Dear Knimers,
Please need help on getting a workflow for the below scenarion
Input:
| Level | Grouping |
|---|---|
| 1 | A,B,C,D |
| 2 | E,F,G,H,B,D,E,F |
| 3 | I,J,K,L |
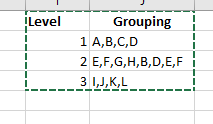
Expecting Output:

| Level | Grouping | Grouping | ||
|---|---|---|---|---|
| 1 | A | B | ||
| C | D | |||
| 2 | E | F | B | D |
| G | H | E | F | |
| 3 | I | J | ||
| K | L |
Thanks in Advance!
Dear Knimers,
Please need help on getting a workflow for the below scenarion
Input:
| Level | Grouping |
|---|---|
| 1 | A,B,C,D |
| 2 | E,F,G,H,B,D,E,F |
| 3 | I,J,K,L |
Expecting Output:
| Level | Grouping | Grouping | ||
|---|---|---|---|---|
| 1 | A | B | ||
| C | D | |||
| 2 | E | F | B | D |
| G | H | E | F | |
| 3 | I | J | ||
| K | L |
Thanks in Advance!
Hi @Pragadeshgp , can you please explain the logic as I do not want to wrongly assume what the logic should be?
My guess is that the grouping is done in 2 rows? Based on this guess:
1- Are there always an even number of elements?
2- In the event that there are not always an even number of elements, should the +1 be on the first row or the second row?
3- Any reason why your headers “Grouping” span on 2 columns? Are these 2 columns supposed to be 1 column? (Meaning B+C = 1 column, and D+E = 1 column?)
Thank you @bruno29a for your response
1 - No it will me mixed
2- It doen’t mater, mainly 4 words should be in one block
3 - ‘Grouping’ is just a column name, Expected output is mainly organizing the set of letters properly…
A,B,C,D in a group…4 seprate letters forms a group.
Hi @Pragadeshgp , thank you for the additional information.
So, it looks like my assumption of grouping in 2 rows was wrong. It’s essentially a group of maximum of 4. What I need to know is how do you define how a “block” should look like in Knime. Is a “block” essentially a cell? Or is a “block” a 2x2 block of cells (meaning 4 cells)?
“block” a 2x2 block of cells (meaning 4 cells) this is better.
@bruno29a anyluck on my scenrio?
Hi @Pragadeshgp , I’ve been busy with work and I’ve not had a chance to take a shot at it yet.
Does the order of the elements matter when putting them in the blocks? If it does not matter, then this can be translated almost as putting the data in 2 rows, which is a much easier task to do.
EDIT: To illustrate what I mean, for row 2 for example, is it OK if the result is like this:
|Level|Grouping|Grouping|
| 2|E |F |G |H |
| |B |D |E |F |
@bruno29a thanks for your response
Please share me a workflow for this for below example
|Level|Grouping|Grouping|
| 2|E |F |G |H |
| |B |D |E |F |
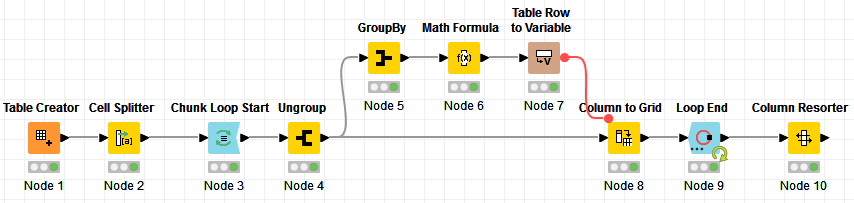
Hi @Pragadeshgp , sure, basically the trick to move the list into 2 rows is to use the Column to Grid node. This node allows you to specify the width of the grid, so you can dynamically set that width based on the number of elements in the list.
For each row, the grid should have a minimum of 2 columns as width, and increments by 2 columns to adjust to the size of the list.
For example, if you have:
2 elements - 2 columns in the grid
3 elements - 2 columns in the grid
6 elements - 4 columns in the grid
I use the formula of: ceil(ceil(number_of_elements / 2)/4) * 4 to determine the width of the grid. The grid will add the second row automatically.
Here’s 1 way to do this:
Input data:
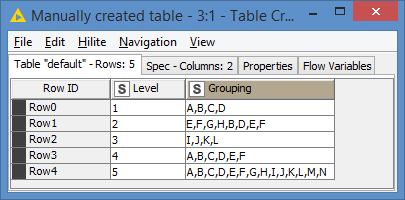
1-3 are your use cases. I added 2 more use cases to see the behaviours for various list size:
Use case #4 has 6 elements.
Use case #5 has 14 elements.
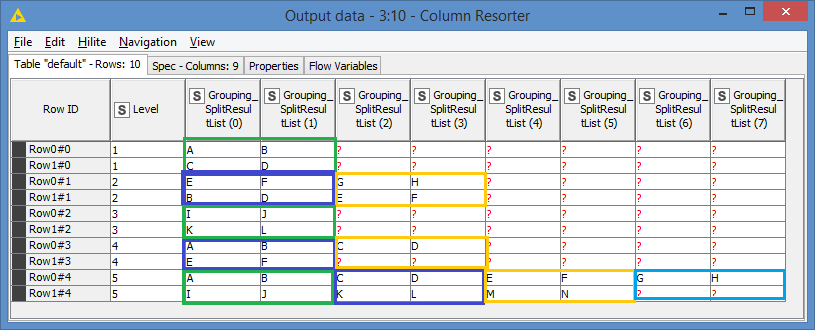
Results:
As you can see, it split the grouping into blocks of 2x2.
Note about the formula: The reason why I’m doing ceil(... /4) * 4 is to prioritize horizontally if you have 6, 10, 14, 18, etc elements, basically the number of elements that’s in between multiples of 4.
For example, if we look at Use Case #4, which has 6 elements, if I do not add this formula and stick with ceil(number_of_elements / 2) only, the output will be:
| 2 | A | B | C | |
| 2 | D | E | F | |
With the added formula, I get:
| 2 | A | B | C | D |
| 2 | E | F | | |
Here’s the workflow:
Thank you @bruno29a will check this workflow and update you!
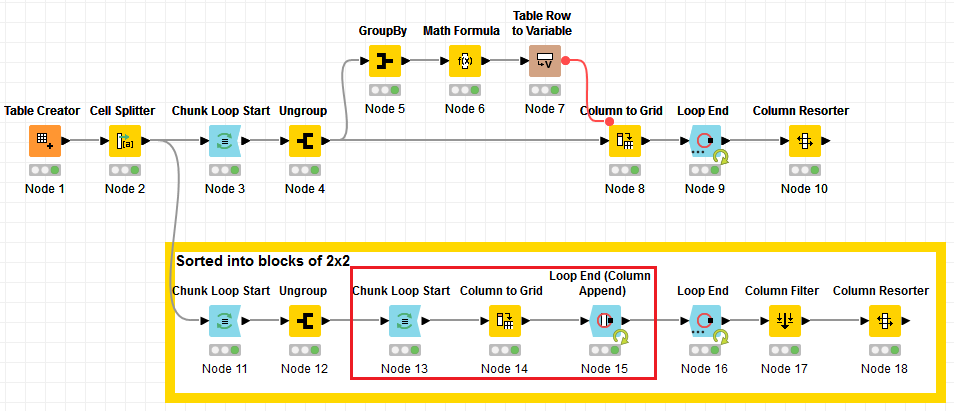
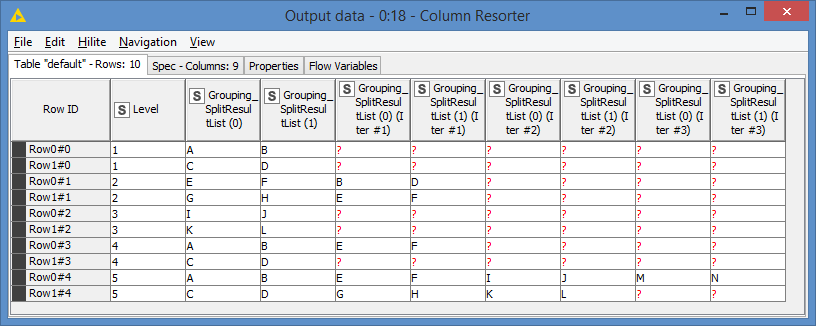
Hi @Pragadeshgp , I modified the workflow so that it will sort the way that you wanted.
The main difference is that I simply need to take chunks of 4 elements at a time, that way the grid will be built with the values in the chunk.
Results:
I have re-uploaded the workflow with the updates:
@bruno29a great
Thank you a lot !
it worked
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.