop and the average distance and then selected the least one as the “nearest to average distance”. As you can see, the most percentage of customers (40%) have the shop one the nearest shop to the their average distance.
I also calculated the sum of this distance for all the shops:
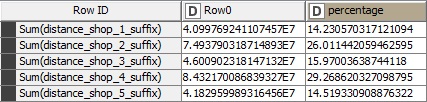
As expected, the shop 1 has the least total distance to the average distance. The shop 5 is in the second place which makes me infer that perhaps the shop 5 is also somewhere near the city center.
As a conclusion, I think you can use the two available attributes I discussed here (the first and the third one) to cluster the customers.
I suggest using XMeans and Weka Cluster Assigner for clustering because it’s easier to deal with the number of clusters.
I also built a decision tree model based on these attributes and got a very good evaluation score.
I do not provide any workflow since it’s your course project. But all the information you need is provided.
I hope this would be helpful.
Best,
Armin