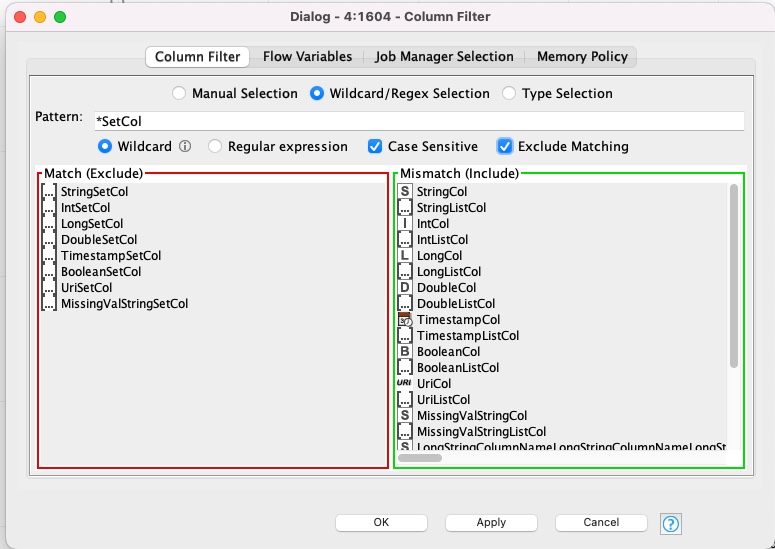
the Exclude/Invert Option, available only when filtering via Wildcard/RegEx, would be a nice addition for the Type Selection filter, wouldn’t it? It would make the experience also more consistent.
One of the best ways to accomplish exclusive type filtering for columns in KNIME Analytics Platform 4.6.x would be to use the Column Splitter node. You can use the type selection normally and then pick the second output to get the excluded columns.
Alternatively, you could simply invert your selections in the config dialog so that List and Set types are excluded.
Thanks a lot for circling back to me. Unfortunately, both the Column Filter and Column Splitter suffer form the same feature gap.
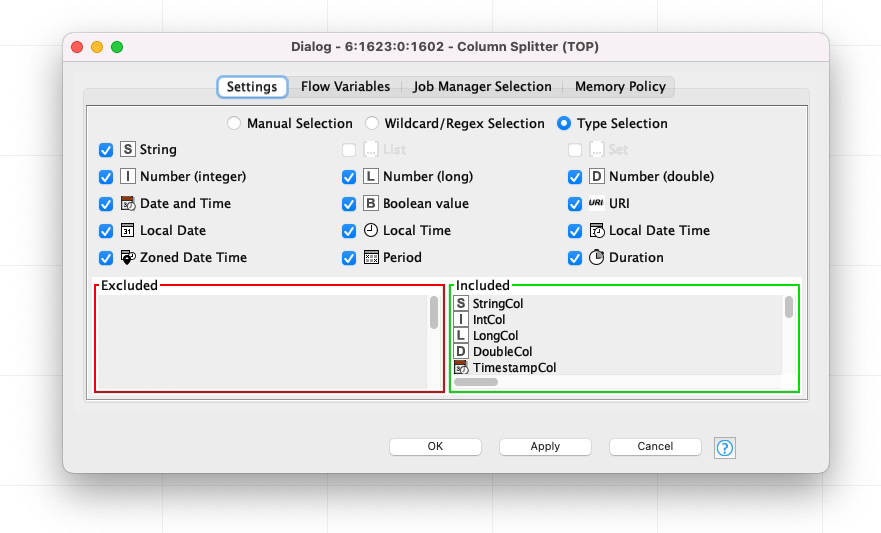
I also happen to recognize that the interface is quite difficult to use as the presence and order of filter options vary based on the input. They are also not sorted alphabetically or by type class (e.g.: Time, Date/Time, Duration etc. vs. String vs. Int/Double/Long vs. URI etc.) and the labels are not clickable which makes hitting the checkbox a bit of a challenge. My finge suffers from imminent fatigue syndrome from the many clicks
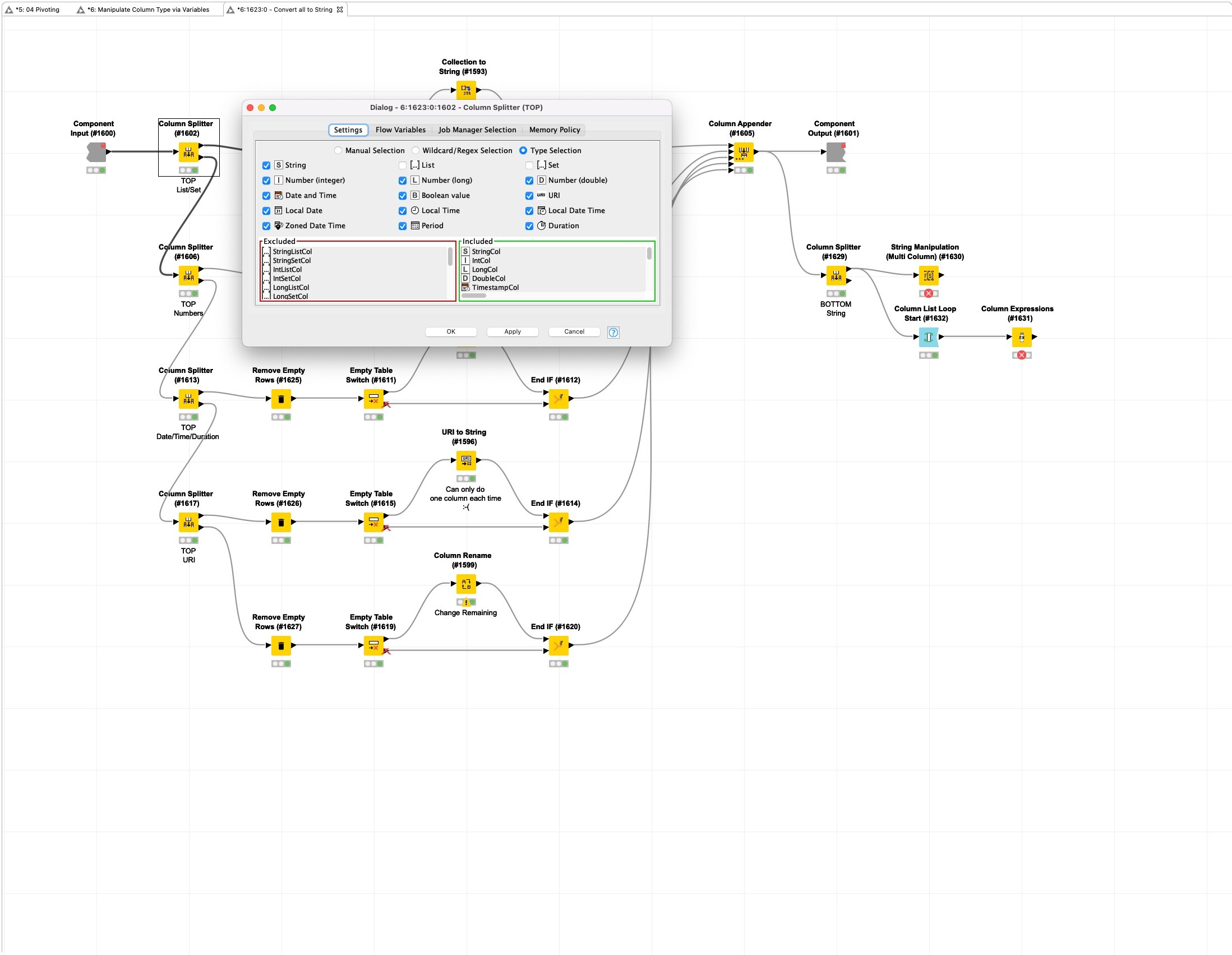
To give a bit more background to my suggestion. As you see in this example I want to work with the list/set columns only.
The problem is, if I click these, they will be present on the bottom port. In case I want to process the other (not list/set) columns I have to align nodes in an odd way so the connections do cross cluttering the workflow design. Can you follow me?
For consistency reasons, which would improve orientation but also would allow to immediately recognize these data types are not available (further improving orientation), I’d propose to always display all options but disable unavailable ones like so:
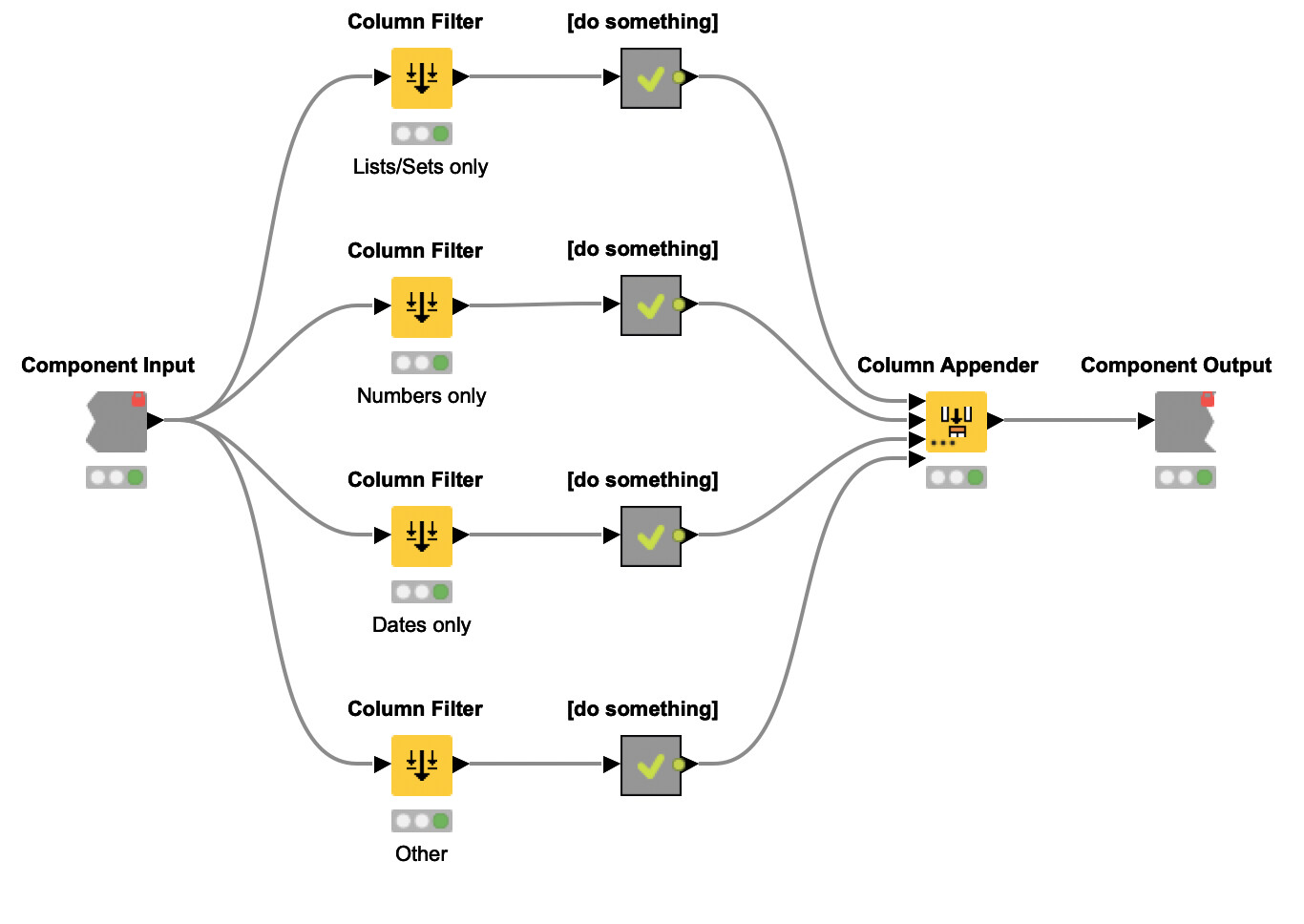
Based on your workflow screenshots, it looks like you are attempting to create a component which processes a table input. The table input may contain columns of several types, and you’d like to process each data type separately and then combine the results back into a single table.
If I understand correctly, then shouldn’t the approach below work fine?
within that screenshot I merely huddled it together and found many aspects of that UX rather inconvenient. Especially when comparing to the neat exclude option to easily invert a selection (1 click vs. many).
About your proposal. Yes, that might suit the purpose but if you imaging a billion cells across hundreds of columns, that level of parallelization can easily choke your system. Sometimes you also want a gradual / iterative data reduction too.
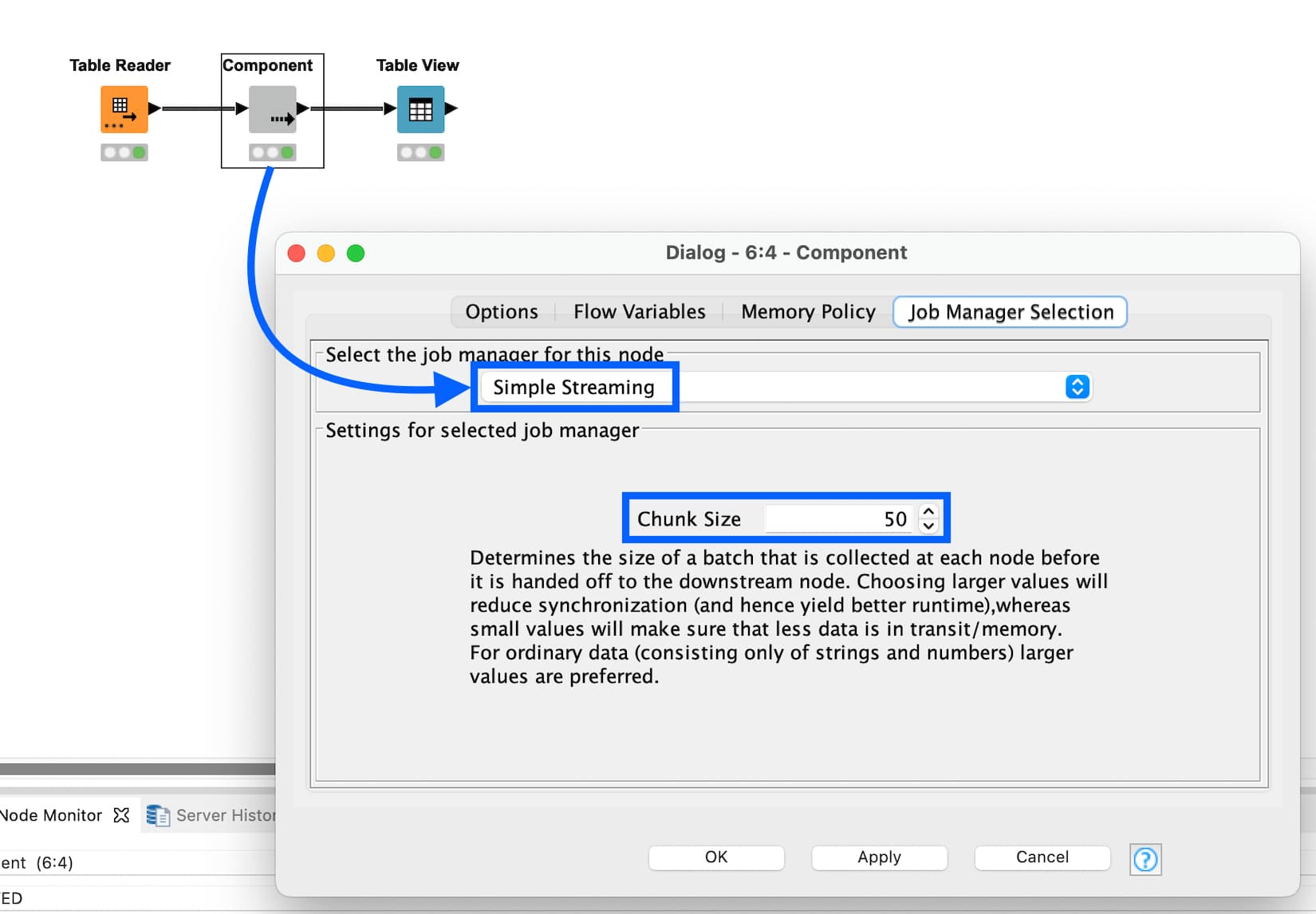
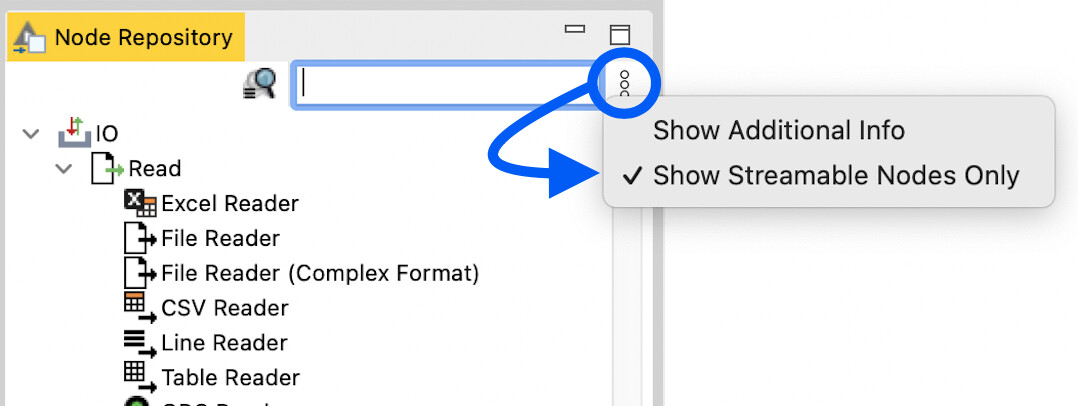
It’s worth mentioning that the streaming extension is compatible with a subset of all available nodes - in particular, our native nodes are typically safe to use. You can filter the Node Repository to only show streamable nodes if desired.